


What are Fact and Dimension tables and how do they relate to Schemas?
I just finished my first week at the Data School and one of the first sessions we had was related to Data architecture. Our first session focused on learning about data architecture, specifically fact and dimension tables and how they relate to schemas.
Fact and Dimension Tables
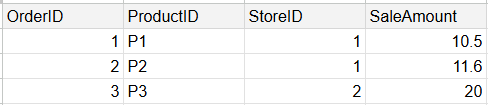
A fact table holds the measurable data within a data set. These are usually transactions that contain numerical values used for analysis. The table below illustrates sales data which can be used to calculate things like the total sales.
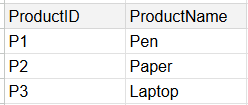
A dimension table holds the details about the categorical fields in a data set. They help provide context to the user.
Whilst the fact table above was useful in helping us measure our total sales, the table below is useful in helping provide meaning and context to the fact table.
Schemas
A schema defines how data is organised within a relational database.
There are two different types of schemas - star and snowflake.
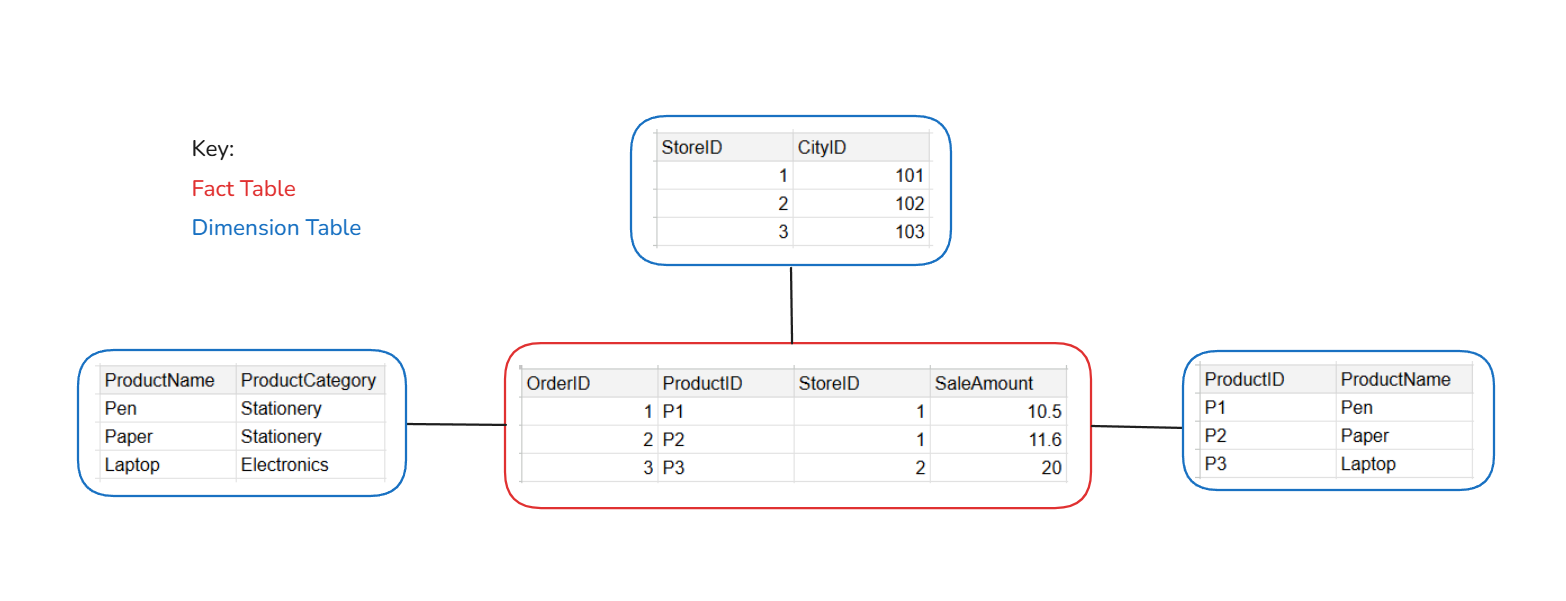
A star schema contains one fact table which connects to multiple dimension tables, as illustrated above.
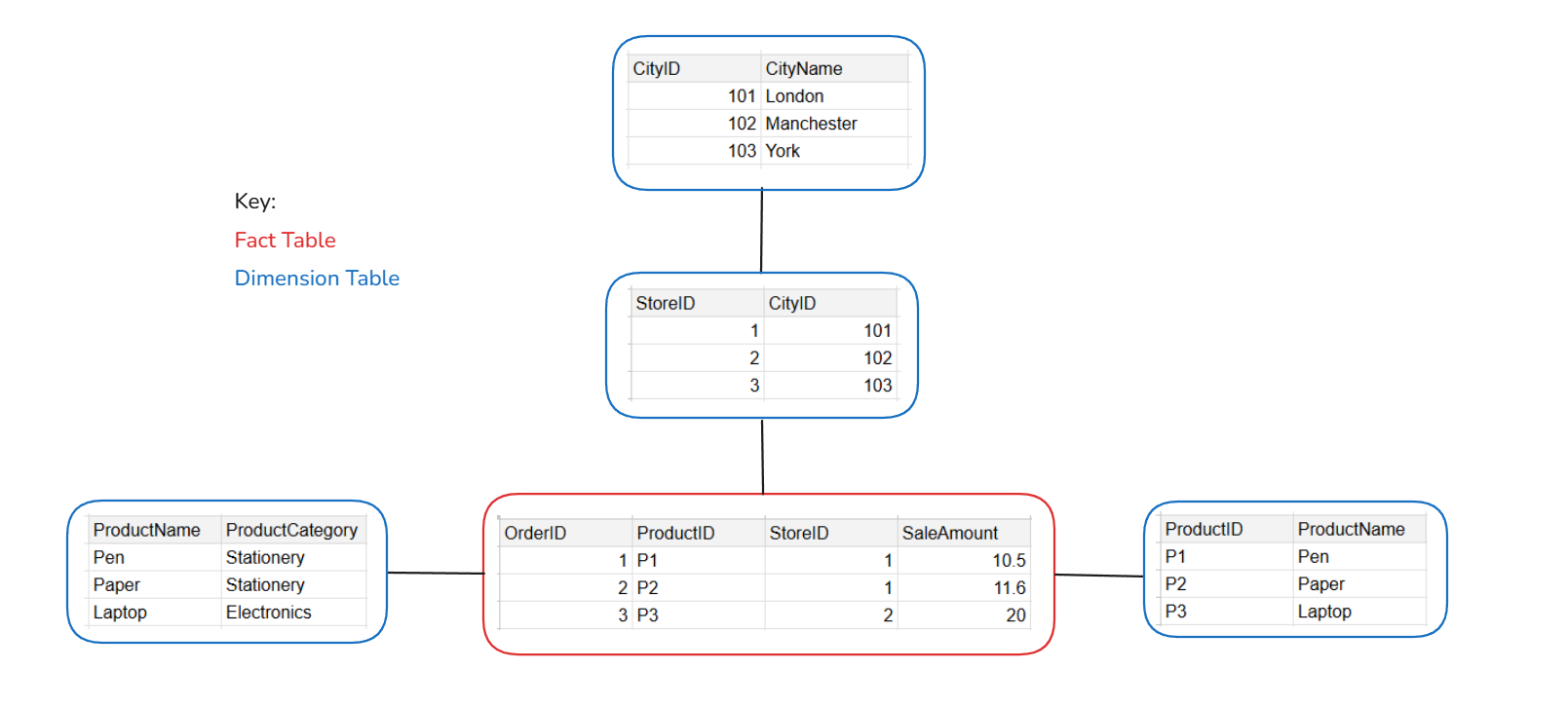
A snowflake schema also contains one fact table and multiple dimension tables. The key difference is that in a snowflake schema, dimension tables can reference other dimension tables. In the example above, we can see that the dimension table containing StoreID and CityID can be joined to another dimension table that contains information about the actual city names. This additional dimension table allows for a more granular analysis.
Schemas essentially act as a type of documentation within a database, making it easier to understand the data. Star schemas also help with reducing redundancy; rather than having information repeated over every row in a fact table, it is only stored once in the dimension table and then referenced.