


This weeks client project is all about market basket analysis. To answer the questions our client has about his dataset, a Co-Occurrence Matrix was an Idea we wanted to pursue.
For a baseline understanding about how to build them:
https://www.youtube.com/watch?v=h3a9RcC_ezE
We had to self join the Data in order to create this Matrix . This means joining the dataset with itself, but in a particular way, so that only orders with different Items get joined. To also eliminate the join of an item with itself our first idea was to generate row numbers, so that no row can join with itself with the easy join clause:
Row_Number =! Row_Number
Sadly Tableau Prep does not have a native way to generate row numbers. But
when searching for generating row numbers in Tableau Prep we quickly found different articles from other Data Schoolers or The Information Lab in general describing the concept of how it can be done. :
Instructions for the creation of a row number:
https://www.thedataschool.co.uk/linda-duong/how-to-create-row-id-in-tableau-prep/
With a bit more detail:
https://www.theinformationlab.nl/2022/04/22/prep-builder-add-a-unique-row-id/
What both articles did not warn me about: Every Time you change / add / remove parts of any step, it calculates some or even all steps before again. This not only slows done the runtime of Tableau Prep, especially if your data is not a .hyper, but it also affects calculations that choose elements at random. What does this mean for our task? Every time we changed a cleaning step the row numbers changed, because we had rows that were 100% duplicates. This in itself would not be a problem since we only used the row numbers in our join ... but Tableau Prep does something crazy here:
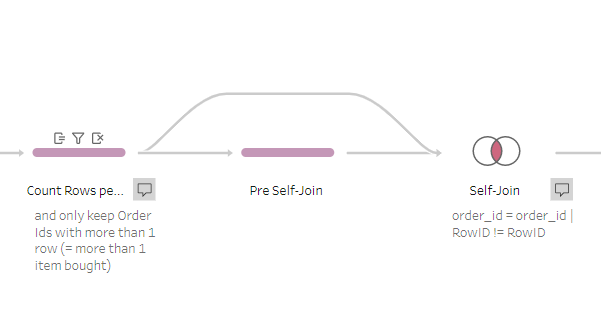
This did not work !!! Duplicate rows were partly matched with itself. So why is this happening? Tableau Prep seems to redo the calculation for thew row number, which happens even before this screenshot again for generating the Pre Self-Join step. Because they are 100% duplicates they get assigned row numbers at random. Luckily for us our client wanted the duplicated data removed from the set anyway, so we got around in finding a solution.
While writing this Blog I still have no solution to this problem. If this changes I will update this blog, so stay tuned 📻
See you all next week.