


Die Datenaufbereitung ist ein kritischer und zeitaufwendiger, aber unverzichtbarer Bestandteil der Arbeit eines Data School Consultants. Sie ist die Grundlage für valide und aussagekräftige Analysen. Durch die sorgfältige Anwendung der ETL Schritte und den Einsatz geeigneter Tools können wir Data School Consultants sicherstellen, dass unsere Analysen auf soliden Daten basieren und wertvolle Erkenntnisse liefern. Datenaufbereitung ist somit nicht nur ein notwendiger Schritt, sondern vielmehr der Schlüssel zum Erfolg in der Welt der Datenanalyse. Mit diesem Post möchte ich eine Übersicht über die einzelnen Schritte im ETL Prozess liefern.
(E)xtract
Im ersten Schritt der Datenaufbereitung benötigen wir unseren Datensatz bzw. unsere Datensätze. Aus einer oder mehreren Datenbanken tragen wir unsere Rohdaten zusammen. Dies kann kontinuierlich geschehen (die Datensätze werden ständig aktualisiert), oder über geplante Updateprozesse passieren (z.B. jeden Morgen um 4:30 Uhr, zwei mal wöchentlich etc.). Letzteres spart Ressourcen, da unsere nachgelagerten Anwendungen und Abläufe nicht ständig mit neuen Daten versorgt werden, sondern einen Snapshot nutzen. Voraussetzung für eine erfolgreiche Extraktion unsere Daten ist natürlich, dass unsere Klienten uns Zugang zu ihren Datenbanken gewähren.
(T)ransform
Haben wir Zugriff auf die Datenquellen und alle relevanten Datensätze zusammengetragen, können wir mit der Umwandlung unserer Rohdaten in eine einheitliche Struktur beginnen. Hier möchten wir so genau wie möglich arbeiten, denn nun schaffen wir uns unser Fundament für die Datenanalyse. Wir achten darauf, dass die richtigen Datentypen definiert sind, unsere Tabellen keine fehlerhaften Daten oder Duplikate enthalten. Leere Werte werden sinnvoll ersetzt, um eine einheitliche Struktur zu gewährleisten. Beispielsweise können zwei Datensätze Datumsangaben enthalten, die in einem Datensatz als Datetime (Datum und Uhrzeit, 2025/01/22 08:46:34) und im anderen als Date (Datum ohne Uhrzeit, 2025/01/22) Typ definiert sind. Hier wollen wir, unter Berücksichtigung der folgenden Datenanalyse, eine einheitliches Format für unsere Datumsspalten herstellen.
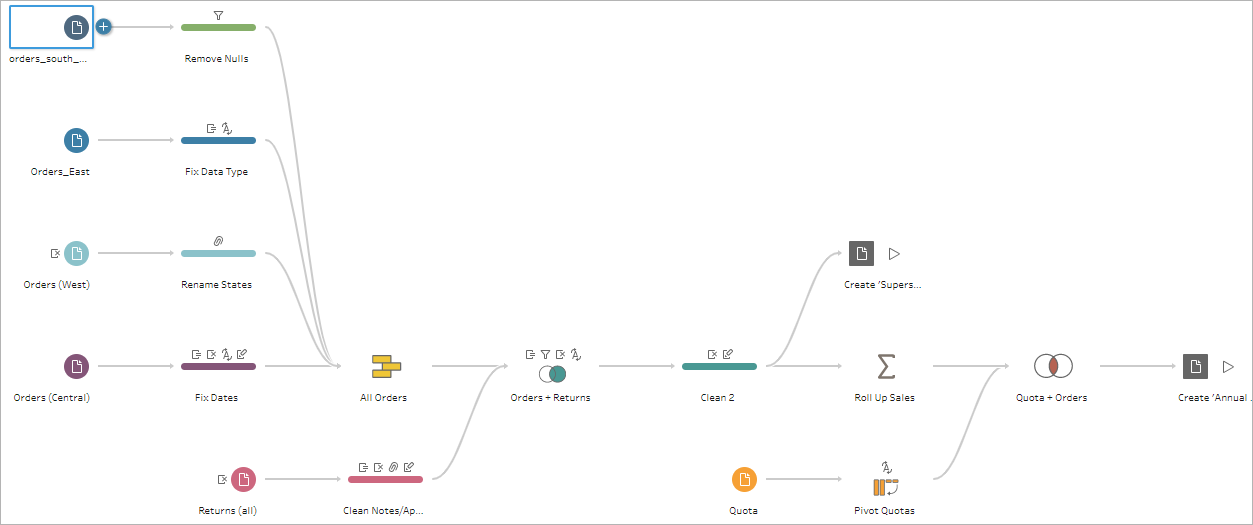
Wie im Beispiel zu erkennen ist, können an verschiedenen Punkten des Flows Dateien ausgegeben werden. Somit können viele verschiedene Versionen und Abschnitte einer Datenquelle gespeichert und für die anschließende Analyse genutzt werden. Ein wichtiger Teil in diesem Schritt ist die Prüfung der Transformationsergebnisse hinsichtlich ihrer Plausibilität. Um eventuelles Troubleshooting zu beschleunigen ist es ebenfalls hilfreich, die einzelnen Schritte im Flow zu beschreiben und als Dokumentation zu nutzen.
(L)oad
Im letzten Schritt werden die aufbereiteten und transformierten Daten bereitgestellt. In modernen ETL Prozessen finden die Datensätze einen Platz im Datawarehouse. Beim erstmaligen Bereitstellen wird i.d.R. der gesamte aufbereitete Datensatz geladen. Oftmals findet in der Folge ein inkrementeller Upload statt, der nur die Differenz aus beiden Datenzuständen ausgleicht. Wie auch immer die Daten am Ende geladen werden, sie bilden die unerlässliche Grundlage für eine aussagekräftige visuelle Analyse.