


As part of a Snowflake Cortex AI workshop, we were challenged to build a chatbot from a dataset of our choosing. The goal was to take structured data, create a semantic model, build an AI agent on top of it, and then deploy the finished solution as a Streamlit application.
Being a Formula 1 fan, I decided to build a chatbot that would allow users to explore Formula 1 history using natural language. Rather than writing SQL queries to get answers from the dataset, users could simply ask questions such as "Who won the 2018 Belgian Grand Prix?", "Was it raining during the 2022 British Grand Prix?", or "Compare Lewis Hamilton and Michael Schumacher fairly across eras."
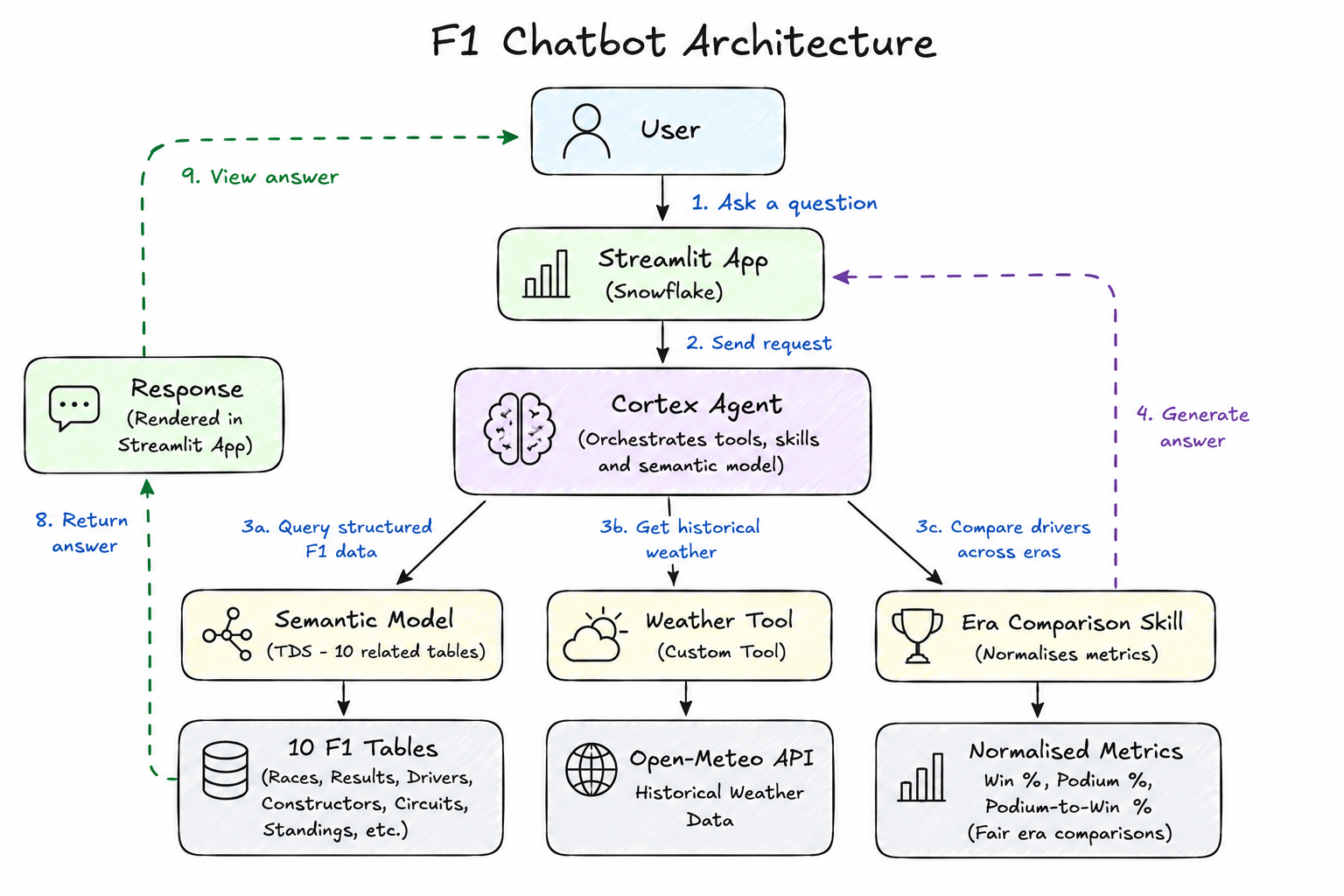
User questions are sent through a Streamlit application to a Cortex Agent, which can query Formula 1 data, retrieve historical weather information, and apply custom skill logic before returning a response.
Choosing the Dataset
The dataset contained historical Formula 1 information covering drivers, constructors, circuits, races, results, championships, and other related data. Rather than working with a single table, I wanted the chatbot to be able to answer more complex questions, so I built the semantic model using ten related tables.
This allowed users to explore race winners, championship battles, driver careers, constructor performance, and circuit history through natural conversation rather than SQL queries. The agent translates these questions into database queries behind the scenes before returning the results in plain English.
Building the Semantic Model
The semantic model acts as the layer between the large language model and the underlying database. It defines the meaning of the data, describes measures and dimensions, and explains how the tables relate to one another.
A large part of the project involved refining this model so that the agent could consistently interpret Formula 1 terminology. Drivers, teams, circuits, championships, and race results all needed to be described clearly enough that the agent could generate accurate SQL queries behind the scenes.
Once the model was in place, I spent time testing questions in the playground, identifying where the model struggled, and making adjustments until it could reliably answer a range of Formula 1 questions. The end result was a chatbot capable of understanding Formula 1 terminology and translating natural language questions into SQL queries automatically.
Extending the Agent with Weather Data
One thing the dataset did not contain was weather information.
To make the chatbot more interesting, I created a custom weather tool that connected to the Open-Meteo API. This allowed the agent to retrieve historical weather information for a specific race location and date.
As a result, users could ask questions such as:
- What was the weather like during the 2022 British Grand Prix?
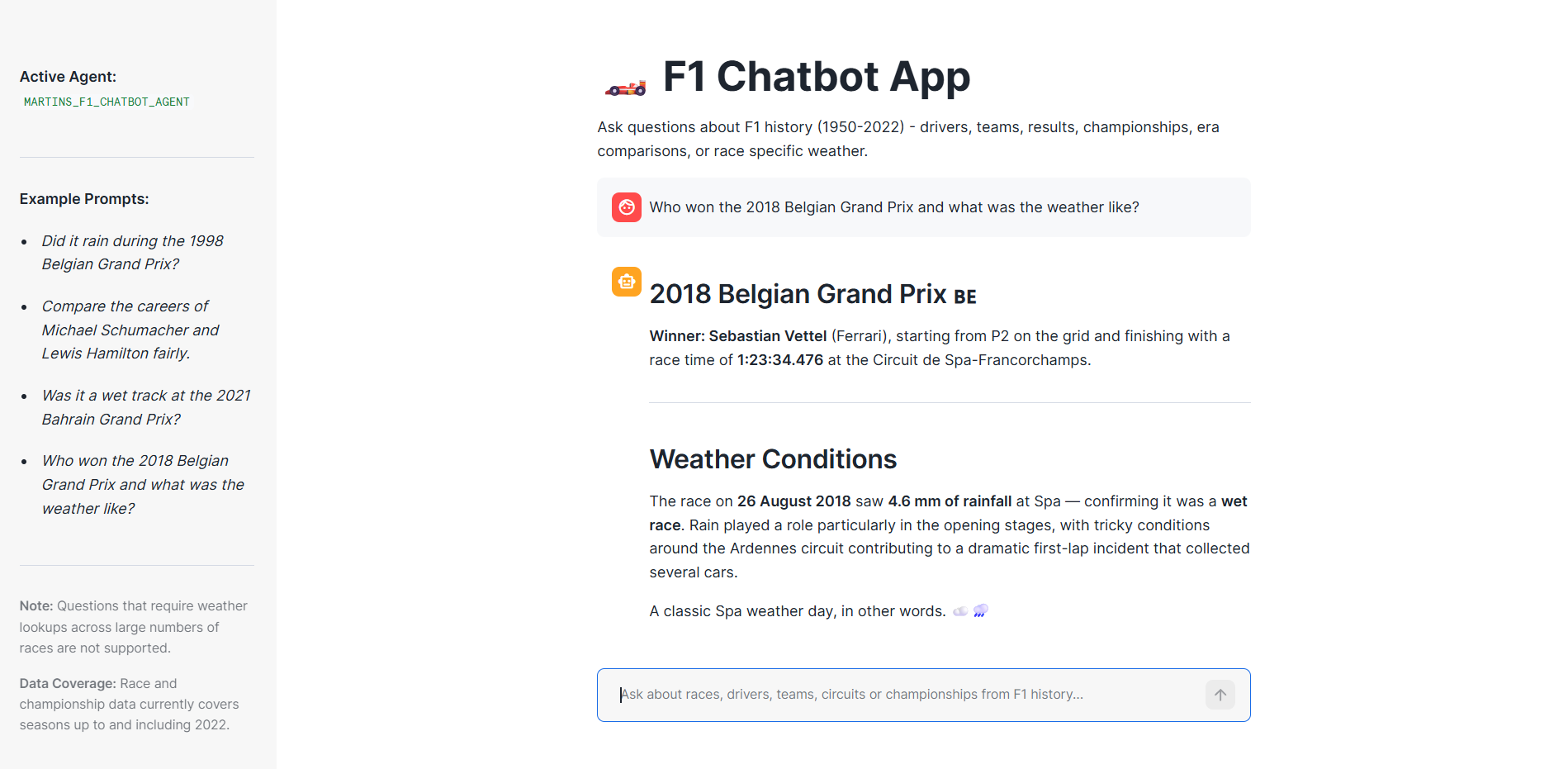
- Who won the 2018 Belgian Grand Prix and what was the weather like?
Adding an external tool demonstrated one of the strengths of Cortex Agents. The agent was no longer limited to the data already stored in Snowflake and could combine information from multiple sources when answering questions.
Teaching the Agent to Compare Drivers Across Eras
One of the most interesting challenges was handling comparisons between drivers from different generations of Formula 1.
Questions such as "Who is the greatest driver of all time?" are surprisingly difficult to answer fairly. While it might be tempting to compare drivers using career points totals, Formula 1's points systems have changed significantly over the years. Different numbers of points have been awarded for race positions, and points have been awarded to different numbers of finishing positions depending on the era.
To solve this, I created a custom skill that activates when users ask for all-time rankings, "GOAT" discussions, or comparisons between drivers from different periods of Formula 1 history.
Instead of relying on raw points, the skill retrieves career wins, podiums, and race starts for each driver and calculates a set of normalised metrics:
- Win Efficiency % (wins divided by race starts)
- Podium Finish % (podiums divided by race starts)
- Podium-to-Win Conversion Rate (wins divided by podiums)
These metrics provide a fairer comparison of performance across different eras and help avoid some of the biases introduced by changing points systems. The agent also explains why these measures are being used, helping users understand the limitations of traditional statistics when comparing drivers from different generations.
This was a good example of how Cortex Agent skills can be used to introduce domain-specific knowledge and reasoning, rather than simply retrieving data from a database.
Adding Guardrails
Another important part of the project was deciding what the chatbot should not do. Because weather lookups required external API calls, questions that would require weather checks across hundreds of races could quickly become expensive and inefficient. To prevent this, I added guardrails that restrict large-scale weather analysis. As a result, questions such as "Who is the greatest wet weather driver in F1 history?" are intentionally declined, since answering them would require sending API calls to check the weather for every race in the dataset.
I also added instructions to prevent the agent from answering questions using its own general knowledge when the data was unavailable. The Formula 1 dataset only covered seasons up to 2022, so if a user asked about a race from 2024, the chatbot would explain the limitation rather than generating an answer from outside the dataset.
Deploying the Chatbot
Once the agent was working reliably, the final stage was deploying it as a Streamlit application inside Snowflake.
The application provides a simple chat interface where users can ask questions in natural conversational language about Formula 1 history. Behind the scenes, the app sends requests to the Cortex Agent, which determines whether it needs to query the Formula 1 dataset, call the weather tool, or combine information from both sources before generating a response.
Final Thoughts
This project was a great introduction to Snowflake Cortex Agents and semantic models. It demonstrated how a structured relational dataset can be transformed into a conversational chatbot, allowing users to query data using everyday language rather than SQL. By removing the need to understand the underlying database structure, the chatbot makes historical analysis far more accessible to non-technical users.
By combining a semantic model built from ten related tables, a custom weather tool, a driver comparison skill, agent orchestration instructions, and a Streamlit front end, I was able to build a chatbot that goes beyond simple database querying and provides an easier and more interactive way to explore the data.