


Web scraping can be a really useful tool in order to get public information and enrich your own data to provide more context!
Before you Web scrape the important question to ask yourself is, "Is this ethical?" Just because something is public doesn't mean that the owner will be okay with you collecting and storing a backlog of information about them. make sure you are sure that the information you are obtaining is legal to obtain and that the owner will have no problems with you using it.
For this demonstration I will be using https://quotes.toscrape.com/
The first thing we need in Alteryx is a text input with the link to the website we want to scrape.
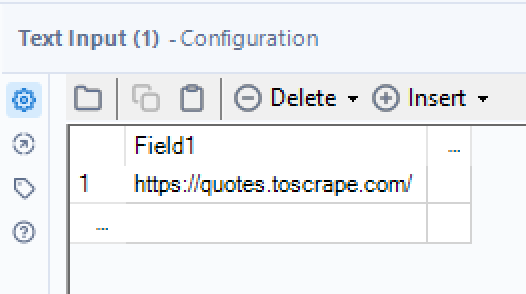
After we have created this, we will use the download tool to extract the information., setting the download tool to extract from "Field 1"
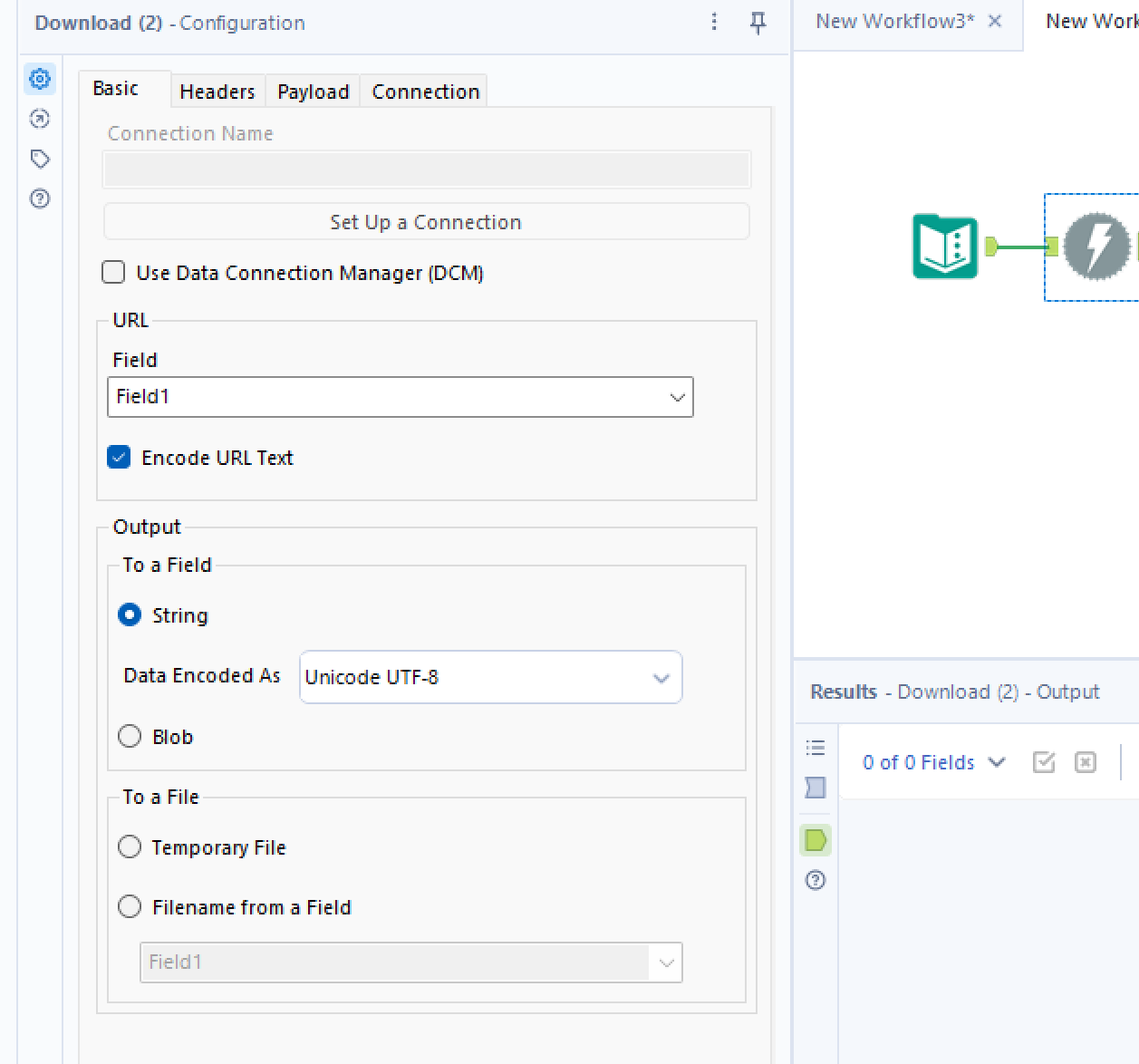
We will right click on download and select "Cache and run flow" so that we don't hit the website every time we want to run the flow, we only download the website once.
We will also input a browse tool to have a look at the data we have downloaded
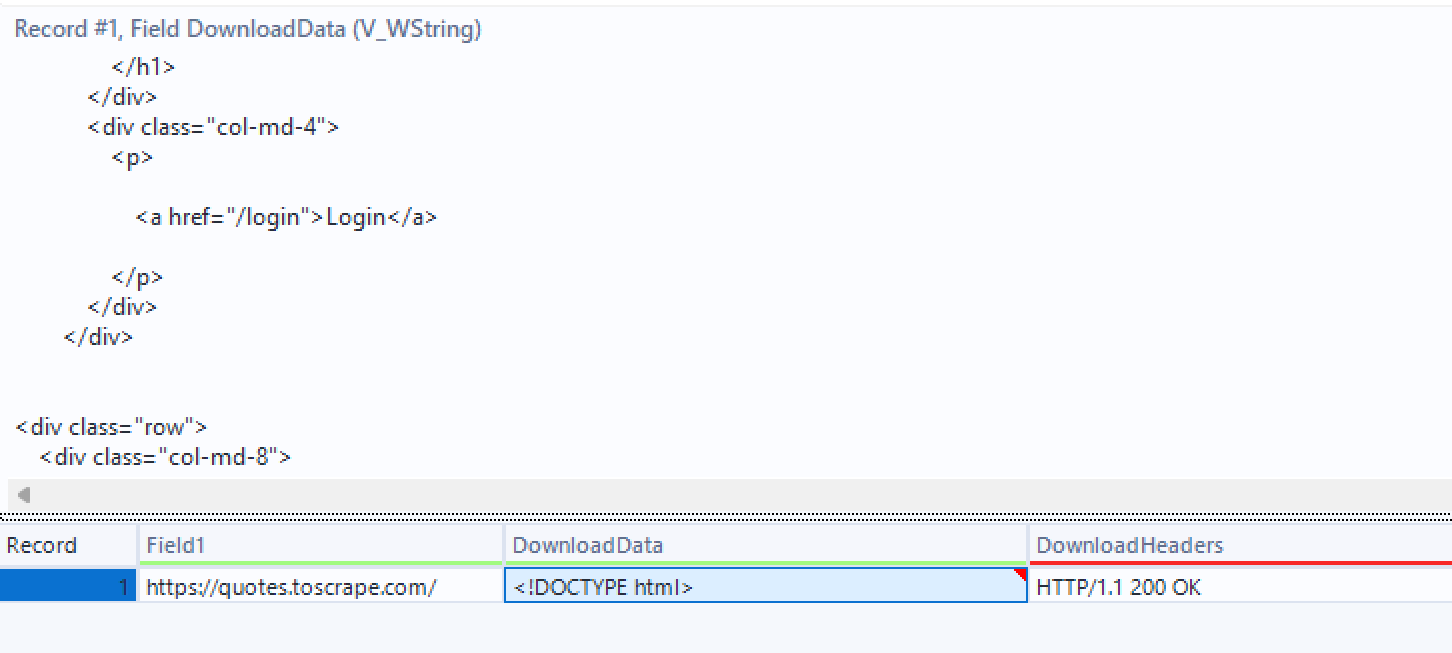
What we can see is we've downloaded the HTML for the website.
If for this example I wanted to extract the quotes
The first thing I need to do is inspect the website to see what in the HTML will give me my quotes.
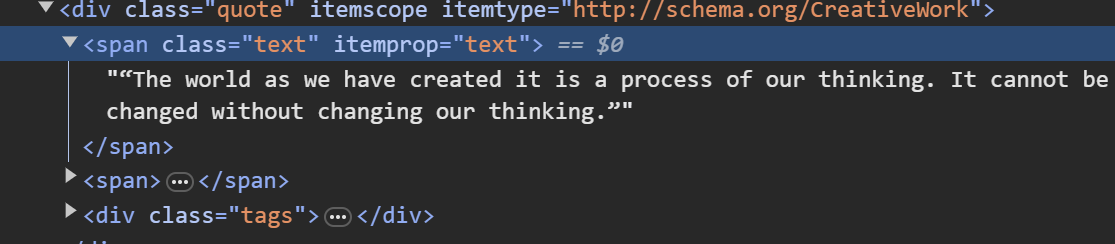
I can see that my quotes in the HTML is surrounded by these "<span" characters
So we will use REGEX to extract what is in between these span characters
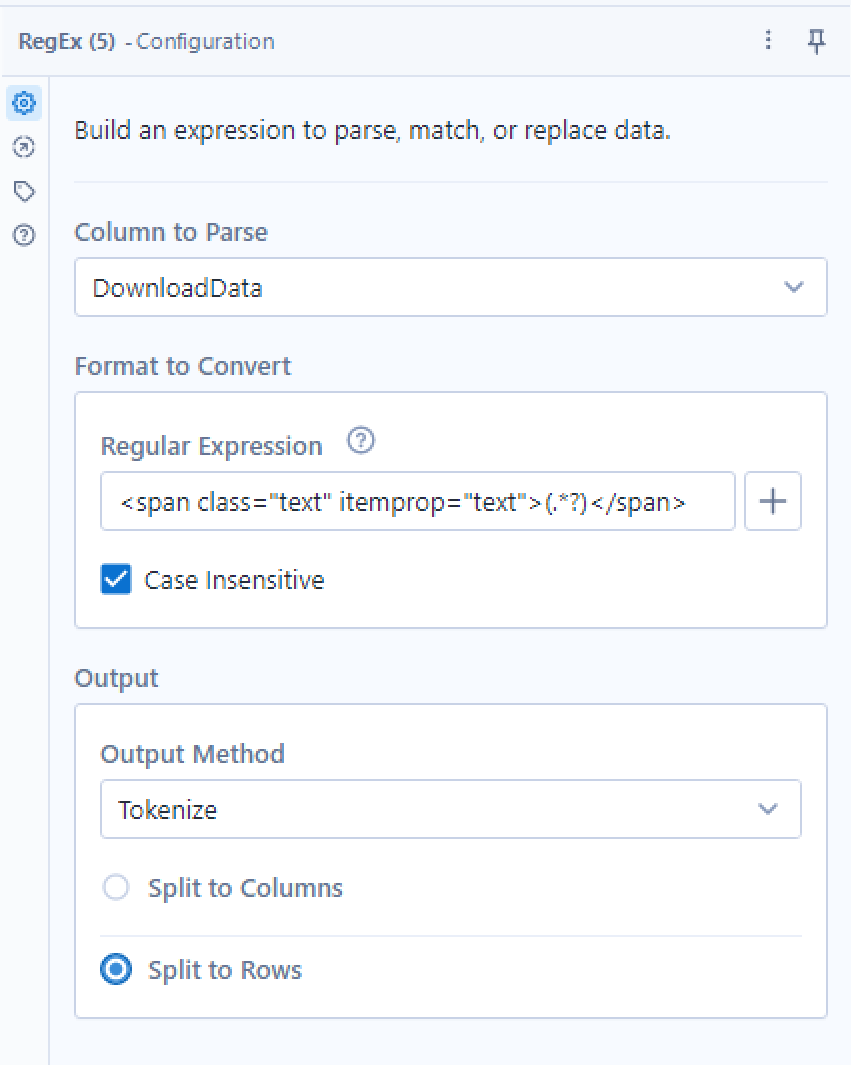
This REGEX expression just says to look for the first section then the (.*?) says to look for everything after until you reach the </span>
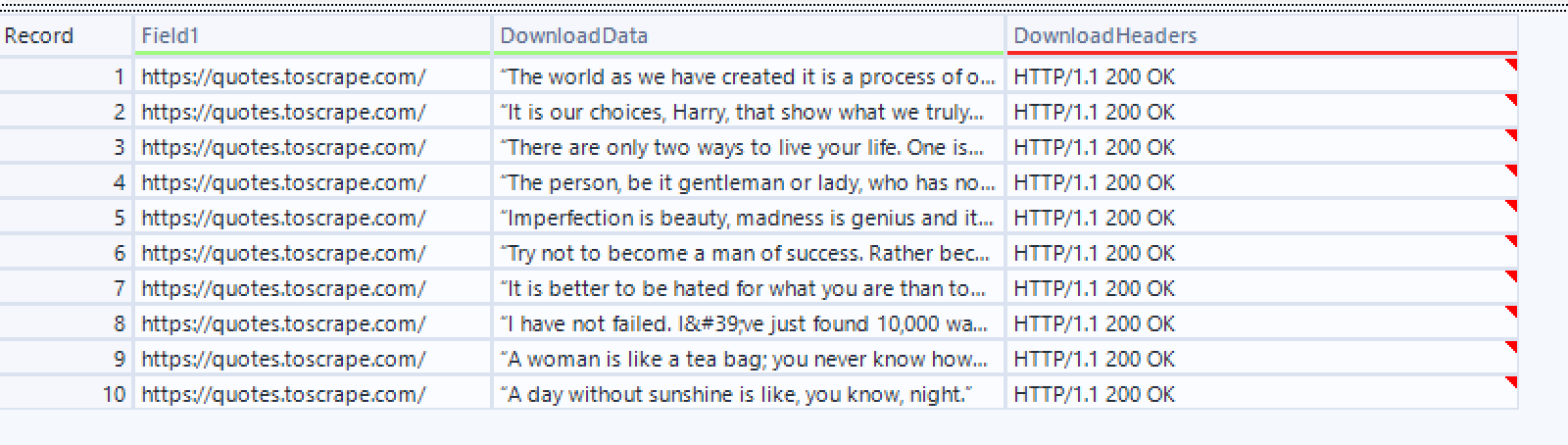
And you can see by Tokenising to rows we have extracted every quote on a new Row.