


In der Data School lernen wir schnell: Die Art, wie wir Daten verknüpfen, entscheidet über den Erfolg der Analyse. Besonders auf dem Tableau Server ist die richtige Strategie entscheidend, um nicht im Chaos zu versinken.
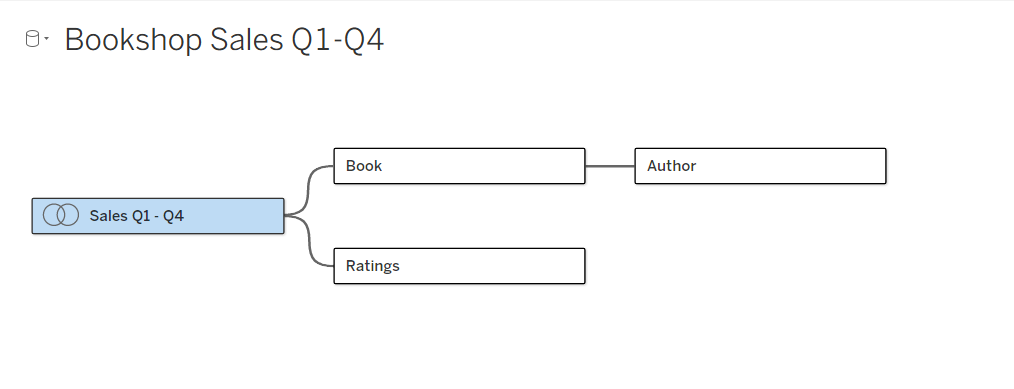
Relationships vs. Joins: Flexibilität auf zwei Ebenen
Relationships
Relationships sind die Standardmethode und können in den meisten Fällen verwendet werden – auch bei Tabellen mit unterschiedlichen Detaillierungsebenen. Beziehungen sind flexibel und passen sich auf jedem Arbeitsblatt individuell an die Struktur der Analyse an. Es ist jedoch nicht möglich, Beziehungen zwischen Tabellen aus veröffentlichten Datenquellen zu erstellen.
Joins
Joins kombinieren Tabellen, indem sie zusätzliche Datenspalten bei ähnlichen Zeilenstrukturen hinzufügen. Dies kann zu Datenverlust oder Duplikaten führen, wenn die Tabellen unterschiedliche Detaillierungsebenen aufweisen. Zudem müssen Joins festgelegt werden, bevor die Analyse beginnen kann. Veröffentlichte Datenquellen können nicht in einem Join verwendet werden.
Logical vs. Physical
Moderne Datenmodelle in Tableau nutzen den Logical Layer (logische Ebene). Hier erstellst du Relationships. Die Tabellen bleiben eigenständig und werden erst während der Analyse dynamisch verknüpft. Gehst du eine Ebene tiefer – durch einen Doppelklick – landest du im Physical Layer (physische Ebene). Hier finden klassische Joins statt, die Tabellen zusammenfügen und erweitern. Oft sind diese Joins hilfreich, wenn du deine FACT-Tables erstellen möchtest.
Während früher fast ausschließlich mit Joins gearbeitet wurde, bieten Relationships heute eine wesentlich flexiblere Basis. Bei einer Relationship bleiben die Tabellen eigenständig und werden nicht schon beim Import zu einer riesigen Tabelle verschmolzen. Tableau erkennt erst während der Analyse, welche Verknüpfung für die aktuelle Visualisierung notwendig ist. Das schont die Ressourcen der Datenbank, weil kein Kennzahlen durch unterschiedliche Detailgrade ungewollt vervielfacht werden.
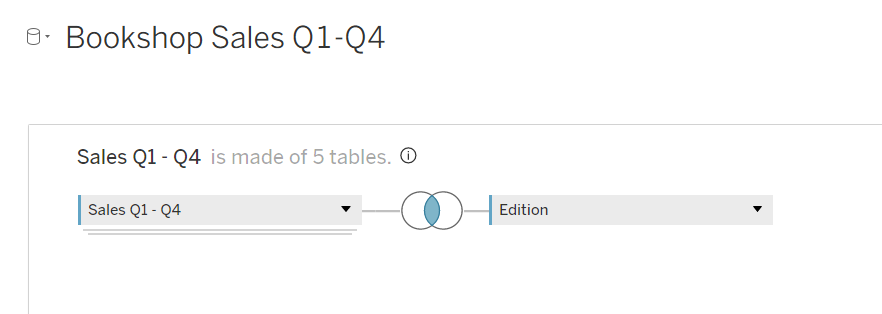
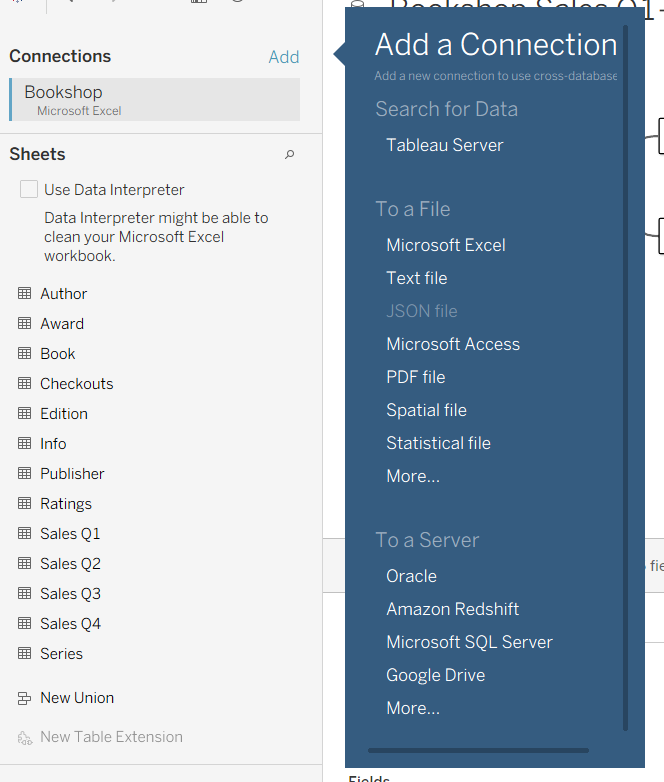
Cross-Joins via “Add Connection”
Doch was passiert, wenn wir über verschiedene Datenbanken hinweg arbeiten müssen? Hier kommt der Cross-Database Join ins Spiel. Über die Funktion "Add Connection" binden wir unterschiedliche Quellen wie SQL-Datenbanken und Excel-Dateien in ein Modell ein. Das ist besonders wertvoll, wenn wir eine integrierte Datengrundlage schaffen wollen, bevor die Analyse im Dashboard beginnt.
Data Blending
Eine weitere Methode ist das Data Blending. Im Gegensatz zum Join oder der Relationship findet das Blending erst nach der Aggregation der Daten statt. Das ist oft die letzte Rettung, wenn wir auf bereits veröffentlichte Datenquellen auf dem Tableau Server zugreifen, die sich nicht direkt auf logischer Ebene verknüpfen lassen. Blending funktioniert wie ein Left Join nach der Berechnung und ist ideal für schnelle Vergleiche, kann aber bei sehr großen Datenmengen an seine Grenzen stoßen.

Blends (Datenverschmelzung)
Blends kombinieren die Daten im Gegensatz zu Beziehungen oder Joins niemals direkt. Stattdessen fragt ein Blend jede Datenquelle unabhängig ab, aggregiert die Ergebnisse auf die entsprechende Ebene und stellt sie dann visuell gemeinsam in der Ansicht dar.
- Flexibilität: Blends können daher mit unterschiedlichen Detaillierungsebenen umgehen und funktionieren auch mit veröffentlichten Datenquellen.
- Einschränkung: Ein Blend erstellt keine neue, „verschmolzene“ Datenquelle (und kann daher nicht als solche veröffentlicht werden). Es handelt sich lediglich um verschmolzene Ergebnisse, die pro Blatt visualisiert werden.
Tableau Server
Wenn wir unsere Projekte auf dem Tableau Server veröffentlichen, müssen wir die Balance zwischen Zeit und Erwartungen halten. Ein gut strukturiertes Datenmodell mit Relationships sorgt dafür, dass die Dashboards für den Endnutzer schnell und intuitiv bedienbar bleiben. Es lohnt sich, hier agil vorzugehen: Erst den Kern des Datenmodells als funktionsfähige Basis bauen und dann Schritt für Schritt erweitern, anstatt sich zu früh in hochkomplexen Verknüpfungen zu verlieren.
Am Ende ist die Wahl der richtigen Verbindungsmethode eine Kernkompetenz für jeden Data Consultant. Es geht darum, Ziele zu definieren, die innerhalb des Projekts erreichbar sind. Mit einem klaren Verständnis für die Unterschiede zwischen Relationships, Joins und Blending entwickeln wir uns stetig weiter und schaffen Visualisierungen, die nicht nur schön aussehen, sondern auf einem soliden, technischen Fundament stehen.