


Web Scraping means to extract the information from the webpage. In Alteryx, we can easily extract the HTML information from a webpage . However, I found that the downstream procedure is what makes it difficult. Here is what I think being important to know or consider.
(1) Always inspect the webpage you are intend to scrap. By right click the webpage the select 'Inspect', you can see the panel appeared next to the webpage. Hovering over the HTML element, the corresponding webpage element would be highlighted. Or vice versa by clicking the pointer logo (indicated inside the red square) and hovering over the webpage element, the corresponding HTML element would be highlighted. This can help you to identify the needed HTML element without read all the HTML text by your little brain.
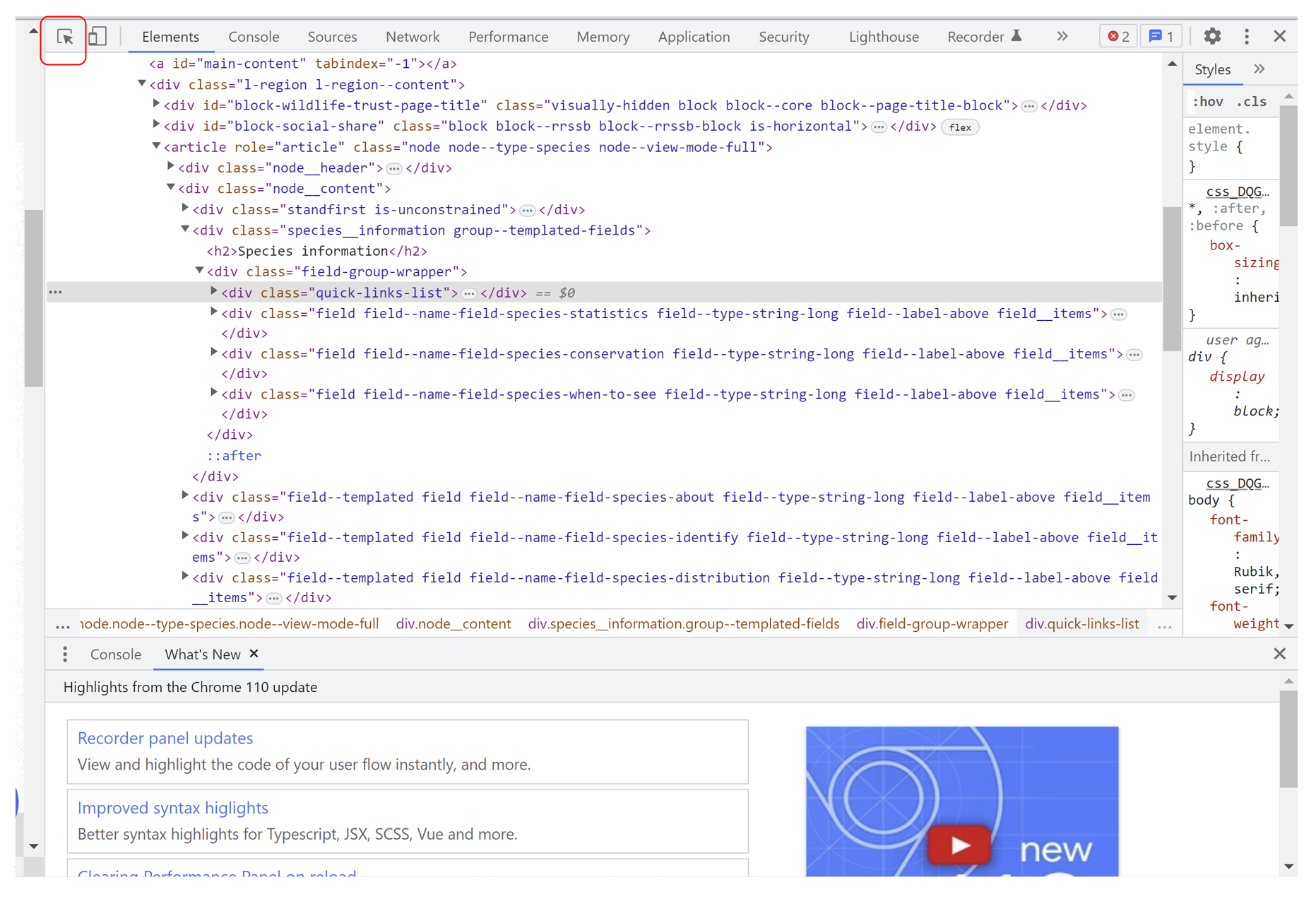
(2) Check the unique flag that can help you to identify the location of the page. After finding the range of elements that you needed, you also need to identify the elements before and after the range elements as flags. They would be better if it only occurs once in the whole HTML page, so that you can extract the range of elements by Regex tool like: [start of unique flag](.*)[end of unique flag].
Right click the webpage the select 'View page source' and 'contrl + F' to find if they are unique (only one match).
(3) There are a routine to do web scraping in Alteryx.
- attach a put tool that contains the URL of the webpage, to a 'download tool
- use text & column tool with parse the single cell of HTML into multiple rows (Delimiters as \n; Split to rows)
- remove all the tab and extra-space character by Data Cleansing tool
- remove all the empty row by filter tool
- use Regex tool to parse out the text you want. You might also want to only filter the row your want with a filter tool containing multiple condition.
- If your intentions is to extract multiple items (eg movies, books, people....), use Multi-row tool to do indexing. It can also be used for recursive indexing to label the attribute of each item
- use crosstab tool to transform each attribute into columns
(4) When you do Regex or filter the row based on the HTML. Be extra-careful about the exceptional case. For example, I had once extracted the image link with a tag 'type=image/jpeg' and some of the link just didn't be extracted. I spent a long-time to figure it out and it turned out there is a tag called 'type=image/png'. There are too much these case out there, just pay attention and cross-check the result!
These are some of my advices on web scraping on Alteryx. Hope you enjoy the scraping process!