Batch Upsert Thousands of Rows from Alteryx to a SharePoint List using Python
Why bother?
SharePoint Lists provide a secure way to share data with specific user groups via API, with granular access controls and advantages over file-based shares. But connecting to them requires the right approach. While Alteryx offers a native SharePoint connector with broad functionality, it might not provide all the customization that's needed. When processing thousands of items daily in production, you may require finer control over batch operations, retry logic, and error handling than the official connector provides.
Here's a customizable solution for syncing thousands of Alteryx rows to a SharePoint List using the Python tool. It leverages Microsoft Graph API's $batch endpoint (20 items per request, as suggested by Microsoft), OAuth 2.0 authentication, and a retry logic with exponential backoff (see below) for handling 429/503 errors. The 2 scripts respect rate limits via the server's Retry-After header. Logging integrates nicely with Alteryx's native logs and 2 debug outputs are sent downstream in Alteryx. The scripts use only standard packages (requests, pandas, ayx) likely already available on your Alteryx Server, providing a starting point for SharePoint List integration.
The Plan
The goal is to schedule a workflow that syncs Alteryx data with a SharePoint List, so the list reflects exactly the rows present in Alteryx with all their fields. For the complete sync process, we'll end up with 2 Python tools in Alteryx, run sequentially after each other. For the syncing to work, the ShP List needs a unique row identifier. This blog assumes a unique column is set up with the name Title.
Script 1) Delete ShP items not present in the Alteryx data
Script 2) Perform batch upsert (update if present, insert if not)
Deletion and Upsert Scripts (to be Run in Sequence)
Authentication
A clean way to programmatically access the Graph API in production is to use the OAuth 2.0 client credentials flow. This means an Azure app needs to be created in the Azure portal, providing client id & client secret values. The script will then use these credentials to obtain a bearer token, which will be used to authorize the Graph API requests.
A SharePoint List lives in a SharePoint Site. Once the Azure app is created, 2 additional things are needed for it to access the list/site in a safe, least-privileges setup:
a) Azure Portal > App Registrations > (search for & select your app by name) > API permissions > Add a permission > Microsoft Graph > Application permisions > Sites.Selected > Add > "Grant admin consent for <tenant>"
b) Ask an Azure admin with access the target ShP Site (or a ShP admin) to run these PowerShell commands:
# This will open a browser window for the admin to sign inConnect-MgGraph-Scopes"Sites.FullControl.All"# Get the composite site ID$site = Get-MgSite-SiteId"your_tenant.sharepoint.com:/sites/your_site_name"Write-Host"Site ID found: $($site.Id)"# Define the permission parameters$params = @{
roles = @("write")
grantedToIdentities = @(
@{
application = @{
id = "your_app_client_id"
displayName = "your_app_name"
}
}
)
}
# Grant the permissionNew-MgSitePermission-SiteId$site.Id-BodyParameter$params# Verify it workedGet-MgSitePermission-SiteId$site.Id | Where-Object { $_.GrantedToIdentities.Application.Id -eq "your_app_client_id" }
Script 1) List Cleanup
Let's have a look at the deletion script. What does it do? It
reads incoming Alteryx data
authenticates via Graph API & gets all items from ShP List
compares incoming and present data using a unique field
deletes all items from the ShP List that don't match the incoming data
To get the script to work, some details need to be entered:
Change the unique_field to match the internal name of the unique 'main' field of your ShP List (primary key). The site_id is a composite id. Either concatenate it from its pieces or fetch the whole id like so:
GET https://graph.microsoft.com/v1.0/sites/your_tenant.sharepoint.com:/sites/your_site_name
################################## Configuration#################################from ayx import Alteryx
import pandas as pd
import requests
import time
from datetime import datetime
CONFIG = {
"tenant_id": "your_tenant_id",
"client_id": "your_client_id",
"client_secret": "your_client_id",
"site_id": "your_tenant.sharepoint.com,your_site_collection_id,your_list_id",
"list_id": "your_list_id",
"unique_field": "Title", # Match the list's title field"batch_size": 20, # Items per batch
}
# Logging Configdeflog_info(message):
timestamp = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
log_entry = f"[OK] [{timestamp}] | INFO | PYTHON DELETE | {message}"
print(log_entry)
deflog_error(message):
timestamp = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
log_entry = f"[X] [{timestamp}] | ERROR | PYTHON DELETE | {message}"
print(log_entry)
Main Functions
authenticate() - exchanges app credentials for bearer token get_existing_items() - fetches all ShP List items batch_delete_items() - deletes ShP List items in batches of 20 make_request() - API wrapper with retry logic
Retry logic and delay according to exponential backoff pattern (3 retries default) and depending on API error code:
Scenario
Wait Strategy
Example Delays
Success (200/201/204)
Return immediately
-
Throttled (429)
Use Retry-After header
10s (as specified by server)
Service Error (503/504)
Exponential backoff (capped at 30s)
1s → 2s → 4s → 8s → 16s → 30s
Other Errors
Exponential backoff (uncapped)
1s → 2s → 4s → 8s → 16s → 32s...
Max Retries
Raise exception
-
################################## Definitions#################################defauthenticate(config):
"""Get access token for Graph API."""
token_url = f"https://login.microsoftonline.com/{config['tenant_id']}/oauth2/v2.0/token"
response = requests.post(
token_url,
data={
"client_id": config["client_id"],
"client_secret": config["client_secret"],
"scope": "https://graph.microsoft.com/.default",
"grant_type": "client_credentials",
},
timeout=30,
)
if response.status_code == 200:
token = response.json().get("access_token")
if token:
return token
raise Exception(f"Authentication failed: {response.text}")
defmake_request(method, url, headers, retries=3, **kwargs):
"""Make HTTP request"""for attempt in range(retries):
try:
response = requests.request(method, url, headers=headers, **kwargs)
if response.status_code in [200, 201, 204]:
return response
# Handle throttlingif response.status_code == 429:
retry_after = int(response.headers.get("Retry-After", 10))
log_info(f"Throttled. Waiting {retry_after}s...")
time.sleep(retry_after)
continue# Handle service errorsif response.status_code in [503, 504]:
wait_time = min(2 ** attempt, 30)
log_error(f"Service error. Retry in {wait_time}s...")
time.sleep(wait_time)
continue
response.raise_for_status()
except Exception as e:
if attempt == retries - 1:
raise
time.sleep(2 ** attempt)
raise Exception("Max retries exceeded")
defget_existing_items(base_url, site_id, list_id, headers, unique_field):
"""Retrieve all existing items from SharePoint List."""
items = {}
url = f"{base_url}/sites/{site_id}/lists/{list_id}/items?$expand=fields&$top=999"
log_info("Fetching existing SharePoint items...")
page_count = 0while url:
page_count += 1
response = make_request("GET", url, headers)
data = response.json()
# Process itemsfor item in data.get("value", []):
if unique_field in item.get("fields", {}):
title = str(item["fields"][unique_field])
items[title] = item["id"]
# Get next page URL
url = data.get("@odata.nextLink")
if url:
time.sleep(0.2) # Small delay between pages
log_info(f"Found {len(items)} items across {page_count} pages")
return items
defbatch_delete_items(base_url, site_id, list_id, headers, item_ids, batch_size=20):
"""Delete items from SharePoint in batches using Graph API batch endpoint."""ifnot item_ids:
return pd.DataFrame()
results = []
total_batches = (len(item_ids) + batch_size - 1) // batch_size
log_info(f"Deleting {len(item_ids)} items in {total_batches} batches...")
for batch_num in range(total_batches):
start_idx = batch_num * batch_size
end_idx = min(start_idx + batch_size, len(item_ids))
batch_ids = item_ids[start_idx:end_idx]
# Build batch request
batch_requests = [
{
"id": str(i),
"method": "DELETE",
"url": f"/sites/{site_id}/lists/{list_id}/items/{item_id}",
"headers": {"If-Match": "*"}
}
for i, item_id in enumerate(batch_ids)
]
# Send batch requesttry:
response = make_request(
"POST",
f"{base_url}/$batch",
headers,
json={"requests": batch_requests}
)
batch_response = response.json()
# Process responsesfor i, resp in enumerate(batch_response.get("responses", [])):
status_code = resp.get("status", 0)
results.append({
"item_id": batch_ids[i] if i < len(batch_ids) else"unknown",
"status": "success"if status_code == 204else"failed",
"status_code": status_code,
"batch": batch_num + 1
})
except Exception as e:
log_error(f"Deletion Batch {batch_num + 1} error: {str(e)}")
for item_id in batch_ids:
results.append({
"item_id": item_id,
"status": "failed",
"status_code": 0,
"error": str(e),
"batch": batch_num + 1
})
Execution
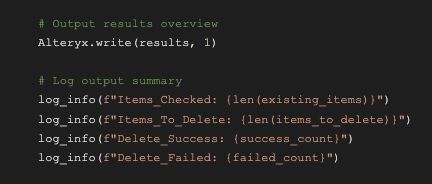
The execution part runs the functions from above, all wrapped in one big try/except block. In case of an error, it will get logged to Alteryx. An overview of successes and failures is both logged and output to the anchor 1:
################################## Execution#################################try:
log_info("SharePoint List Cleanup - Delete Items Not in Today's Data")
# Read input data from Alteryx
input_data = Alteryx.read("#1")
unique_field = CONFIG["unique_field"]
# Validate unique field existsif unique_field notin input_data.columns:
raise Exception(f"Column '{unique_field}' not found in input data")
# Get unique values from today's data
todays_values = set(input_data[unique_field].astype(str).unique())
log_info(f"Today's data contains {len(todays_values)} unique rows")
# Authenticate
log_info("Authenticating...")
token = authenticate(CONFIG)
# Setup headers
headers = {
"Authorization": f"Bearer {token}",
"Content-Type": "application/json",
}
base_url = "https://graph.microsoft.com/v1.0"# Get existing items from SharePoint
existing_items = get_existing_items(
base_url,
CONFIG["site_id"],
CONFIG["list_id"],
headers,
unique_field
)
# Identify items to delete (exist in SharePoint but not in today's data)
items_to_delete = []
for title, item_id in existing_items.items():
if title notin todays_values:
items_to_delete.append(item_id)
log_info(f"Items to delete: {len(items_to_delete)} of {len(existing_items)}")
# Perform deletion if neededif items_to_delete:
results = batch_delete_items(
base_url,
CONFIG["site_id"],
CONFIG["list_id"],
headers,
items_to_delete,
CONFIG["batch_size"]
)
# Calculate statistics
success_count = len(results[results["status"] == "success"])
failed_count = len(results[results["status"] == "failed"])
log_info(f"Deletion Complete - Success: {success_count}, Failed: {failed_count}")
# Show failed items if anyif failed_count > 0:
failed = results[results["status"] == "failed"]
log_error("Failed deletions (first 5):")
for _, row in failed.head(5).iterrows():
log_error(f" Item ID {row['item_id']}: Status {row['status_code']}")
# Output results overview
Alteryx.write(results, 1)
# Log output summary
log_info(f"Items_Checked: {len(existing_items)}")
log_info(f"Items_To_Delete: {len(items_to_delete)}")
log_info(f"Delete_Success: {success_count}")
log_info(f"Delete_Failed: {failed_count}")
else:
log_info("No items to delete - all SharePoint items are in today's data")
# Log empty output summary
log_info(f"Items_Checked: {len(existing_items)}")
log_info("Items_To_Delete: 0")
log_info("Delete_Success: 0")
log_info("Delete_Failed: 0")
except Exception as e:
log_error(f"X ERROR: {str(e)}")
error_df = pd.DataFrame([{
"Error": str(e),
"Timestamp": datetime.now()
}])
Alteryx.write(error_df, 1)
raise
Script 2) Batch Upsert Operation
The first script has already removed all stale items from the ShP List. So we don't have to worry about removal from ShP anymore. So, after reading incoming Alteryx data & authenticating, this second script now
updates existing ShP items that match (PATCH request)
creates new items that don't exist in SharePoint (POST request)
does so in batches of 20 via Graph API $batch endpoint
returns detailed results per item + summary statistics to Alteryx
In case of upsert failures: The returned per-item data set (anchor 1) can be joined back to the original data in Alteryx if needed, to be run as often as needed until no rows with failure statuses are left.
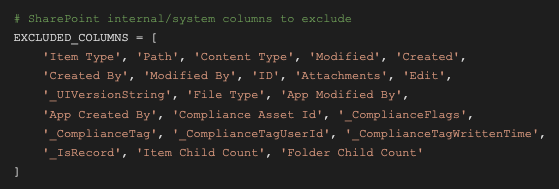
The upsert script's configuration part follows the same schema as the deletion script. Additionally, a list of columns to ignore from the incoming data can be defined here. Handy if the incoming Alteryx data itself is from a ShP List. This will likely need some trial-and-error though, and this list is probably unnecessarily long:
################################## Configuration#################################from ayx import Alteryx
import pandas as pd
import numpy as np
import requests
import time
from datetime import datetime
# get from environment variables in prod
CONFIG = {
"tenant_id": "your_tenant_id",
"client_id": "your_client_id",
"client_secret": "your_client_id",
"site_id": "your_tenant.sharepoint.com,your_site_collection_id,your_list_id",
"list_id": "your_list_id",
"unique_field": "Title", # Match the list's title field
}
# SharePoint internal/system columns to exclude
EXCLUDED_COLUMNS = [
'Item Type', 'Path', 'Content Type', 'Modified', 'Created',
'Created By', 'Modified By', 'ID', 'Attachments', 'Edit',
'_UIVersionString', 'File Type', 'App Modified By',
'App Created By', 'Compliance Asset Id', '_ComplianceFlags',
'_ComplianceTag', '_ComplianceTagUserId', '_ComplianceTagWrittenTime',
'_IsRecord', 'Item Child Count', 'Folder Child Count'
]
# Logging Configdeflog_info(message):
timestamp = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
log_entry = f"[OK] [{timestamp}] | INFO | PYTHON UPSERT | {message}"
print(log_entry)
deflog_error(message):
timestamp = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
log_entry = f"[X] [{timestamp}] | ERROR | PYTHON UPSERT | {message}"
print(log_entry)
Main Functions
authenticate() - same as above get_items() - fetches all ShP List items clean_fields_for_sharepoint() - drops unnecessary columns, handles dtypes, NULLs batch_upsert() - upserts cleaned Alteryx fields in batches of 20, returns results df request() - API requests with retry logic
Because this script is slightly longer, the functions are encapsulated in a class this time (SharePointSync()). The advantage is that often needed attributes don't have to be explicitly passed to all of the functions explicitly (e.g. auth header, base url, etc.). They can be set once in the init() function and referenced from anywhere in the class, using the self. prefix.
################################## Definitions#################################defauthenticate(config):
"""Get access token using requests."""
token_url = f"https://login.microsoftonline.com/{config['tenant_id']}/oauth2/v2.0/token"
response = requests.post(
token_url,
data={
"client_id": config["client_id"],
"client_secret": config["client_secret"],
"scope": "https://graph.microsoft.com/.default",
"grant_type": "client_credentials"
},
timeout=30
)
if response.status_code == 200:
result = response.json()
if"access_token"in result:
return result["access_token"]
raise Exception(f"Auth failed: {response.text}")
classSharePointSync:
"""Production SharePoint sync for Alteryx."""def__init__(self, token, site_id, list_id):
self.headers = {
"Authorization": f"Bearer {token}",
"Content-Type": "application/json",
"Prefer": "return=representation"# Add this header for better responses
}
self.base = "https://graph.microsoft.com/v1.0"
self.site_id = site_id
self.list_id = list_id
defrequest(self, method, url, retries=5, **kwargs):
"""HTTP request with retry logic."""for i in range(retries):
try:
r = requests.request(method, url, headers=self.headers, **kwargs)
if r.status_code in [200, 201, 204]:
return r
if r.status_code == 429:
retry_after = int(r.headers.get('Retry-After', 10))
log_error(f"Throttled. Waiting {retry_after}s")
time.sleep(retry_after)
continueif r.status_code in [503, 504]:
wait_time = min(2 ** i, 60)
log_error(f"Service error {r.status_code}. Retry in {wait_time}s")
time.sleep(wait_time)
continue# Log detailed error for debuggingif r.status_code == 400:
log_error(f"Bad Request Error (400): {r.text}")
elif r.status_code == 503:
log_error(f"Service Unavailable (503): {r.text}")
r.raise_for_status()
except Exception as e:
if i == retries - 1:
raise
time.sleep(min(2 ** i, 60))
raise Exception("Max retries exceeded")
defget_items(self):
"""Get all existing items with pagination."""
items = []
url = f"{self.base}/sites/{self.site_id}/lists/{self.list_id}/items?$expand=fields&$top=999"while url:
r = self.request("GET", url)
data = r.json()
items.extend(data.get("value", []))
url = data.get("@odata.nextLink")
if url:
time.sleep(0.3)
return items
defclean_fields_for_sharepoint(self, row_dict):
"""Clean and prepare fields for SharePoint API."""
cleaned = {}
for key, value in row_dict.items():
# Skip excluded columnsif key in EXCLUDED_COLUMNS:
continue# Skip internal columns starting with underscoreif key.startswith('_'):
continue# Handle NaN and None valuesif pd.isna(value) or value isNone:
continue# Handle different data typesif isinstance(value, bool):
cleaned[key] = value
elif isinstance(value, (int, float)):
# Check for infinity using numpyif pd.notna(value) andnot np.isinf(value):
cleaned[key] = float(value)
elif isinstance(value, pd.Timestamp):
cleaned[key] = value.isoformat()
else:
# Convert to string and clean
str_val = str(value).strip()
if str_val and str_val.lower() notin ['nan', 'none', 'null']:
cleaned[key] = str_val
return cleaned
defbatch_upsert(self, source_df, unique_field):
"""Batch upsert DataFrame to SharePoint."""
log_info(f"Processing {len(source_df)} rows")
log_info(f"Input columns ({len(source_df.columns)}): {list(source_df.columns)}")
# Ensure unique field existsif unique_field notin source_df.columns:
raise Exception(f"Unique field '{unique_field}' not found. Available: {list(source_df.columns)}")
# Build lookup of existing items
log_info("Fetching existing SharePoint items...")
existing = self.get_items()
lookup = {}
for item in existing:
if unique_field in item.get("fields", {}):
key = str(item["fields"].get(unique_field))
lookup[key] = {
"id": item["id"],
"etag": item.get("eTag", item.get("@odata.etag", "*"))
}
log_info(f"Found {len(lookup)} existing items in SharePoint")
results = []
batch_size = 20
total_batches = (len(source_df) + batch_size - 1) // batch_size
for batch_num, i in enumerate(range(0, len(source_df), batch_size), 1):
batch_df = source_df.iloc[i:i+batch_size]
batch_requests = []
for idx, (_, row) in enumerate(batch_df.iterrows()):
# Clean fields for SharePoint
fields = self.clean_fields_for_sharepoint(row.to_dict())
# Get unique value for matching
unique_val = str(fields.get(unique_field, ""))
# Debug first itemif i == 0and idx == 0:
log_info(f"First item: Title='{unique_val}'")
log_info(f"Fields to send ({len(fields)}): {list(fields.keys())}")
if unique_val in lookup:
# Update existing item - use correct endpoint format
item_info = lookup[unique_val]
req = {
"id": str(idx),
"method": "PATCH",
"url": f"/sites/{self.site_id}/lists/{self.list_id}/items/{item_info['id']}",
"body": {"fields": fields},
"headers": {
"Content-Type": "application/json",
"If-Match": "*"# Force update regardless of eTag
}
}
else:
# Create new item
req = {
"id": str(idx),
"method": "POST",
"url": f"/sites/{self.site_id}/lists/{self.list_id}/items",
"body": {"fields": fields},
"headers": {"Content-Type": "application/json"}
}
batch_requests.append(req)
# Send batch requesttry:
r = self.request("POST", f"{self.base}/$batch", json={"requests": batch_requests})
batch_response = r.json()
# Process responsesfor resp in batch_response.get("responses", []):
status_code = resp.get("status")
error_msg = ""# Default to empty string instead of Noneif status_code notin [200, 201, 204]:
# Parse error message
error_body = resp.get("body", {})
if isinstance(error_body, dict):
error = error_body.get("error", {})
error_msg = error.get("message", "Unknown error")
else:
error_msg = str(error_body)
# Log first few errors in detailif len([r for r in results if r.get("status") == "failed"]) < 3:
request_id = int(resp.get("id", 0))
if request_id < len(batch_requests):
failed_req = batch_requests[request_id]
method = failed_req['method']
log_error(f"\nError in {method} request (ID {request_id}):")
log_error(f" Status: {status_code}")
log_error(f" Message: {error_msg}")
results.append({
"status": "success"if status_code in [200, 201, 204] else"failed",
"id": resp.get("id"),
"title": batch_df.iloc[int(resp.get("id"))][unique_field] if int(resp.get("id")) < len(batch_df) else"",
"status_code": status_code,
"error": error_msg if error_msg else""
})
except Exception as e:
log_error(f"Batch error: {str(e)}")
for req in batch_requests:
results.append({
"status": "failed",
"id": req["id"],
"status_code": 0,
"error": str(e)
})
# Brief pause between batchesif batch_num < total_batches:
time.sleep(0.5)
return pd.DataFrame(results)
Execution
After wrapping our functions in a class and dipping our toes in OOP in the last part, the execution itself is quite short and straightforward.
################################## Execution#################################try:
log_info("SharePoint List Sync (upsert) starting")
# Read input from Alteryx
input_data = Alteryx.read("#1")
log_info(f"Loaded {len(input_data)} rows from Alteryx")
# Remove any SharePoint-specific columns that might have been included
columns_to_drop = [col for col in EXCLUDED_COLUMNS if col in input_data.columns]
if columns_to_drop:
input_data = input_data.drop(columns=columns_to_drop)
# Authenticate
log_info("Authenticating...")
token = authenticate(CONFIG)
log_info("Authentication successful")
# Initialize sync
sync = SharePointSync(token, CONFIG["site_id"], CONFIG["list_id"])
# Perform batch upsert
log_info("Starting sync...")
results = sync.batch_upsert(input_data, CONFIG["unique_field"])
# Replace any None/NaN values in results with empty strings
results = results.fillna("")
# Calculate statistics
success_count = len(results[results["status"] == "success"])
failed_count = len(results[results["status"] == "failed"])
log_info(f"Sync Complete - Success: {success_count}, Failed: {failed_count}")
# Show specific errors if anyif failed_count > 0:
failed_items = results[results["status"] == "failed"]
log_error("Failed items (first 5):")
for _, item in failed_items.head(5).iterrows():
if item['error']:
log_error(f" ID {item['id']}: {item['error']}")
# Output results to Alteryx
Alteryx.write(results, 1)
# Also output summary
summary = pd.DataFrame([{
"Status": "Completed",
"TotalRows": len(input_data),
"Success": success_count,
"Failed": failed_count,
"Timestamp": datetime.now()
}])
Alteryx.write(summary, 2)
except Exception as e:
log_error(f"ERROR: {str(e)}")
error_df = pd.DataFrame([{
"Error": str(e),
"Timestamp": datetime.now()
}])
Alteryx.write(error_df, 1)
raise
And that's it. One could now play around with the delay and batch size variables and montior the overall script execution time. In this example, the default values have been set to avoid throttling, not optimize for execution time though. And don't forget to pass at the very least the client_secret value to the script from the environment, instead of keeping it hardcoded.