


In November, an incredible opportunity arose to spend time in the UK office in London, returning to the classroom to deep-dive into the fundamentals of data engineering. The program covered a range of essential concepts, from extraction and loading to orchestration, transformation, and governance, while also highlighting how these components interact to form a complete, evolving data pipeline. This hands-on experience offered the chance not only to understand the theory but also to see how these building blocks support real-world data workflows. This blog series was created to share that journey and reflect on the lessons learned along the way.
How the Journey Began
The path to this point began while working as a mechanical engineer at a facility that built helicopter and airplane parts. At that time, learning a coding language seemed essential — after all, is someone really an engineer if they cannot code (or so I thought)? Python was the starting point, followed by the discovery of DataCamp, a platform focused on data analytics and data science (at the time). This exposure led to a career transition and eventually to a consulting position at The Information Lab.
During the first two years of the contract, the focus was primarily on Tableau and Alteryx, with minimal exposure to SQL. Over time, interest shifted toward the building blocks of the data lifecycle rather than the visualisation and reporting side. This curiosity prompted further exploration into data engineering concepts and dbt - with a quick peek into AWS & Snowflake.
Earlier in the year, considerable time was invested in developing a solid understanding of data engineering fundamentals. When The Information Lab offered the opportunity to join the Data Engineering extension program, the application was submitted immediately, ensuring full effort was put forward.
What the Week Covered
The Fundamentals
The first week focused on the fundamentals of data engineering, including the stages of a data pipeline, how these stages interact, and how they evolve in response to business needs and increasing maturity. It was emphasised that building a pipeline is not a one-time task but a continuous cycle of reviewing, improving, and adapting.
This approach aligns closely with CI/CD (Continuous Integration and Continuous Deployment), a key practice in modern data and software engineering that ensures changes are tested, integrated, and deployed efficiently. More details on CI/CD and other aspects of the data engineering lifecycle will be covered in future blog posts.
Every pipeline begins with an input
The goal of the program was to build a comprehensive data pipeline using scripted Python code, while also comparing it to a no-code, drag-and-drop tool that performs the same steps.
The data used consisted of website traffic captured by Amplitude and stored in hourly increments. The pipeline involved extracting this data via the Amplitude API, saving it to blob storage and a local drive, pushing it to an S3 bucket, staging it in Snowflake, transforming it with dbt, and storing it back in Snowflake for analysis.

- Airbyte & Azure Blob Storage
There are many ways to capture and collect data, but once collected, it needs to be moved into a pipeline for analysis. One approach explored was using Airbyte, an open-source data integration platform designed to simplify data extraction and loading. In this case, Airbyte was used to move data from Amplitude, which tracks website traffic, into Azure Blob Storage, Microsoft’s cloud-based object storage solution similar to Amazon’s S3. Setting this up required creating accounts for both services and linking them within Airbyte, allowing the data to flow automatically from the source into centralised storage.
Setting up the source (Amplitude) and the destination (Blob Storage) required providing key information for both services, including account details, names, access keys, and file paths.
Using Airbyte to extract data from Amplitude offered several advantages. Its open-source framework and extensive library of pre-built connectors made pipeline setup straightforward and efficient. The platform operated in a largely hands-off manner once configured, and scheduling data extractions was simple to implement and maintain.
Similarly, Azure Blob Storage provided a reliable and scalable storage solution for the extracted data. It could handle large volumes of raw or semi-structured data if needed, could integrate seamlessly with other Azure services, and could be cost-effective for long-term storage.
- Python & Local Drive
Instead of using a platform to handle extraction and loading in the background, a Python script was implemented as an additional option to outline each step explicitly. This approach exposed the low-level details and decision points that would otherwise have been hidden behind the platform’s automation.
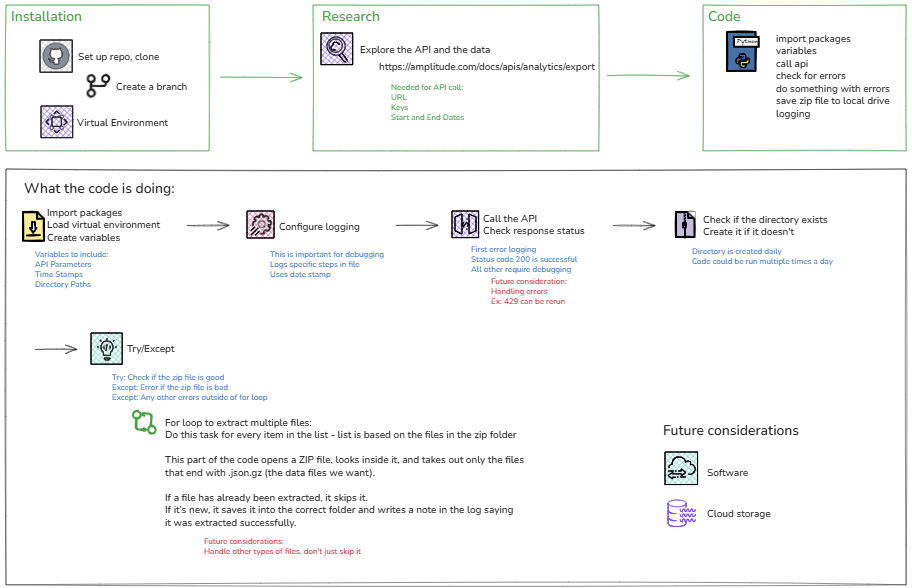
The Python script handled the data extraction process in a structured and transparent manner. It began by connecting to the Amplitude API using securely stored credentials and requesting website traffic data for a defined time range. The retrieved data was saved as a compressed ZIP file and extracted into a temporary directory. Comprehensive logging was implemented to record each stage of the workflow — from successful API calls to potential errors — ensuring clear traceability and easier troubleshooting.
After extraction, the script located and decompressed each .gz file containing event-level data, converting them into readable JSON files and storing them in the designated data directory on a local drive. Temporary files were then cleaned up to maintain an organised workspace. This approach provided full visibility into the extraction and loading steps, highlighting the advantages of manual scripting for understanding and controlling each part of the pipeline.
The Takeaways
The comparison between Airbyte and the Python-based approach highlighted the trade-off between automation and control. Airbyte streamlined setup and scheduling, making it ideal for scalable, low-maintenance pipelines. However, the Python method provided full transparency and flexibility, exposing every step of the extraction process. Together, the two approaches illustrated how the choice of tools depends on the project’s priorities—whether ease of use and speed or customisation and precision.
Curious to see the project in more detail? Check out the full code and workflow on my GitHub repository. For security reasons, access to the data is restricted and not available to anyone outside of The Information Lab.