


What kind of dataset do we want? The general thinking towards having a well structured dataset is that we want it to to have a high level of granularity, with only relevant columns, and structured in a way that is easily readable by humans or computers (or both).
Data that is tall and thin, with measures in a single column for example, are easier manipulated when doing row level calculations, as you can apply formulas to multiple rows at once.
The transpose tool. It allows measures to be converted into rows of data, with each measure corresponding to its value. This allows the format of the data to become narrower, with all chosen columns now in one:
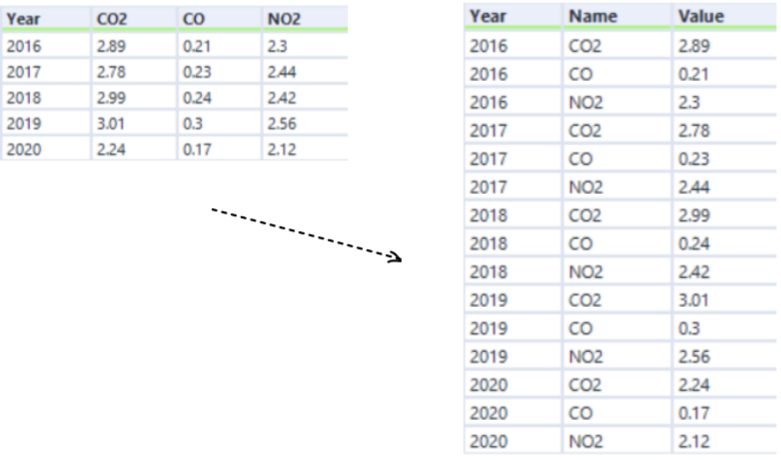
When transposing, we need to think about what the key columns are (the ones that we want to stay in place), and what the data columns are (the ones that we want to be in the rows of data). Below we can see the configuration for this blog's example, where year is a key column, and the other headers are now data columns.
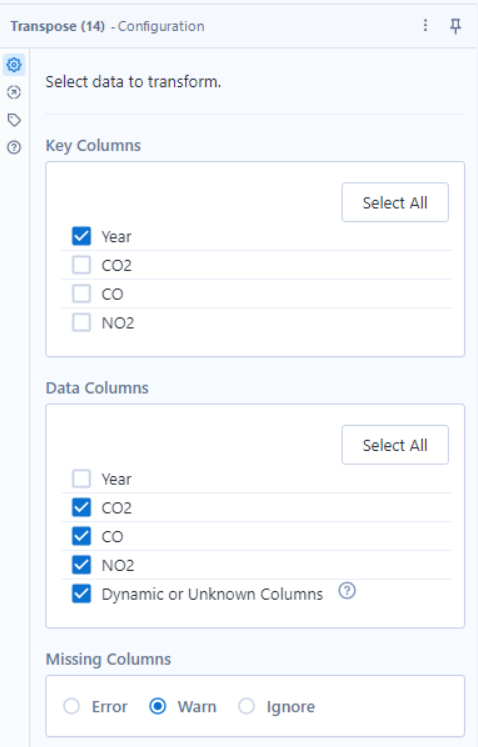
We tick 'Dynamic or Unknown Columns' to allow for future columns that we also want to transpose.