


Leading football data provider Statsbomb periodically release free data to the public for football fans to dive in to and use for their own analysis and personal projects. Free data releases are often related to recent tournaments, for example 2024 AFCON or the 2023 Women's World Cup. The data is stored as JSON files on a Statsbomb GitHub repository. This blog will explain how to access, clean and prepare the data using Alteryx using the 2024 Copa America data as an example.
List relevant match IDs
Go to Statsbomb's open-data repository and open the file competitions.json. This file contains high level information about all of the competitions for which Statsbomb have made their data available, and crucially their competition IDs. We are interested in Copa America 2024, and the simplest way to find the competition ID is to Ctrl + F and search for "Copa America" and note down the corresponding competition_id value of 223.
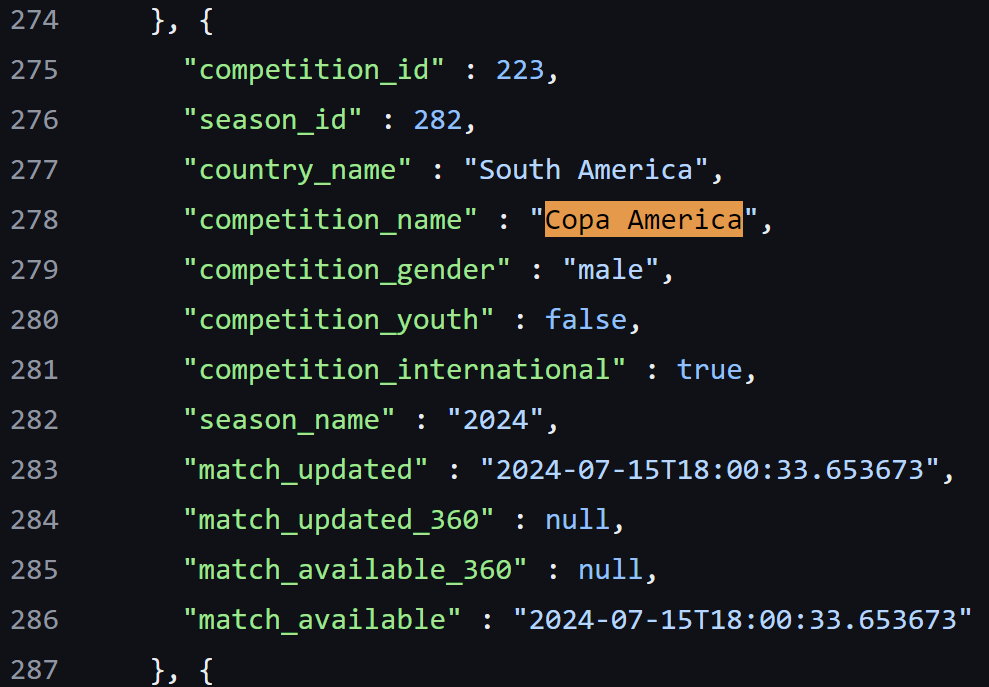
Take that competition ID to matches folder 223.json to find the match ID of all 2024 Copa America matches.
Now go to the matches folder. This folder contains high level information for each individual match grouped by competition and season and are named after their competition and season ID. Navigate to the folder named after the corresponding competition ID for Copa America of 223, within will be a JSON file named 282 which corresponds to the season_id of the competition (of which there is only one, 2024). Select 282.json and click on the "Raw" button in the top right corner of the code. This will open a new browser tab containing only the JSON format data.
Copy the URL of this new browser tab and open Alteryx. We will now use this JSON data to extract a list of the match_id's for each match of the 2024 Copa America.
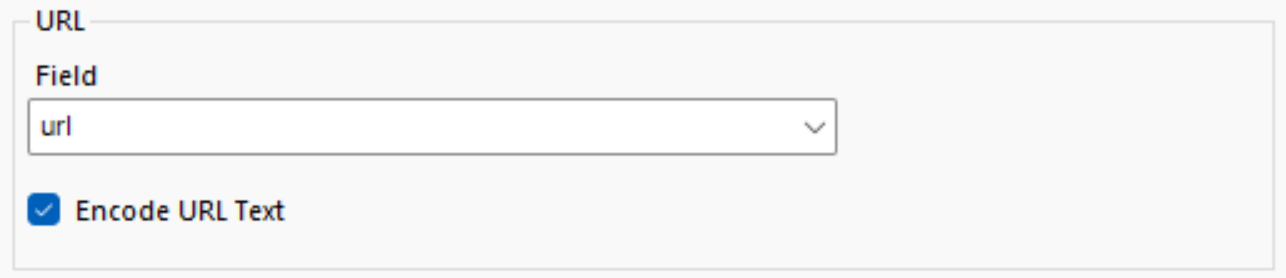
- Using a Text Input tool paste the raw GitHub URL into a new column named url

- Use a Download Data tool to specify that this URL is where we want to take data from
- Parse the JSON format data using a combination of a JSON Parse and Text to Columns tools
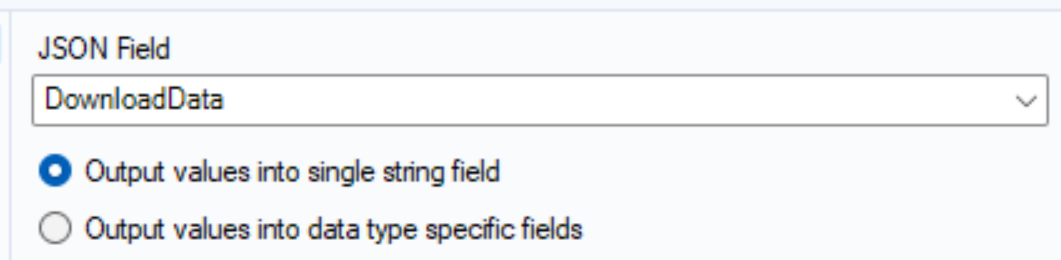
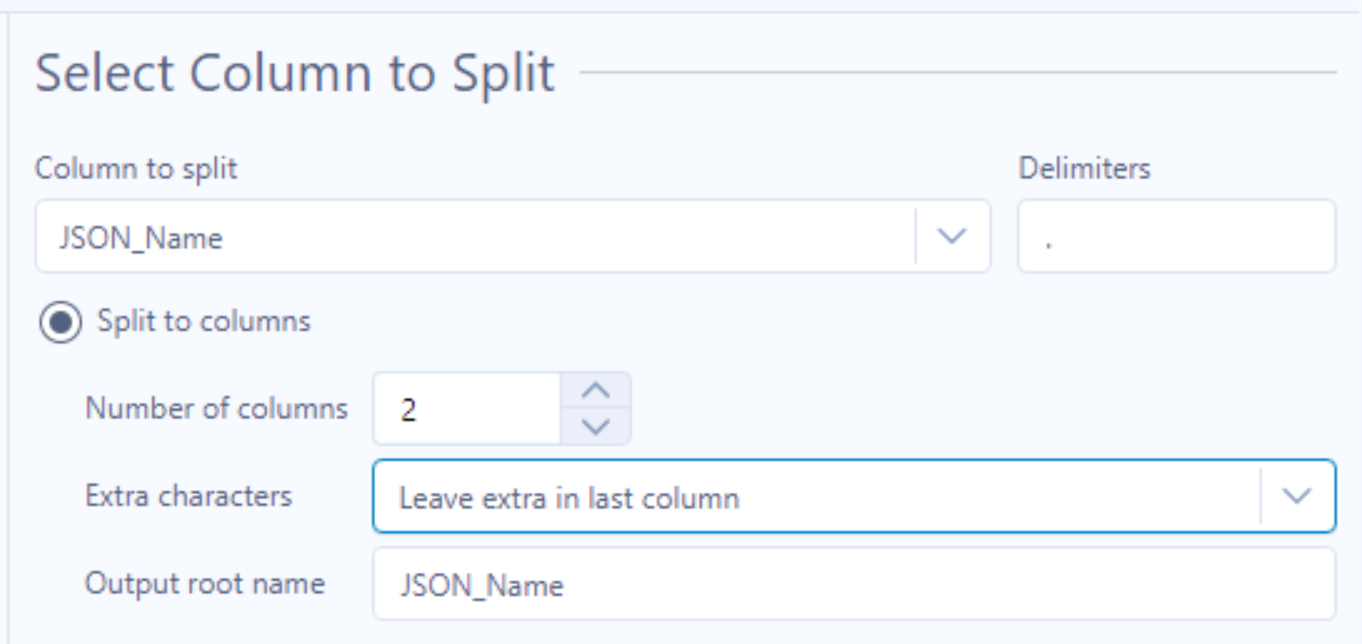
The output of the Text To Columns tool should look something like below
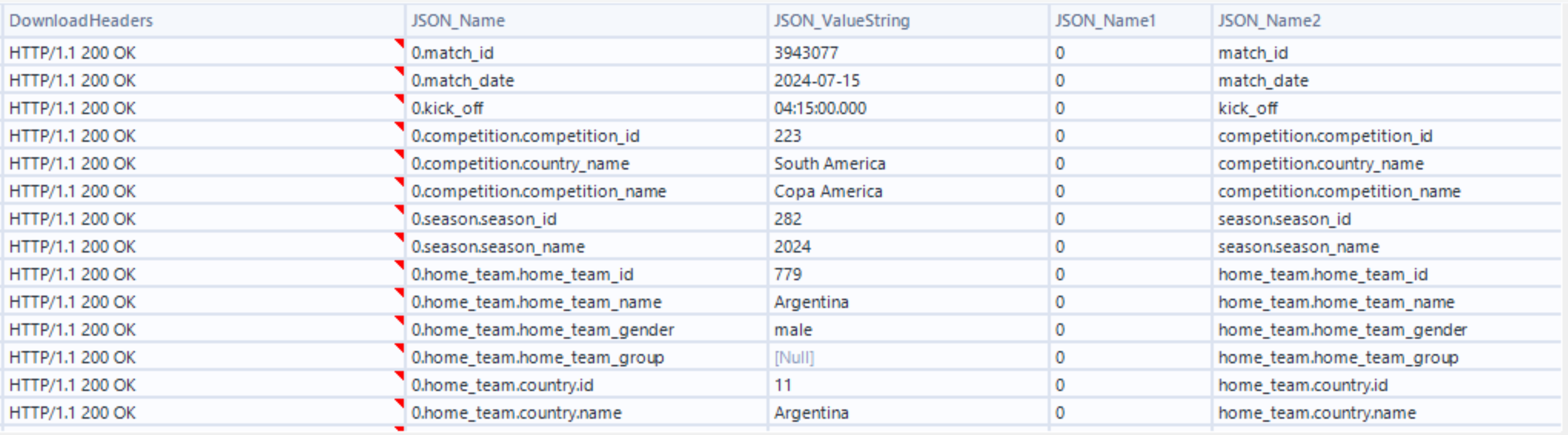
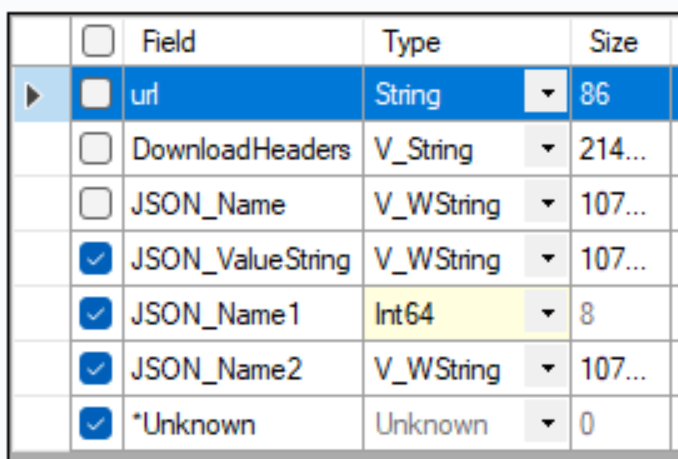
- We need to transform this output further so that each row represents a match in the competition, and each columns corresponds to information about each match. To do this we first remove unnecessary columns with a Select tool.
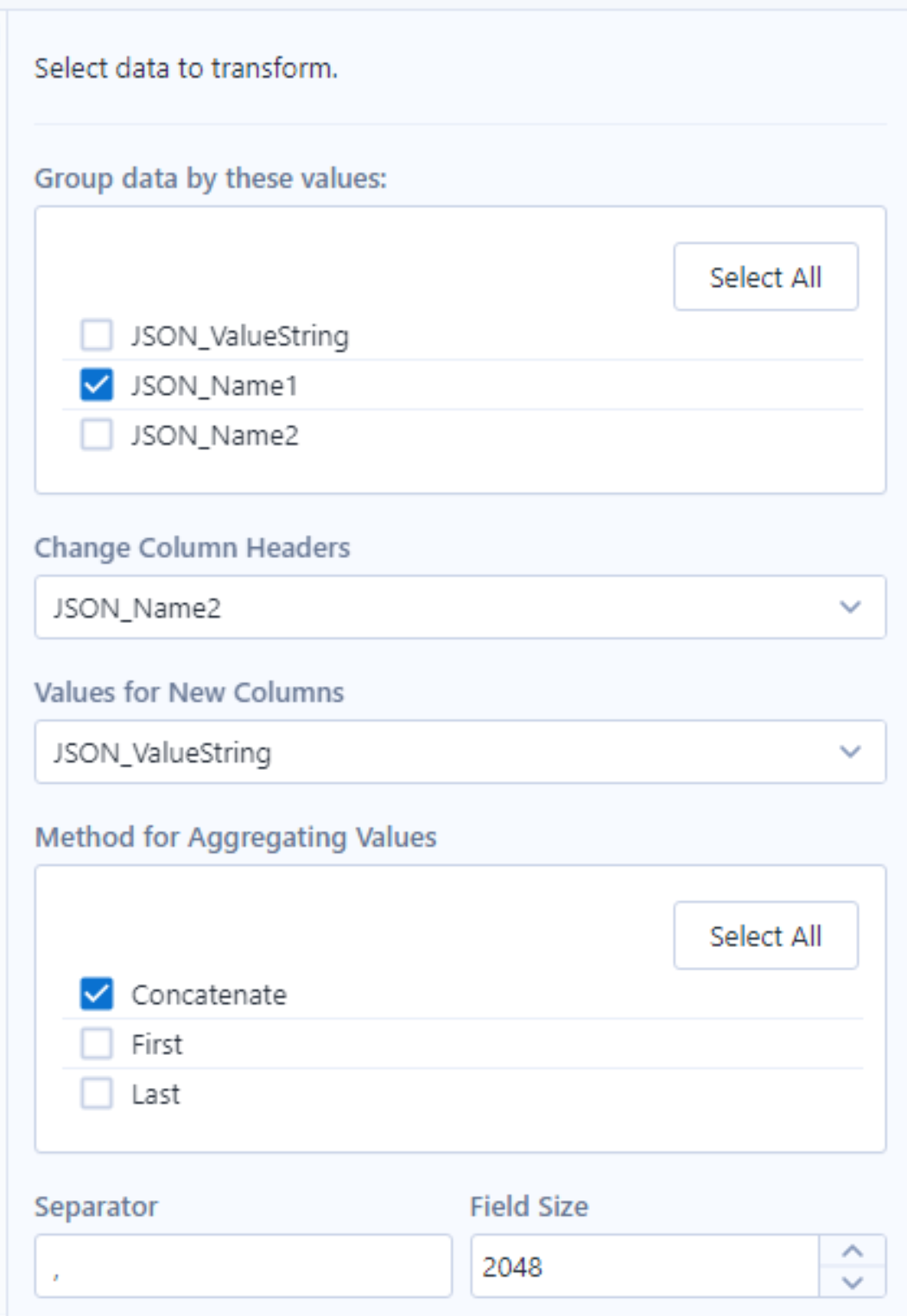
- Using a Cross Tab tool we can group by JSON_Name1 which correlates to the match number and then pivot our values to our desire output.
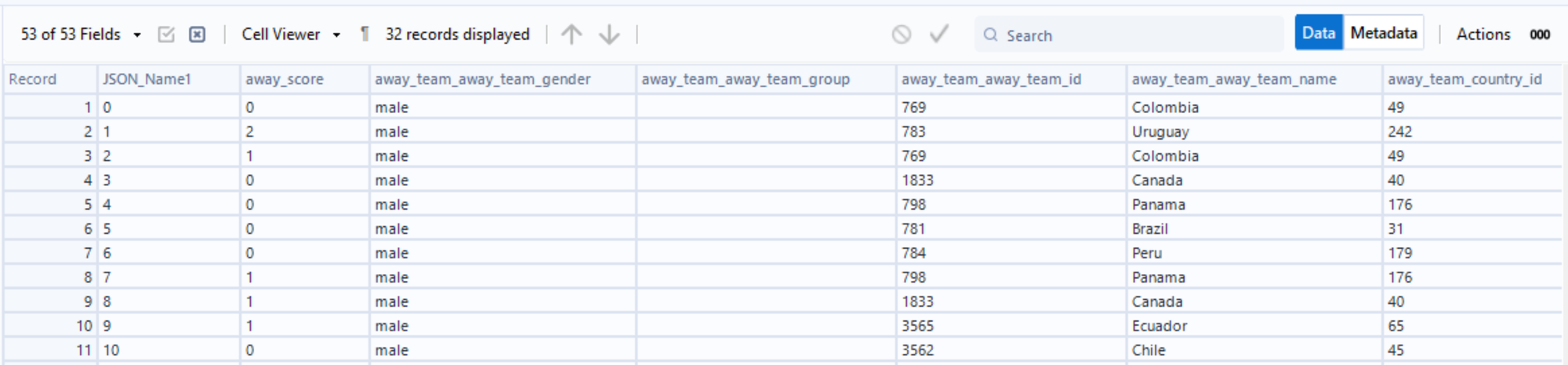
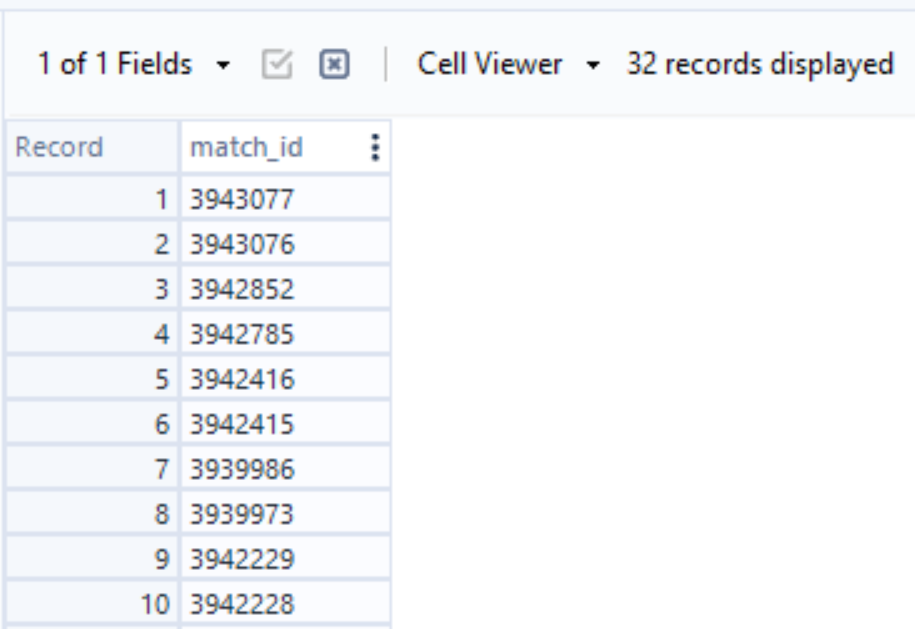
- Using a Select tool we can remove all fields apart from match_id and we have our list of values. It's worth checking that the number of records lines up with the number of matches of that competition.
Parse event data from each match
We now want to find the most granular data for each match. This is referred to as event data, where each row represents an event in a match (a pass, shot, dribble, foul etc.). Statsbomb store there event data in the same JSON format under the events folder in their repository, where each file is named after the match it represents. To do this, we have to extract the event data for each match we are interested in using the list of match_id values that we have just found.
- In a new Text Input tool paste the raw GitHub URL for any JSON file in the events folder. You may notice the match_id being used as the name of the file, the example below just uses a placeholder as we want to formulaically name each individual file in separate URLs.

- Using an Append Tool and a Formula tool we can join our list of match_id values to this Text Input tool output and the resulting table will contain a row for each match_id as well as a corresponding GitHub URL for each match.

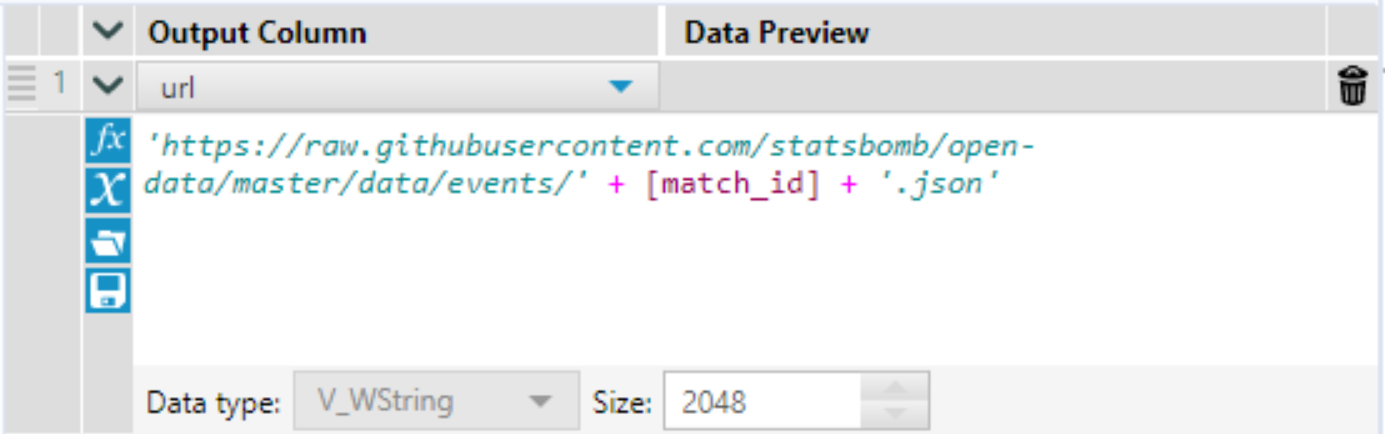
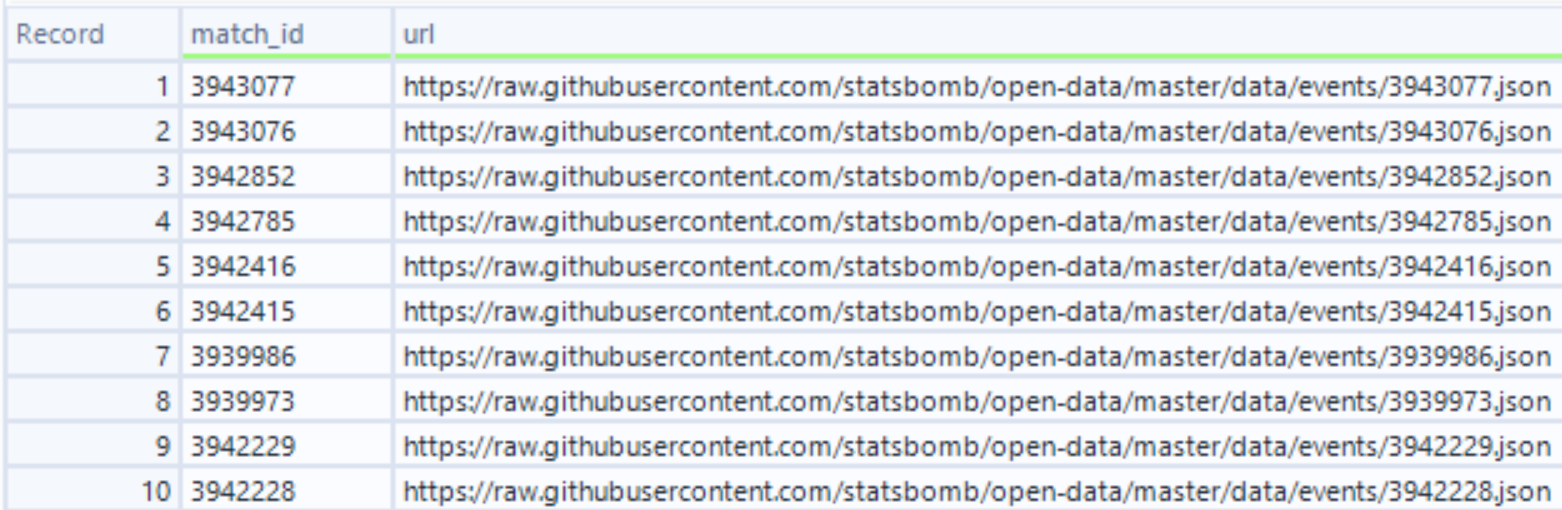
- Attach a Download Data tool and again specify the field url as the URL we want to reach. This will result in a separate download request for each for each URL, i.e., we download the JSON format data for each match.
- Convert the data into a readable format using the same combination of a JSON Parse and Text to Columns tool as before
- The events data has some supplementary information such as the line-ups for a particular match which I like to remove at this stage so that my output tables just contain event information. To do this I use a Filter Tool with the following rule and configuration:
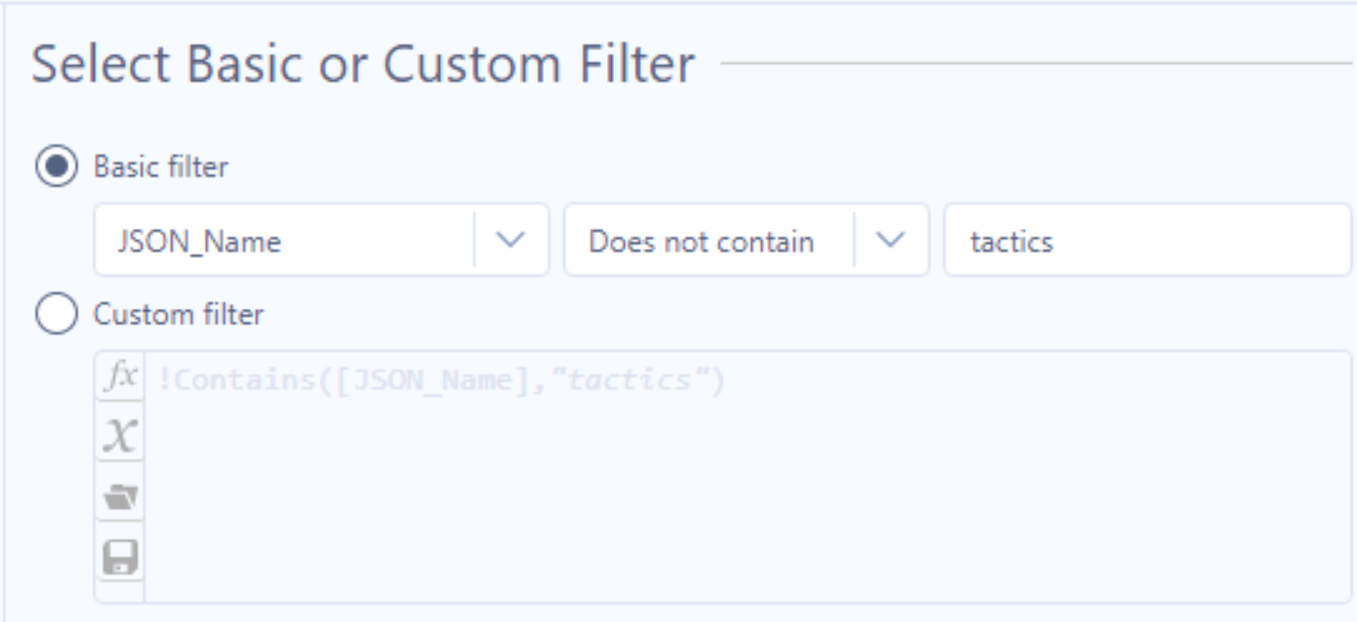
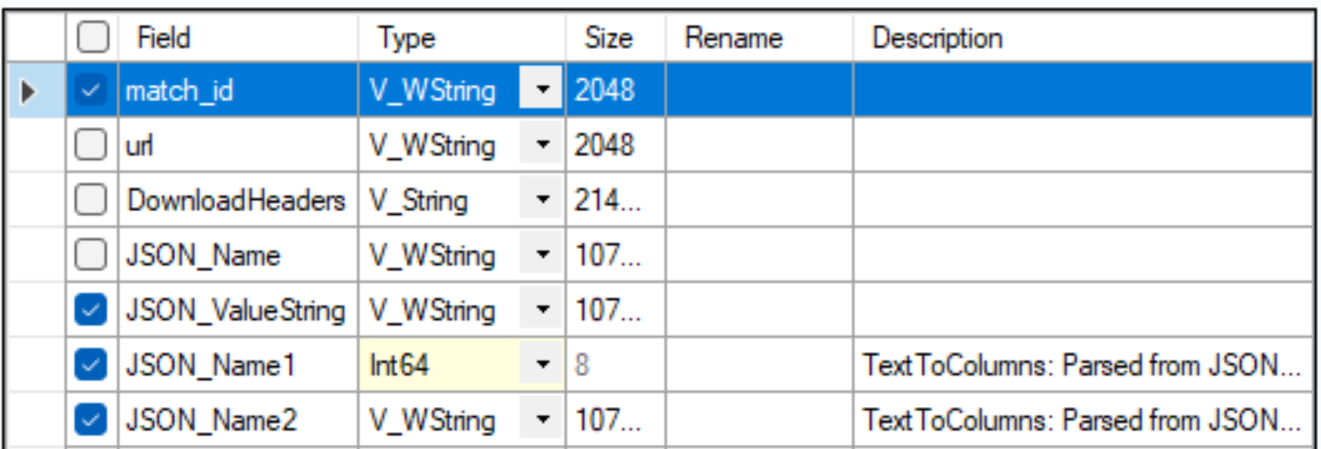
- Like before, use another Select Tool to remove unnecessary columns but include match_id this time.
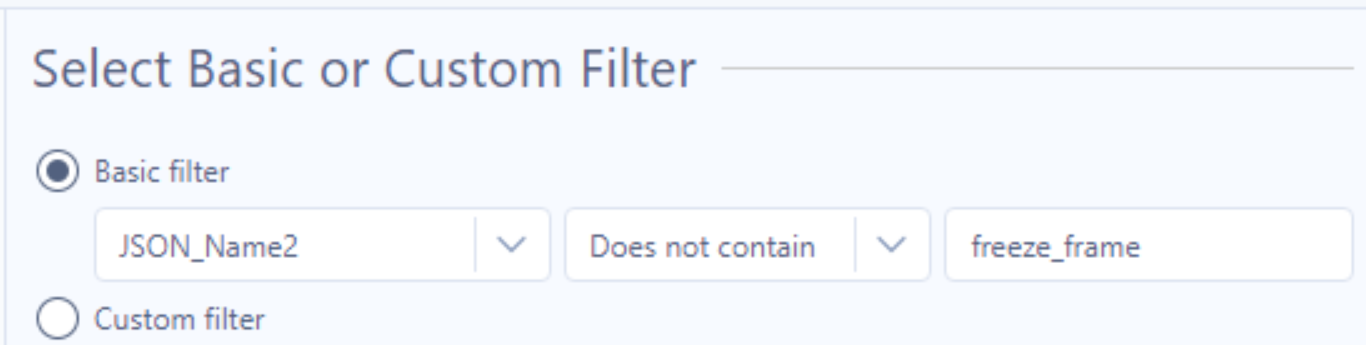
- Statsbomb events data includes something they call Freeze Frame, which includes information on the location of all 22 players on the pitch at the time of each shot. This information takes up a lot of space, so to improve the speed of the workflow and to trim rows that I know I won't be using for my analysis I use the following configuration of a Filter Tool:
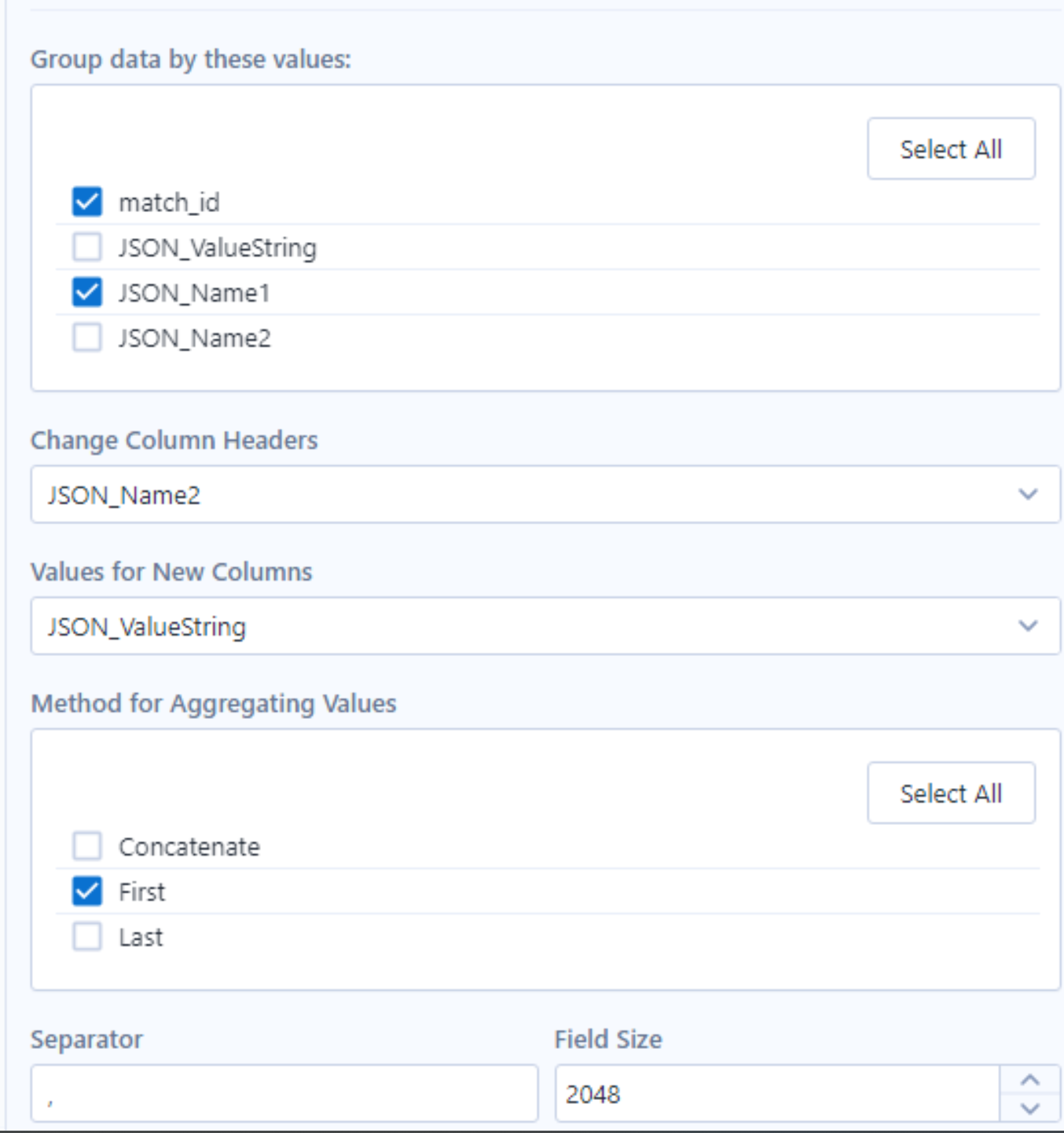
- Then use another Cross Tab tool to reformat our data into our desired output where a row represents an individual event
- Finally, I like to split up this "master" output of event data into separate tables for certain types of events. For example, I filter the master table for passes so that I have a smaller output table where one row represents a pass. To do this I just filter by type_name like below, and repeat for shots, carries, etc.

- I also like to create a table with a list of unique player names with their associated player_id, which I then relate to my pass, shot, carry etc. data for analysis.
You can now access, download, and clean Statsbomb event data and start searching for the next Messi!