


Yesterday I was doing Alteryx weekly challenge #37, which required me to parse the XML formatted text. Obviously, it demands the usage of the XML parse tool, which I have never tried before! Good chance to learn it. But I don't even know what XML means! So I will try to explain what is XML in this blog, with the modified examples I made from w3schools and some internet resources.
What is XML?
XML stands for Extensible Markup Language (XML), which focuses on text storage and transmission. Each XML element is a chunk of pure text wrapped by tags, while tags have no function - They are just named tags. Noted that it is somehow similar to the HTML element. However, tags in HTML have a predefined meaning, which can change the display of the text, like color and size. Tags in XML element is just a name indicating what the text is about. They did nothings!

The XML element can either contain text or other contents to form a structure. The example below shows the title and author of a book. Can you see the <book> tag? It wrapped other elements (contents) rather than text. The wrapped elements should be indented to indicate they belong to the wrapper.
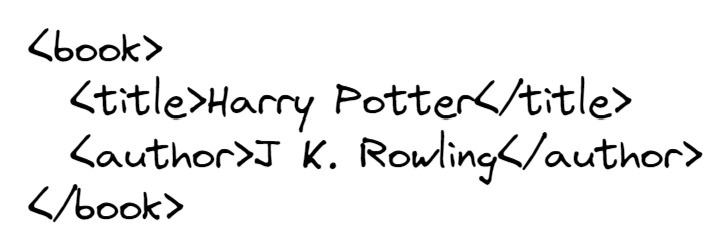
The tags can have attributes to add extra information. Let's say we want to indicate the book is categorized as 'children'. We can use the format:
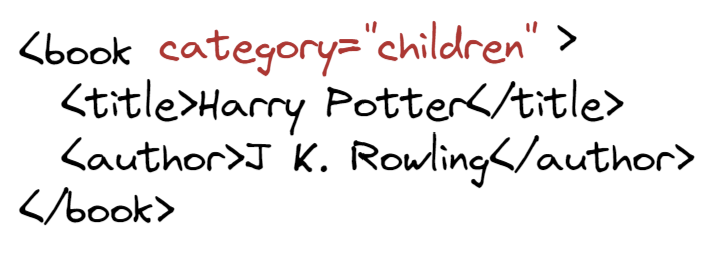
With this technique, we can build a more complicated structure. Below is a bookshelf with two books, each of which has its category information and details.

As you can see, XML can form a hierarchical/ tree structure, as known as an element tree. Each element tree at least contains a 'root' (most outer wrapper) and a 'child' (the wrapped element), but it may contain a 'sub-child', a 'sub-sub-child' and so-on when there are multiple levels of hierarchy.
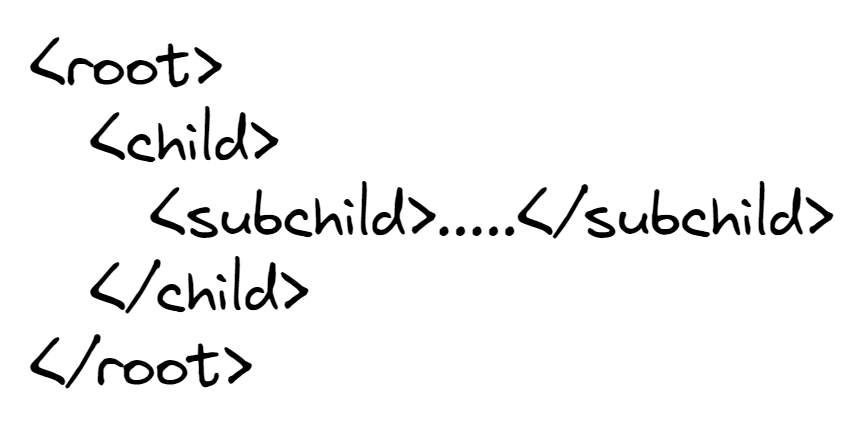
So Here is it! The introduction of XML. Next time I will teach how to parse the XML elements into columns in Alteryx
Feel free to check out my other post or connect with me on Linkedin - learn and improve together!
https://www.thedataschool.co.uk/blog/stanley-chan