


Two of the most valuable capabilities of DBT are testing and documentation. DBT offers the ability to test the data as it moves through your pipeline therefore mitigating any errors in the future. It also allows the user to document both the structure and purpose of your data models by generating clear documents for any users to read. Together, these features improve collaboration and integrity of your data across teams.
Testing
Testing is vital when using data for reporting or analytics. A small issue, such as a missing value or incorrect data type can create huge problems later down the line. DBT allows the user to set expectations upfront and check if these expectations are met.
There are 4 main tests within DBT:
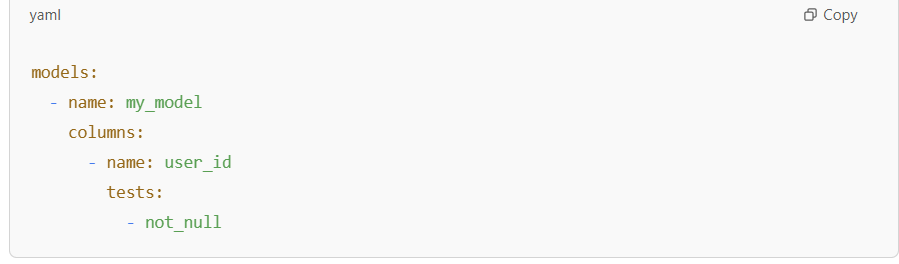
- not_null
- unique: can be used for ID fields etc.
- accepted_values: allows a column to contain only values you have selected
- relationships: ensure values in a column match a primary key from another model
Custom tests are also available which can be written in SQL.
Testing Syntax
Testing as you go is very important as you are able to catch issues earlier on as well as using descriptive test names such as test_order_value_is_positive instead of something ambigious.
Documentation
Ensuring data models are well-documented becomes essential. This enhances collaboration and promotes reusability
In DBT, documentation is defined in a .yml file. You would essentially write a description after the name section. Documenting columns is also similar as well as documenting tests and sources.

To generate the documentation, the user would run the following command:
dbt docs generate
This will open a page where you can explore the documentation