


The unique tool is used to remove duplicate data entries from a dataset.
The tool has one input and two outputs: U, the unique data entries in the dataset and D, the duplicate data entries.
The output will vary depending on how the tool is configured.
In the example given in Alteryx sample workflow; we can see that we have to be careful which columns we select in order to get the actual unique data entries.

In a large dataset of names and addresses, if we configure the unique tool by selecting the first name and last name, the U output will give only the unique combinations of both first and last names.
However, as we know, people do share names. If we take a close look, in the “One Unique Grouping” section, the unique tool filters out 6 records, including one record; “Kim Smith”.
Inserting a sort tool configured by FirstName, we can see that there appear to be two Kim Smiths at different addresses. “Smith” is a common name, adding to the evidence that this is probably a different person.
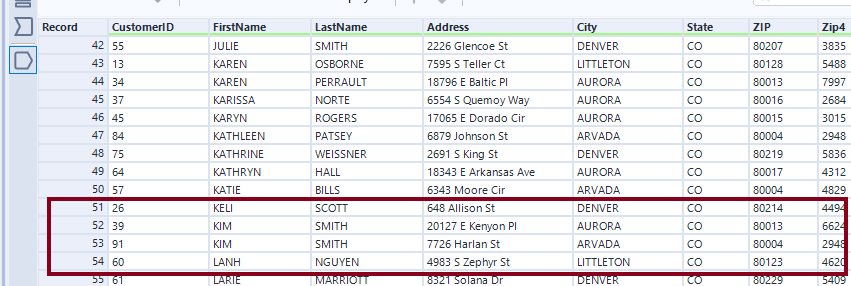
In order to make sure we have a list of different people, let’s add “Address” to our configuration selection. This way we will get a unique combination of both names and addresses. In the D output of the unique tool in the “Multiple Unique Groupings” section, we now have 5 records, and the name Kim Smith is now featured twice in the U output.