


Regex, short for regular expression (pronounced: Rej-Ex), is a powerful tool used for pattern matching in text (string data). It allows you to search, match, and manipulate strings based on specific patterns. As the syntax for regex varies between tools and languages, in this blog I will be focusing on the syntax used in Alteryx.
To utilise regex in Alteryx, you can either use the RegEx tool to replace, tokenize, parse, and match string values, which will be the main focus of this introduction to regex, or alternatively, you can use regular expressions within the formula tool with functions such as REGEX_match().
Replace - In regex, "replacing" refers to the process of finding a specific pattern within a given text and then replacing that pattern with another text or pattern.
Tokenize - In regex, tokenization is the process of breaking down a text into smaller units, such as words or sentences. Using a regex pattern, each occurance of the pattern in a string creates a new sub-string that is selected.
Parse - In regex, "parse" typically refers to the process of breaking down a string into multiple groups, or substrings, h0vever, unlike tokenization, these groups are not based on a single pattern, but instead a series of sub-patterns within a single regex expression, called groups, where each group only gets a single substring. It is important to note that each group/sub-pattern will always only select the first instance of it in a string, working through/matching each group sequentially.
Match - In regex, "match" simply refers to checking whether or not a string matches a regex pattern, subsequently returning either true or false depending on the outcome of the check.
How do you create a regex pattern?
As mentioned previously, though the logic stays consistent, the syntax for writing regex expressions/patterns may slightly change between tools and languages. With that in mind, the screenshot below displays an Alteryx cheat sheet for writing their regex syntax.
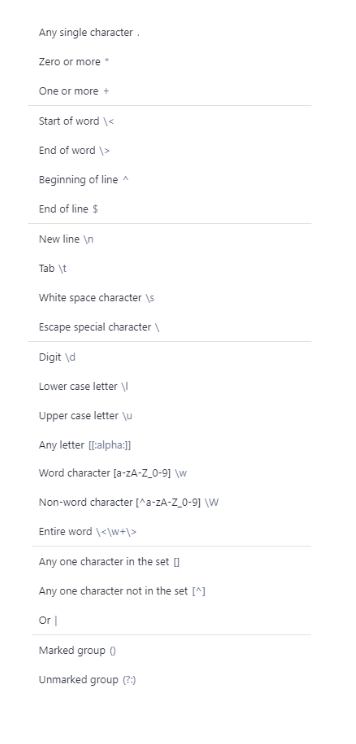
Examples
Example 1
Following this guide, if, for example, if you wanted to select the entire word "Hello", you would use the regex pattern ".*" (ignoring quotations). The "." selects any character, and the "*" selects it any number of times, meaning it will select the entire string.
Example 2
Next, If we wanted to get the first two letters and the last four numbers of a string, and store them in separate fields, such as for the string "TSDS426789", we would use a regex pattern with the Alteryx "parse" option. This pattern would be, "([A-Z]{2}).*(\d{4}\>)". Breaking this down:
([A-Z]{2}) Matches exactly four instances of an uppercase letter. The surrounding brackets mark this as first group to parse, and will therefore create a new column containing the part of the string which matches this pattern.
.* Similarly to the first example, this matches any character any number of times. Moreover, as this part of the pattern is not enclosed in parentheses it will not be included in the parse, it is simply here to provide context to the parts of the pattern we do want.
(\d{4}\>) Matches exactly four instances of a digit character, e.g. 1 to 9, followed by an end-of-word border. This ensures that the four digits found are guaranteed to be the last four digits of the string. The surrounding brackets mark this as second group to parse, and will therefore create a new column containing the part of the string which matches this pattern.
Example 3
Moving on to a slightly more challenging example, if we wanted to check if a field contained an email address, such as JohnSmith100@fakeemail.co.uk, we would use the regex pattern "[^\s]+@[a-zA-z]+.[a-zA-z.]+". Breaking this down:
[^\s]+ Matches all characters that aren't a space (whitespace) or the @ character, as email addresses cannot contain spaces or multiple @'s, at least once.
@ This simply checks if the next character after the initial portion of the email address is an @ symbol.
[a-zA-z]+ Matches all lowercase and uppercase letters at least once, corresponding to the email server name, e.g. "hotmail" or "gmail".
.[a-zA-z.]+ Matches all lowercase and uppercase letters, or a fullstop, at least once, corresponding to the email suffix, e.g. ".co.uk" or ".com".
Your turn
Using the guides and examples within this blog, try out some by yourself! The answers will be posted in my next regex-related blog.
Easy
What regex pattern would you use to check that a word only contained two digits, where the first digit is not a 0?
Example match: 54
Example non-match: 07
Medium
What regex pattern would you use to check that a 'Full Name' field only contains letters, and contains exactly two separate words, where each word starts with a capital letter.
Example match: Tom Smith
Example non-match: t0m Sm1th
Hard
What regex pattern would you use to separate the string "13876,BIRMINGHAM AP,AL 30, 43.8, 47.7, 55.2, 62.5, 70.6, 77.7, 81.1, 80.7, 74.7, 64.1, 54.4, 46.1, 63.2" into 17 distinct columns.