


Hello, everyone!
As promised, here is the second edition of my Alteryx tips’ series! We went through a whole lot of content today – as usual – but one workflow we went through this morning really stood out in my opinion: running a sentiment analysis on text. I’d read quite a few articles about this type of analysis in the past few months and never realized how simple it was to get done. That is if you have right the tools, and Alteryx is the perfect tool to get this done. That being said, let’s get right into it!
The Problem
Imagine you were interested in identifying the general emotions being expressed by the tweets of your favorite politician. After downloading the list of said tweets using the Twitter API, you sit idly in front of your computer, wondering how in hell you are ever going to get this done. Fear not! This will be surprisingly easy to accomplish. All we need to do is the following:
- Use the Alteryx Sentiment analysis macro to assign a sentiment score to each tweet based on the words they include.
- Process and organize the data stored in the tweets – the individual words – so as to remove unnecessary common words and obtain a compact, insightful dataset.
The dataset we will be utilizing for this case study contains a load of different tweets from customers about a store called Hobsons. Check it out below.

As you can see, it includes the full tweet in the Message column, as well as additional information regarding the person who wrote the tweet, and when it was posted.
Now that the stage has been set, let’s get started!
The Solution
In order to obtain a sentiment score for each tweet, and then organize our data in a way that will make it easy and useful to analyze in Tableau, we will be completing three different tasks:
- First, we will import our dataset with the tweets, obtain our sentiment scores, and parse out the tweets into individual words. We will, of course, organize all these words into a neat dataset.
- Second, we will import a dataset with a list of the English language’s most common words and run it through the Data Cleanser to prepare it for a join.
- Finally, we will conduct at left-join in order to remove all the unnecessary, common, English words from our tweet data.
- And voila, that’s it!
Before I reveal the workflow you’ll have to build to complete these steps, let’s explore some of the key concepts and tools you’ll be using
The Sentiment Analysis macro
A macro is nothing more than a set of tools that have already been linked together and prepped for you to use in order to accomplish a specific task. The Alteryx community is very active and people are regularly posting amazing macros that you can download for free!
What’s hidden inside the Sentiment macro then? Well, to be honest, I have no idea yet, but I wanted to share a picture of what the workflow behind it is. Take a look!
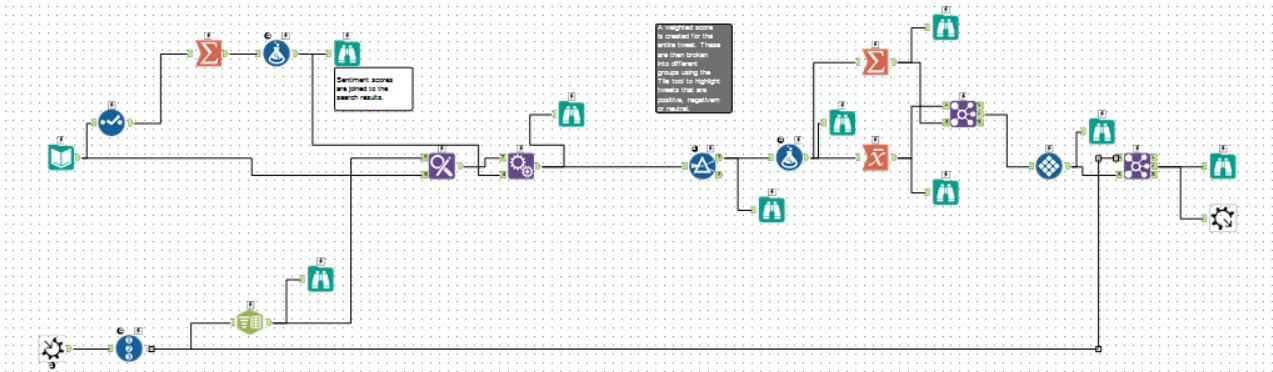
As you can see, it’s just a set of your standard tools linked together! Pretty impressive right?
So what output does running our dataset full of tweets provide? I’ve taken a screenshot for you!
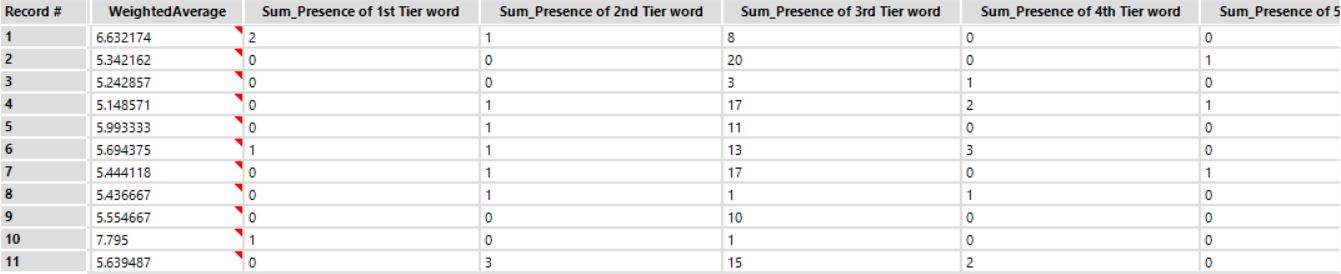
The only column we will be interested in is the leftmost one, WeightedAverage. The macro has just assigned each tweet a score based on how the words it includes fair in its built-in ranking system. Words like “love”, “adore”, “recommend” give you a higher score, while others like “complain” or “unfriendly” lower it.
Filtering out all common English words
Now, this step might have seemed a bit strange in my earlier explanation, but it’s really quite simple. Most of the words included in our tweets will be common words that do not express any feelings in themselves, such as “and”, “or”, “them”, etc, etc, etc. In order to make our final dataset as compact and useful as possible, it is imperative that we remove them. In order to do this, we will first have to import a dataset that contains a list of the most commonly used words. Once again, I’ve taken a screenshot so you can see what it looks like:
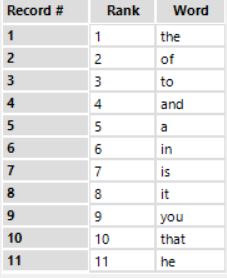
Pretty straightforward, right? With the help of this list of words, we will be able to remove all the useless elements from our final data set once we’ve parsed out the tweets.
With these two clarifications in mind, let’s take a look at the workflow you’ll have to build to complete to run your first text sentiment analysis!
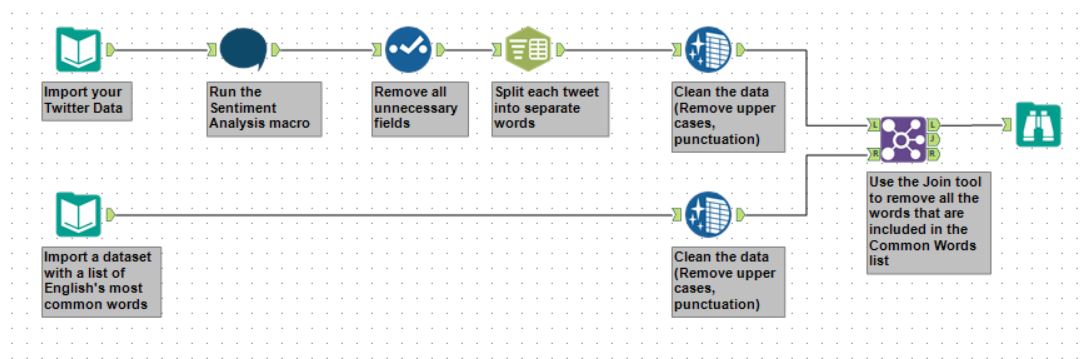
- In the top branch, we are first importing our data and running it through our macro to obtain our sentiment scores. Subsequently, we used the Select tool to remove unnecessary columns, Text to Column to parse out our tweets into individual words, and Data Cleanser to remove any upper-cases or punctuation in preparation for our join.
- In the bottom branch, we are simply importing our list of common words, and running it through the Data Cleanser to remove any upper-cases.
- Finally, we do a left join to remove any of the rows of data that include words that are in our list of most common words.
The final output we obtain looks like this:
