


As Data engineers a common challenge once your code is set up to extract and load data is that you need it to run repeatedly to keep data fresh, for example, scheduled at night when server capacity is available. You may also need dependency management, ensuring downstream jobs only run if upstream jobs succeed. Manually managing these workflows is tedious, error-prone, and doesn’t scale.
Enter orchestration tools like GitHub Actions. This feature of GitHub solves both these issues, letting you automate your pipelines, schedule tasks, and manage job dependencies all within the same repository that holds your code.

Why use GitHub Actions?
GitHub Actions is part of GitHub and allows you to define when and how your code runs. You can trigger workflows:
- On a schedule
- On specific events (like
pushorpull_request) - Manually
This has several benefits for data engineers:
- Automation and scheduling – your pipelines run even when you’re away
- Dependency management – downstream jobs only execute if upstream jobs succeed.
- Collaboration and reproducibility – if your code can run on the cloud via GitHub Actions, others can run it.
- Version control for workflows – YAML files live alongside your code, so changes are tracked collaboratively.
Error detection before production – you can run actions on DEV branches allowing you to test your scripts work in the cloud environment means you catch issues before going to prod.
Step 1: Setting Up Environments and Secrets
Before running workflows that require credentials, you need to store secrets safely:
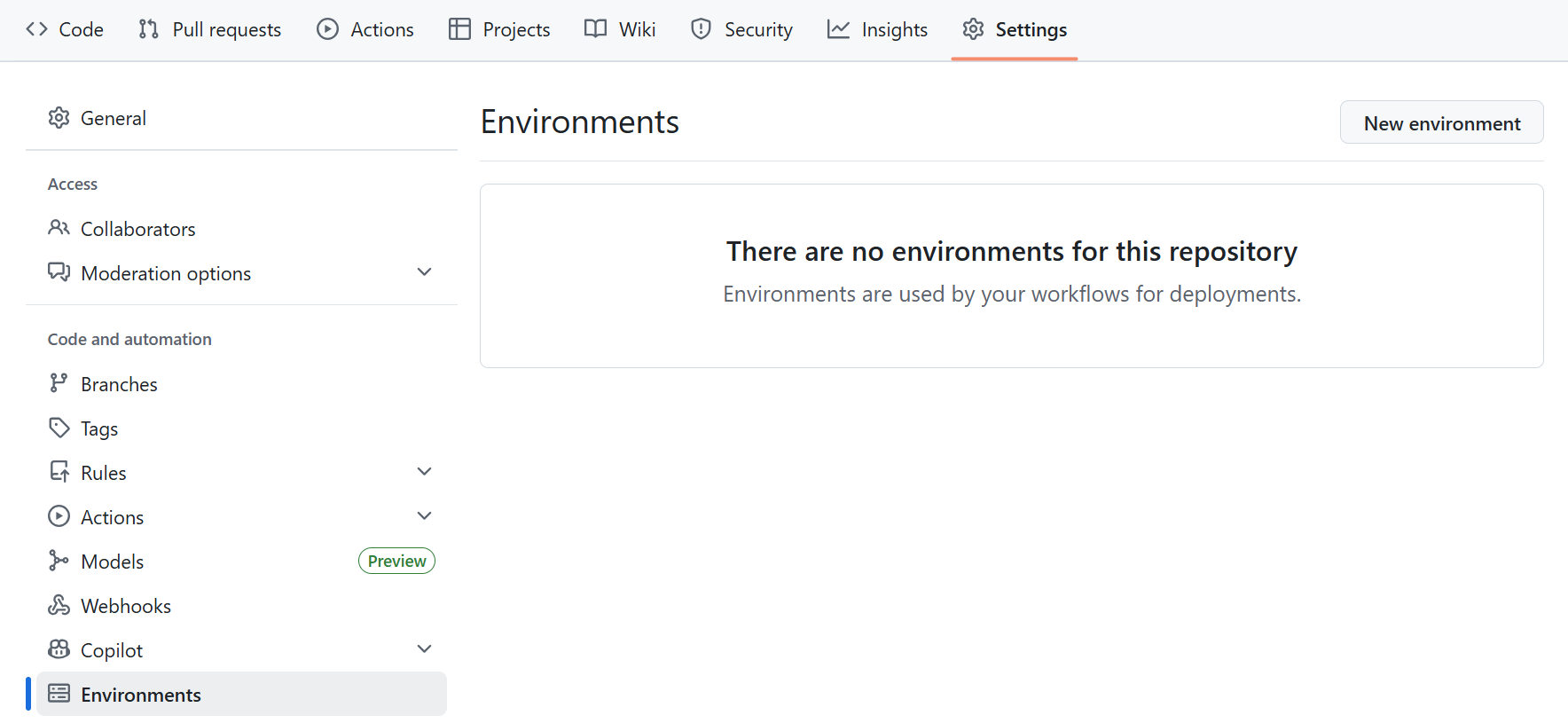
- Navigate to your repository.
- Go to Settings → Environments.
- Create a new environment (e.g.,
dev,uat,prod). - Add secrets (API keys, passwords, buckets). Do not put quotes around values.
These secrets can then be referenced in your workflow YAML.
Step 2: Creating a Workflow
Workflows are defined in YAML files under .github/workflows/. Click into the actions Tab and then, create new workflow to open up a script. Note : Indentation is key here, 2 spaces per level.
Here’s the structure we will follow:
name: Data Pipeline Workflow
on:
Trigger on schedule:
- cron: '* * * * *'
Trigger manually
workflow_dispatch:
jobs:
name:– gives your workflow a name.on:– defines when it triggers (scheduled and/or manual).jobs:– defines what you want to happen
Step 3: Defining Jobs

You can have multiple jobs running in parallel or dependent on each other. Here’s an example:
jobs:
build:
runs-on: ubuntu-latest
steps:
# Steps go here
jobs:– top-level section for tasks.build:– is the name/ID of a job (can be called anythingtest,deploy,ingest-data, etc.).runs-on:– specifies the virtual environment (Ubuntu, Windows, macOS).
Step 4: Adding Steps

Steps are the individual actions the job performs. Each step can run shell commands denoted by "run:" or use prebuilt GitHub Actions denoted by "uses:"
Example workflow steps:
steps:
- name: Checkout the repo
uses: actions/checkout@v2
- name: Setup Python
uses: actions/setup-python@v4
with:
python-version: '3.12.10'
- name: Install packages
run: pip install -r requirements.txt
- name: Run the Python script
env:
SECRET_KEY: ${{secrets.SECRET_KEY}}
run: python script.py
Explanation:
- Checkout the repo – downloads code to the runner.
- Setup Python – installs a specific Python version.
- Install packages – ensures dependencies are available.
- Run script – sets environment variables from secrets, then executes the data pipeline.
Other YAML Steps
- you can use ID to define a step and then it can be referenced as part of another set – see example:
- id: get_version"
run: echo "version=1.0.0" >> $GITHUB_OUTPUT
- run: echo "Version is ${{ steps.get_version.outputs.version }}
- you can use if to specify a conditional execution:
- run: echo "Only runs on main branch"
if: github.ref == 'refs/heads/main'
- Continue on error:
- run: flaky-command
continue-on-error: true
- Timeouts:
- run: long-task
timeout-minutes: 10
Step 6: Managing Job Dependencies
To ensure downstream jobs run only if upstream jobs succeed, use needs::
jobs:
build:
runs-on: ubuntu-latest
steps:
- run: echo "Building..."
test:
needs: build
runs-on: ubuntu-latest
steps:
- run: echo "Testing..."
needs: build–testruns only ifbuildsucceeds.- This allows orchestration of multiple workflows, just like a production ETL pipeline.
Conclusion
GitHub Actions lets data engineers automate, schedule, and orchestrate pipelines safely and reliably:
- Schedule tasks to run automatically, even when you’re away.
- Ensure jobs run in the correct order using dependencies.
- Collaborate with version-controlled YAML workflows.
- Catch errors early in branches before production automation.
With a simple yawl file, you can turn a manual data pipeline into a fully automated orchestration, freeing up time for analysis and innovation!