


In week 1 of training, we covered the concept of snowflake schemas to represent the logical connections between data tables. The following are thoughts I have compiled on how to better remember the different components of the snowflake schema:
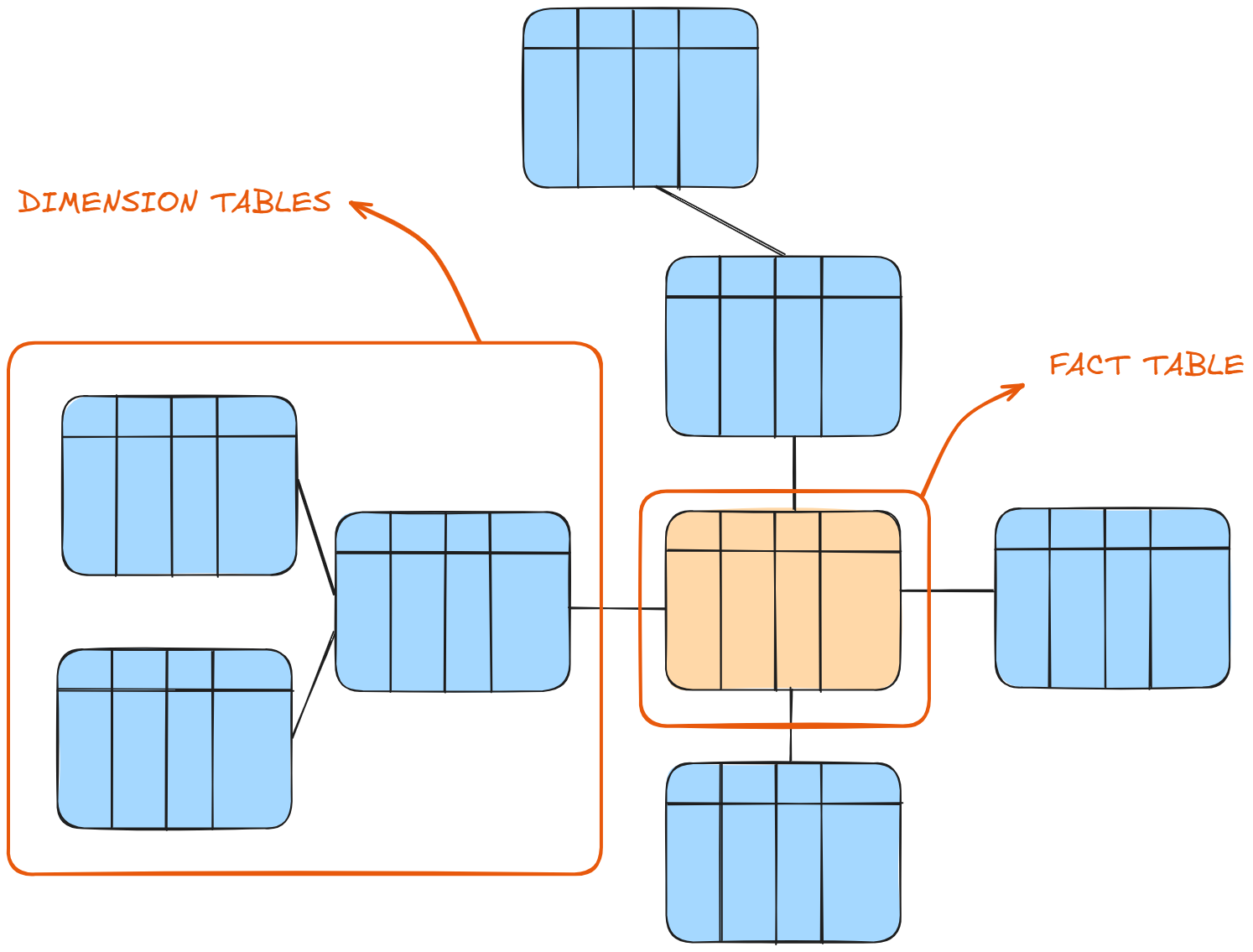
In the schema, there is one central table called the 'fact table'. As the focal point of our data, it holds the answer to questions like 'how much' or 'how many' (aka metrics) about a business or process (e.g. sales, complaint logs, bird sightings).
The other kind of table, the ones connected to the fact table in an outward expanding tree, are dimension tables. These tables exist to track descriptions about the categorical fields (properties of a record) from the fact table in order to provide context to the metrics being measured.
"There are numbers in multiple tables, I'm confused as to which one is the fact table!"
A common misconception is that if a table has numbers, it must be a fact table. Actually, dimension tables often contain attributes that are numerical (e.g. cost, size, length), but those fields would still be considered attributes for grouping, filtering, or describing facts by those dimensions.
Here is where a key difference between fact and dimension tables come in:
- In fact tables, an instance of something, let's call it a fact, may appear multiple times (e.g. a recurring transaction, multiple separate sightings of the same kind of bird)
- In dimension tables, the description of a recurring property in the fact table will appear as a record only once in the dimension table, existing as a unique entry (e.g. the type of transaction and what it's worth, the bird's species and it's size).
For instance, let's look at some data for bird sightings:


Both the sightings table and the species table contain a field that records some metric. For the sightings table, the metric recorded is bird_count and confidence_score. For the species table, the metric recorded is the avg_lifespan. In this case, the fact table would be 'sightings' and the dimension table would be 'species'. Even though lifespan is numerical data, in this scenario it would be used to categorize the records from the sightings table (find sightings of birds with an avg lifespan > 10 years). It would not be aggregated. Aggregation of numeric data should be done in the fact table, since we want to find out measurable information about the process of sightings.
Here is an example of the bird data in a snowflake schema:

In short, fact tables record events that happen, while dimension table records descriptions of things. Mastering this concept will make your data modeling a lot easier.