


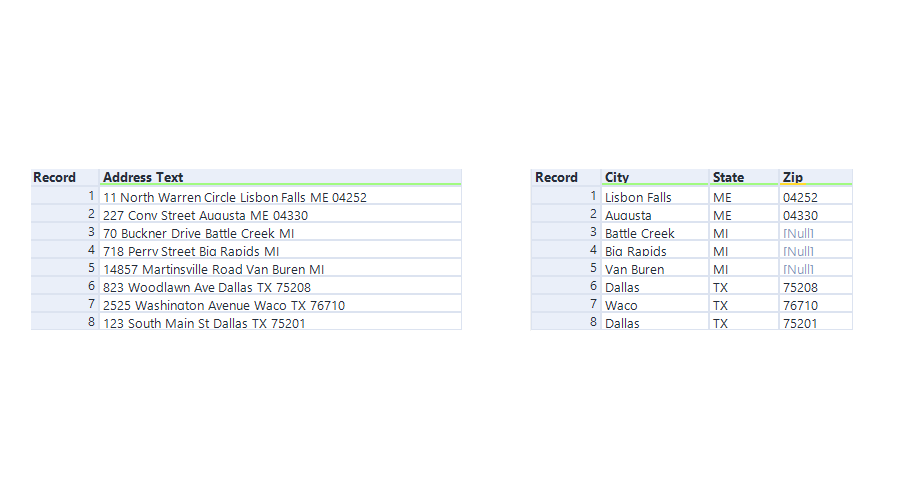
We were introduced to using Regex a few days ago which was a daunting but overall positive experience. Regex stands for ‘Regular Expressions’ and can be used to extract patterns from strings. This becomes incredibly useful when cleaning messy data, especially when the data has patterns that can be followed to extract meaningful information. Alteryx Weekly Challenge #58 focuses on address parsing, which required us to extract the state, postcode, and city from a number of addresses. The input and output can be seen below:
We were advised that the best way to tackle Regex problems is to write out a workflow, which can then be translated to alteryx and implemented in a methodical way. The following steps & identified patterns I found can be found below:
- Extract the zip, which is a: space + 5 digits
- Extract State: 2 capital letters
- Extract City, which I did by replacing any of ‘Circle, Street, Drive, Road, Ave, Avenue, St’ with a delimiter, then splitting the columns

Since we are very new to Regex, I decided to extract the easiest element first, which was the postcode. The postcode was 5 digits, found at the end of the line. Attempting to extract any 5 digits resulted in extracting unwanted digits from record 5, therefore my regex expression added a space, meaning that it would only match the 5 digits if there was a space before them. The expression was: \s(\d\d\d\d\d).
Next, I used a regex replace function to tackle the more challenging element of the challenge; isolating the unwanted information (house number, and street name). To do this, I used a simple regex expression that searched for any of the indicators that told me it was a street name. I then combined this with a space at the end of the statement to prevent the regex from replacing the ‘st’ in ‘Augusta’. This final expression was: Circle|Avenue|Street|Drive|Road|Ave|St\s.
After completing this step, I used a split to columns to remove the unwanted house number and street name, I felt like this was partially cheating but the workaround was effective. After cleaning up the column names with a select tool, I moved on to extracting the State and City name, which proved to be very challenging.
Firstly, I stripped one of my columns with all digits, leaving me with just the City and State in one column. Extracting the state was easy, considering the pattern is simply any 2 uppercase letters. This was achieved using the Regex parse tool with: ([A-Z]{2}).
Extracting just the city was quite difficult, since I was unsure how to tailor an expression to split the state from the city. Therefore, I used a regex replace tool to then replace the state with a blankspace. This used the same expression as above, leaving me with just the City in one column.
Finally, I used a data cleansing tool to remove all leading and trailing white-space, and then a select tool to rename column names. This gave me the final output! It was a stressful process and I am still quite hesitant with Regex, but writing out a clear order of work helped pull me through!