


If you're new to dbt (Data Build Tool), think of it as the link between raw data and actionable insights. dbt transforms messy, unstructured data into clean, analysis-ready tables—empowering data teams to work smarter, not harder.
A Quick Look at Traditional Data Teams
In a typical data workflow:
- Data engineers manage infrastructure and handle the extract/load processes to bring data into a warehouse.
- Data analysts query that data to generate insights for stakeholders.
With the advent of cloud data warehouses like Snowflake, BigQuery, and Redshift, a new paradigm—ELT (Extract, Load, Transform)—emerged. Unlike the traditional ETL process, which transforms data before loading it into a database, ELT involves:
- Extracting raw data from various sources.
- Loading that raw data directly into a data warehouse.
- Transforming the data in-place within the warehouse.
This shift allows for scalability, better performance, and the ability to iterate faster, as raw data is always available for reprocessing.
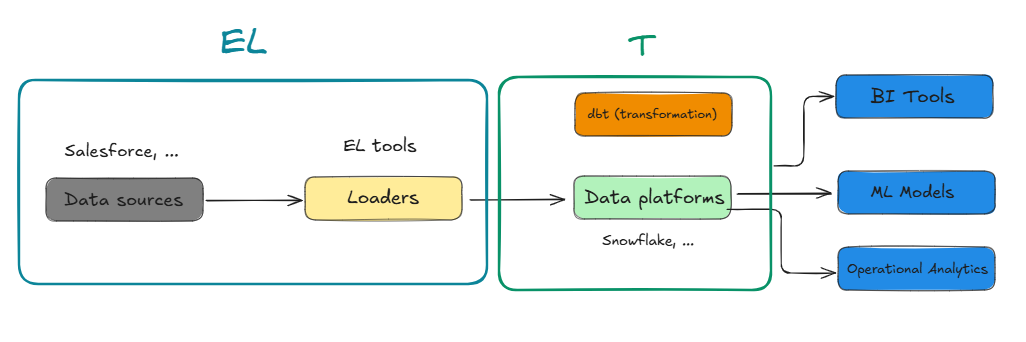
Where Does dbt Fit In?
This is where dbt shines—it helps analytics engineers, who sit between data engineers and analysts, to handle those critical transformations. dbt lets you automate the cleaning, organising, and structuring of raw data, enabling analysts to focus on the insights rather than the data wrangling.
How Does dbt Work?
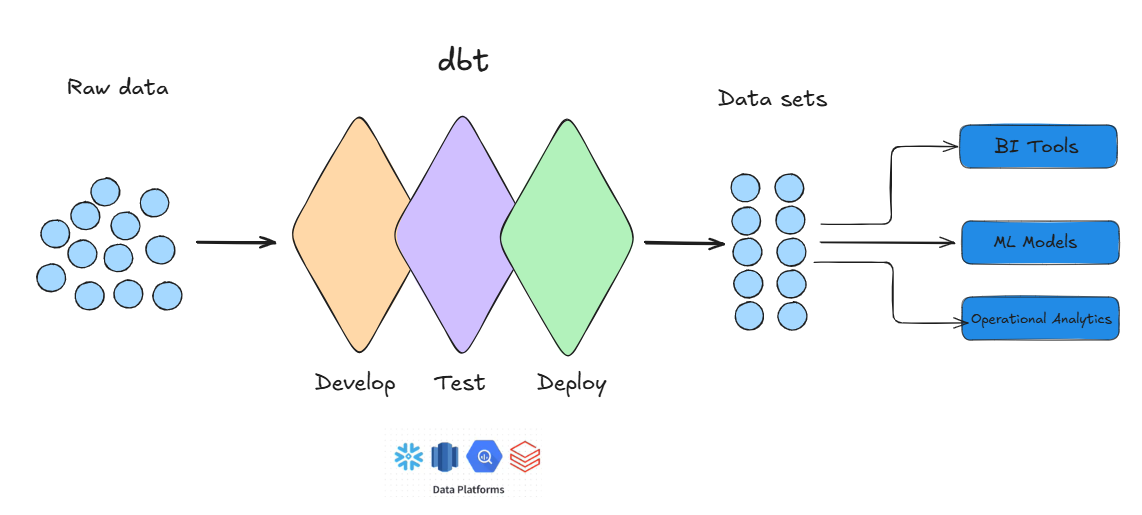
At its core, dbt is a transformation tool that connects directly to your data warehouse. Here’s how it works:
- Write SQL Models:
- You define your transformations in SQL, which dbt compiles into SELECT statements.
- dbt’s goal is to compress all logic into pure SELECT queries, avoiding unnecessary procedural elements like sub-delays or window functions outside of SQL’s capabilities. This ensures maximum performance and compatibility with modern data warehouses.
- Run Transformations:
- dbt executes your models to create materialised views, tables, or incremental updates in your warehouse.
- These transformations follow a dependency graph (DAG), ensuring that upstream models are processed before downstream ones.
- Automate and Test:
- dbt includes built-in testing to validate your data (e.g., ensuring there are no nulls in critical columns).
- You can schedule dbt runs, automate workflows, and even version-control your models using Git.
- Document and Collaborate:
- dbt automatically generates documentation for your models, making it easier for teams to understand and navigate your data pipelines.
Why Use dbt?
Advantages
- Automation: dbt reduces manual effort by automating repetitive tasks. Once your transformations are defined, they can run on schedule with consistent results.
- Collaboration: With Git integration, dbt allows teams to version-control transformations, enabling seamless collaboration and change tracking.
- Data Quality: Built-in tests ensure data reliability, catching issues early in the pipeline.
- Transparency: dbt’s auto-generated documentation and lineage graphs make it clear how data flows through your system.
Considerations and Limitations
- Not an ETL Replacement: dbt doesn’t handle data ingestion. You’ll need tools like Airbyte or Fivetran to move data into your warehouse before dbt can take over.
- Warehouse Dependency: dbt works best when your data is already centralised in a warehouse such as Snowflake (or data mesh, in the case of dbt's more advanced features). If your data is scattered across multiple sources, dbt won’t be able to help until it’s all in one place.
- dbt vs. Alteryx?: It’s important to note that dbt is not a replacement for tools like Alteryx. While Alteryx offers a no-code/low-code approach to data preparation and blending, dbt is all about SQL-based transformations within a data warehouse. Alteryx shines in handling disparate data sources and providing visual workflows, whereas dbt is focused on scaling data transformation within cloud data warehouses. They can complement each other but serve different roles in the pipeline.
Final Thoughts
dbt is a game-changer for modern data teams, bringing software engineering principles into the transformation layer. It’s powerful, scalable, and efficient—allowing teams to focus on insights rather than wrestling with messy data.
However, dbt isn’t a one-size-fits-all solution. It thrives as part of a broader data stack, working alongside ingestion tools like Fivetran or Airbyte and analysis tools like Tableau or Power BI.
If you’re just starting with dbt, I recommend exploring their fundamentals course and trying out this quick-start guide.