Today's task was to web scrape and visualise data from cheese.com. It became immediately apparent that this would require more than downloading, parsing and cleaning HTML. Here's how I approached it. To retrieve the data on each cheese I required a list of each cheese name which I could use to build a URL. These URLs could then be used to download each cheeses webpage. Here's the catch. The list of cheeses spanned many pages, thus requiring me to build a batch macro. This receives a text input specifying the page of results and replaces this string in the URL. By examining each URL in a text editor, I determined the strings surrounding each cheese name which I parsed out using RegEX.
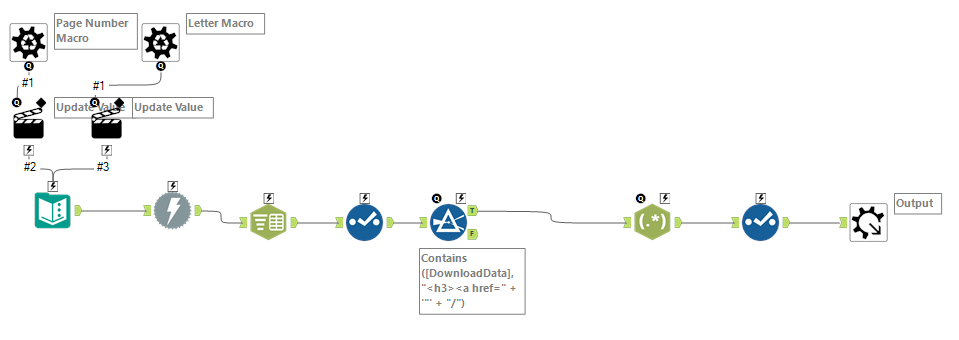
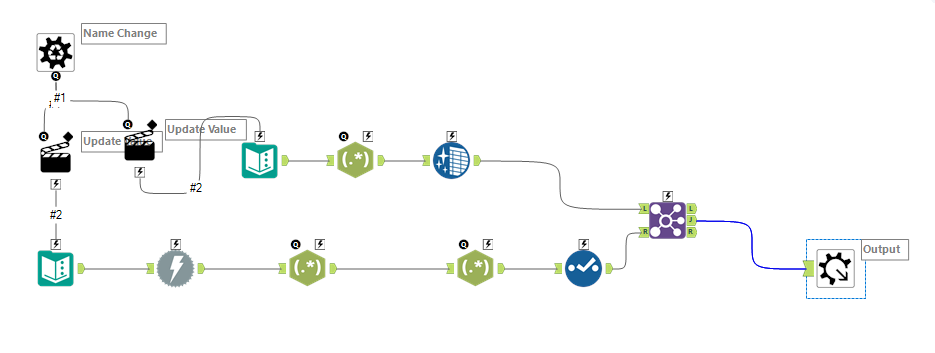
Having obtained a list of cheese names, I then construct several further batch macros to scrape information on each cheese. Similar to before, these functioned by replacing strings in a URL, downloading HTML and parsing out information. The several outputs I had generated were then joined on rowID, creating a full dataset of cheese names, statistics and descriptions.
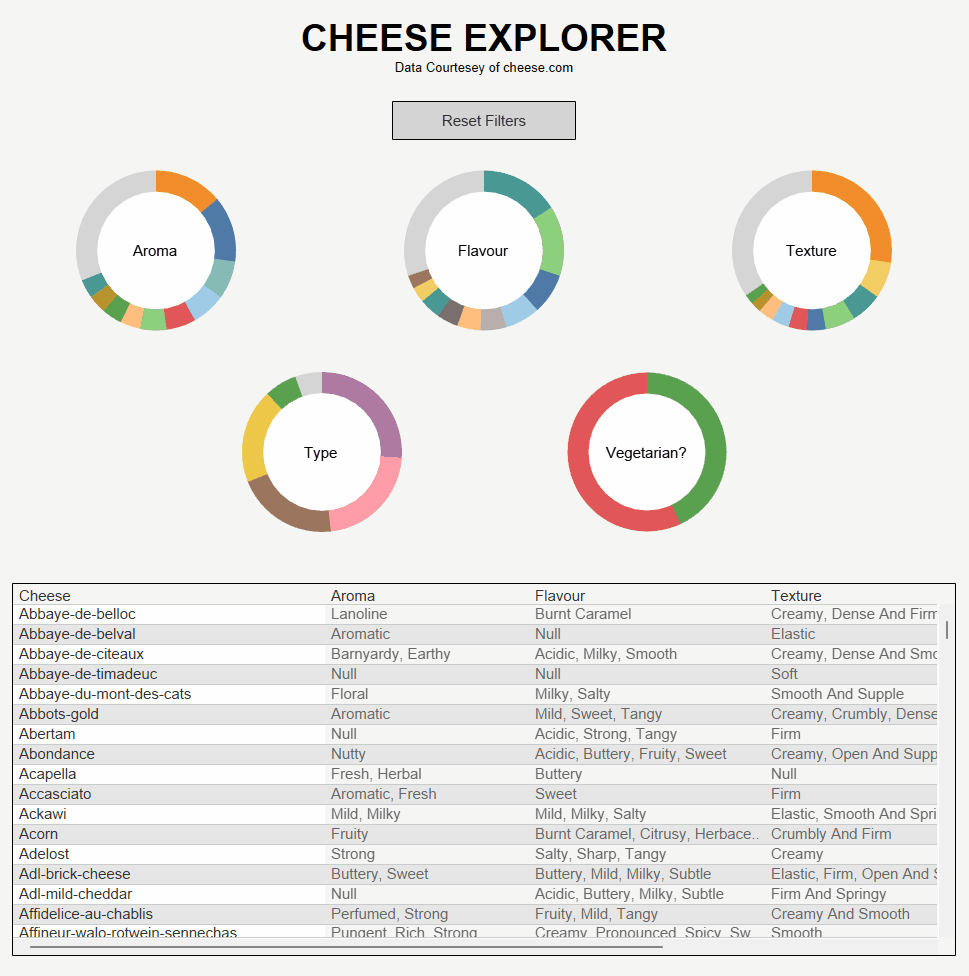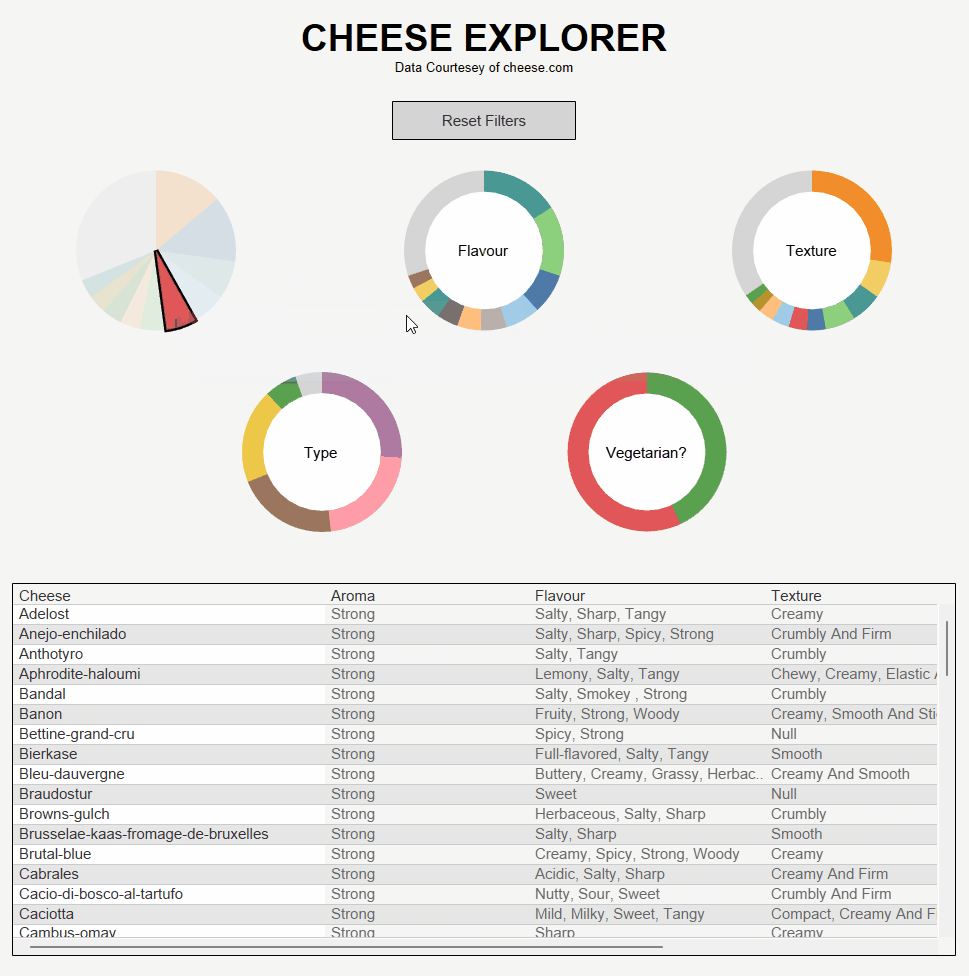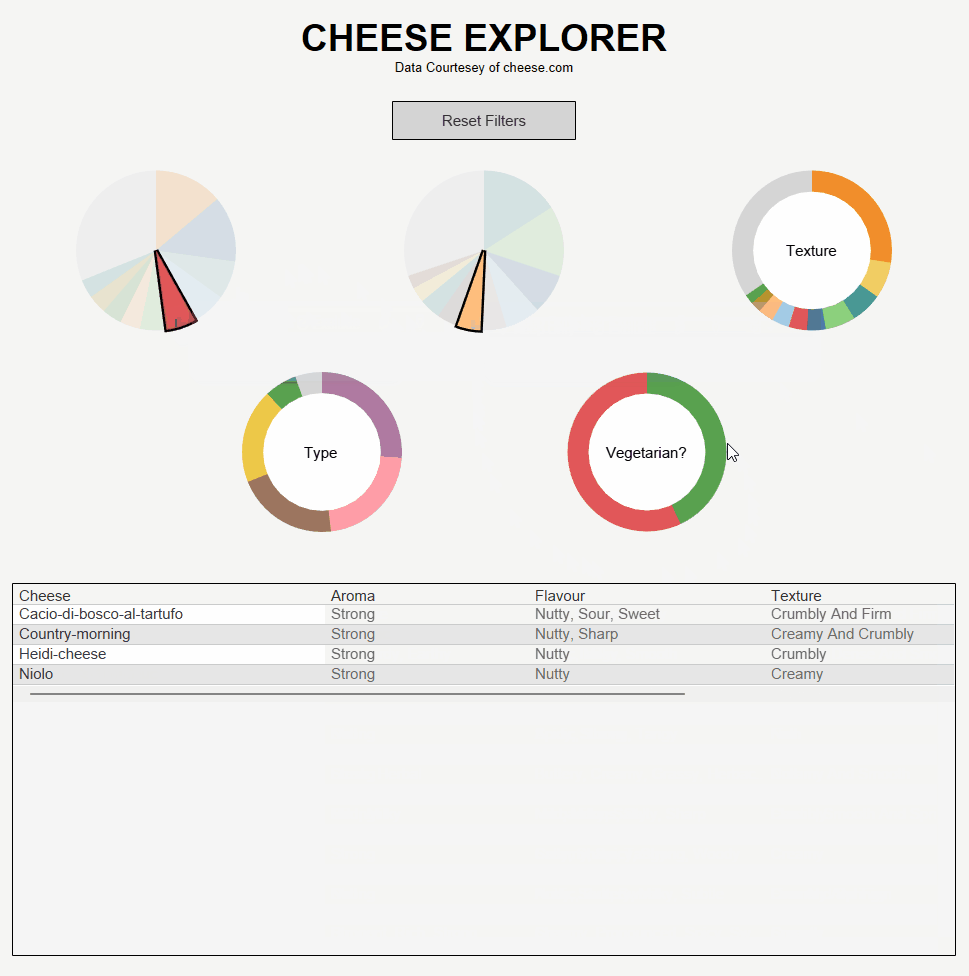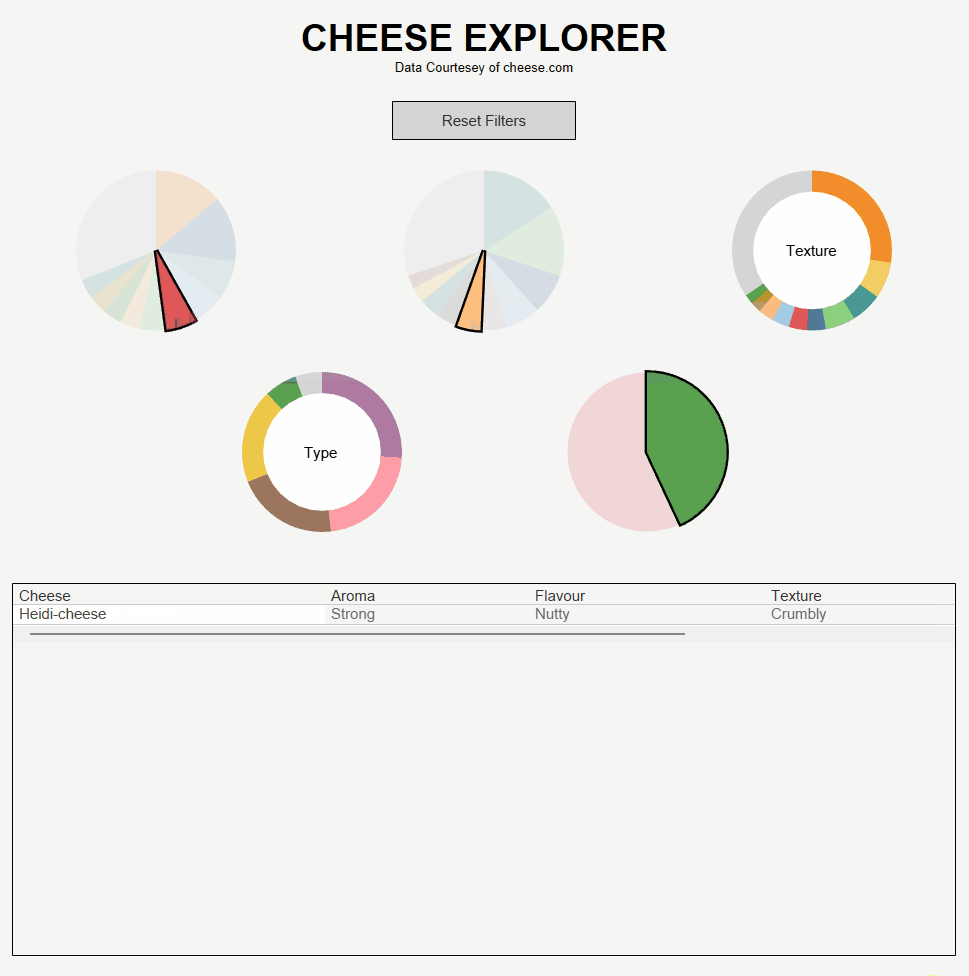
Using this data I produced a tool which allows users to find cheeses based on preferences for scent, taste, texture, type and dietary requirements. Here's how it came out: