


Finally, I have got some time to sit down and write my thoughts down after making a lot of changes to my workflow to come up with a quite clean and sufficient dataset. This project is basically about data collection using API action from a Wikipedia site https://en.wikipedia.org/wiki/List_of_longest-reigning_monarchs.
I decided to go ahead with xml parse method instead of others such as json by chance. The way this data was constructed was far more complicated than I thought in the beginning. It was impossible for me to figure out a single unanimous Regex expression to capture all data of a single field. It seems like exceptions exist in all corners. As far as I am concerned, the only delimiter I could think of in this case is the row “\n” to escape new line. I intend to split the data into 3 tables corresponding to the ones in the site. I packed the workflow of each table in a different container in my workflow because they are different, though they might look similar to readers in the site :p
Monarchs of sovereign states with verifiable reigns by exact date

Monarchs of dependent or constituent states with verifiable reigns by exact date

Monarchs whose exact dates of rule are unknown
Then you’ve got to see how to filter only the important rows. Remember to pack the record ID tool within your step before cleansing the data because it will help you navigate where you were before. In this work, I use filter tool intensively to split the irregular behaved data apart then handle them separately before joining them back together with the rest.
The end table look something like this:
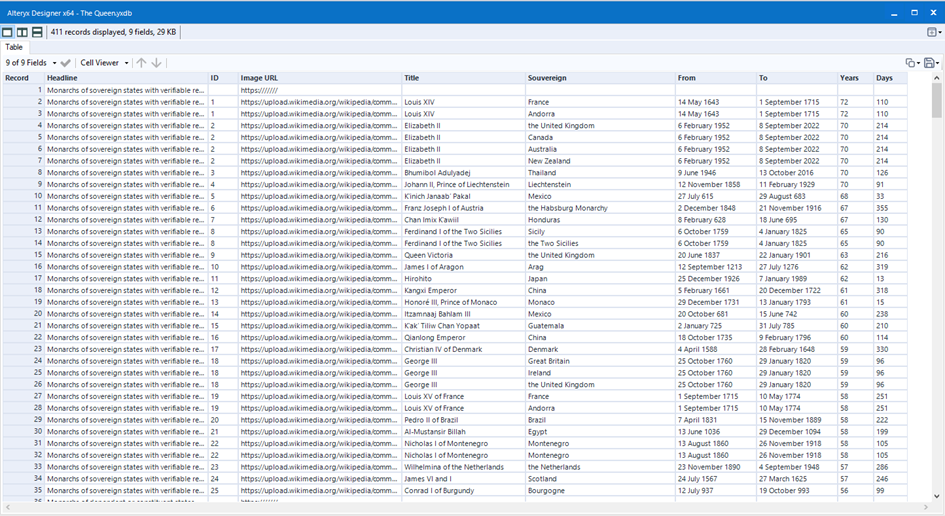
Along the way, there are lots of issues coming across such as URL for API changes ( I would recommend saving the uncleaned data somewhere in your local instead of calling it from the page every time you run the workflow, and same content but different formats. This is a great chance for me to practice Parsing Regex Skill especially better understanding the lazy (?) and greedy (+) quantifiers when it comes to tokenizing data.
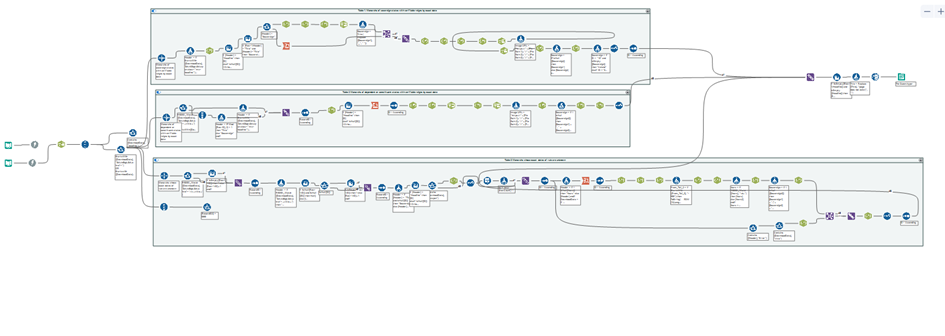
Bottom line: this project by far is the most significant API works I have ever created. I think that my workflow might be created in a more elegant and handy way by experienced specialists who have been doing it more regularly.
Fun fact: Alteryx doesn’t allow date type of data before the year 1400 AD (this issue occurs encountered in this case because there are quite a lot of Monarch whose reigns dated back hundred or thousand years before Christ.
Same issue happens in Tableau when you visualizes Data before the year 400 AD. But every issue has its own handy solution for it. That makes data analyst job mega fun. Stay tuned for my next visualization :D