


In the previous blogs, I introduced how to retrieve data from API and parse JSON in Tableau using TabPy (Part 1, Part 2) or using the JSON Parse tool in Alteryx (blog). In those blogs, I explained the JSON structure including objects, arrays, and key-value pairs, and also visualized the JSON structure in the tree diagram.
In a scenario, after retrieving data from API, the format of the data is JSON and is stored in Snowflake. As you are working with SQL in your project, how to parse JSON directly in Snowflake?
To answer that question, I will share some functions in Snowflake to parse JSON and flatten objects, and arrays in this blog. Then, I will also share some tips for data wrangling in SQL.
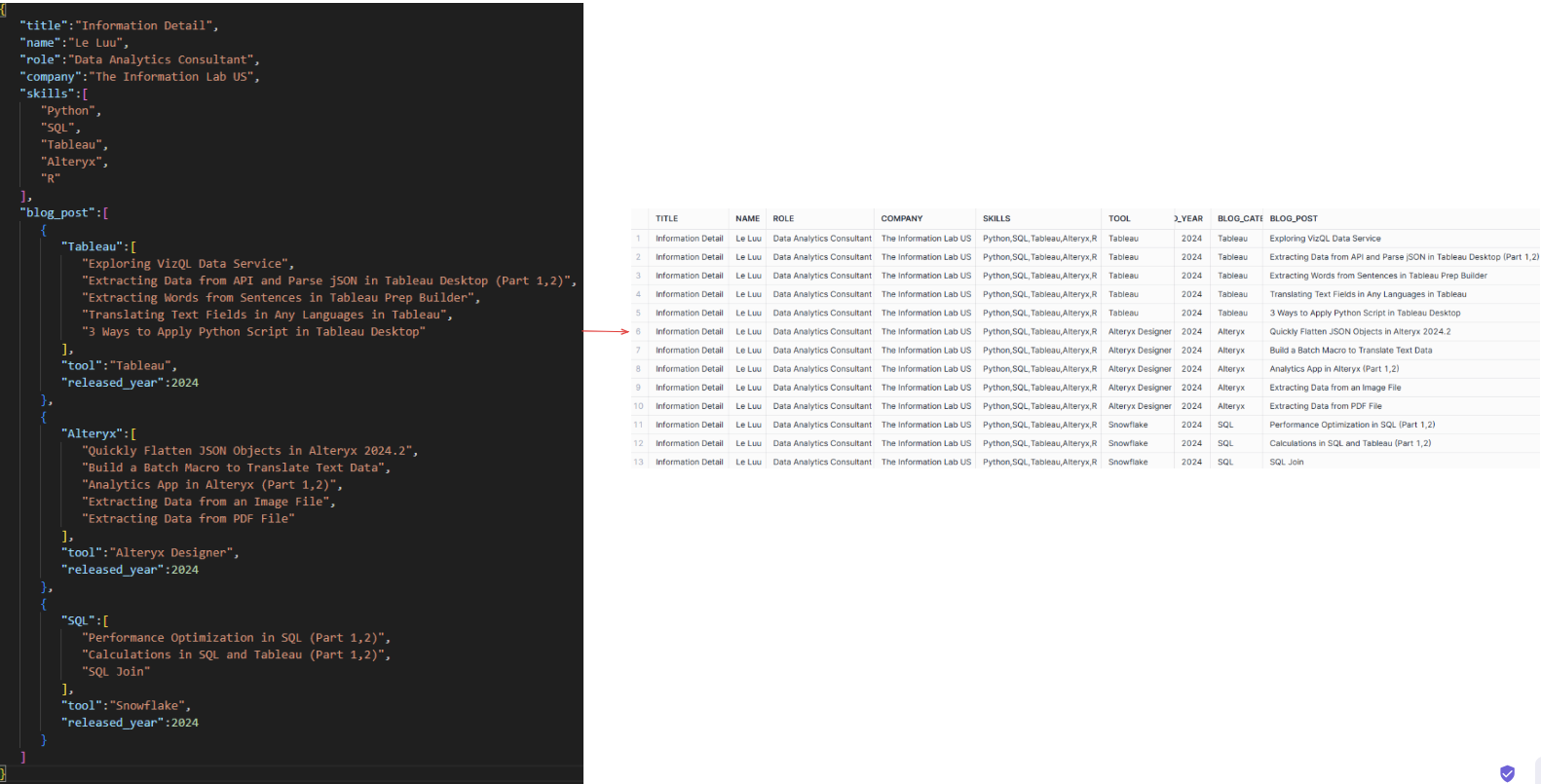
Fig. 0 shows the JSON structure on the left side and the result on the right after parsing JSON, flattening objects, arrays, and cleaning data.
How to parse JSON and return a table like that in SQL; specifically in Snowflake?
Let's walk through all the steps in this blog!
1/ Analyze JSON structure
Depending on the Relational Database Management System (RDBMS) that you are using, the way to extract data from JSON could be different.
For example:
- In MySQL, the JSON_EXTRACT function will help to parse JSON and return data from a JSON document. There is a list of JSON functions in the MySQL documentation, you can read it here.
- In PostgreSQL, the json_array_elements function will expand a JSON array to a set of JSON elements. The json_extract_path function will return the JSON object or the json_object_keys function will return a set of keys in the JSON object. You can read more about JSON functions in PostgreSQL here.
- In SQL Server, you can use the OPENJSON function to transform JSON data to the table format. The JSON_VALUE function will extract the data from JSON data.
- In Snowflake, you can use PARSE_JSON, TRY_PASE_JSON, JSON_EXTRACT_PATH_TEXT functions to parse and extract data from JSON. You can read more about the JSON functions in Snowflake here.
In this blog, I will only focus on parsing and extracting data from JSON in Snowflake. Therefore, some functions in Snowflake would be different from functions in other RDBMS.
I created JSON data by listing all the skills and blog posts I have. Now, let's analyze the JSON data.
{
"title": "Information Detail",
"name": "Le Luu",
"role": "Data Analytics Consultant",
"company": "The Information Lab US",
"skills": [
"Python",
"SQL",
"Tableau",
"Alteryx",
"R"
],
"blog_post": [
{
"Tableau": [
"Exploring VizQL Data Service",
"Extracting Data from API and Parse jSON in Tableau Desktop (Part 1,2)",
"Extracting Words from Sentences in Tableau Prep Builder",
"Translating Text Fields in Any Languages in Tableau",
"3 Ways to Apply Python Script in Tableau Desktop"
],
"tool": "Tableau",
"released_year": 2024
},
{
"Alteryx": [
"Quickly Flatten JSON Objects in Alteryx 2024.2",
"Build a Batch Macro to Translate Text Data",
"Analytics App in Alteryx (Part 1,2)",
"Extracting Data from an Image File",
"Extracting Data from PDF File"
],
"tool": "Alteryx Designer",
"released_year": 2024
},
{
"SQL": [
"Performance Optimization in SQL (Part 1,2)",
"Calculations in SQL and Tableau (Part 1,2)",
"SQL Join"
],
"tool": "Snowflake",
"released_year": 2024
}
]
}
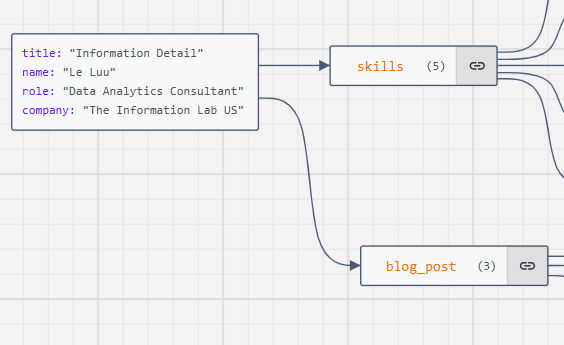
Then, I use the https://jsoncrack.com/editor page to visualize the JSON structure.
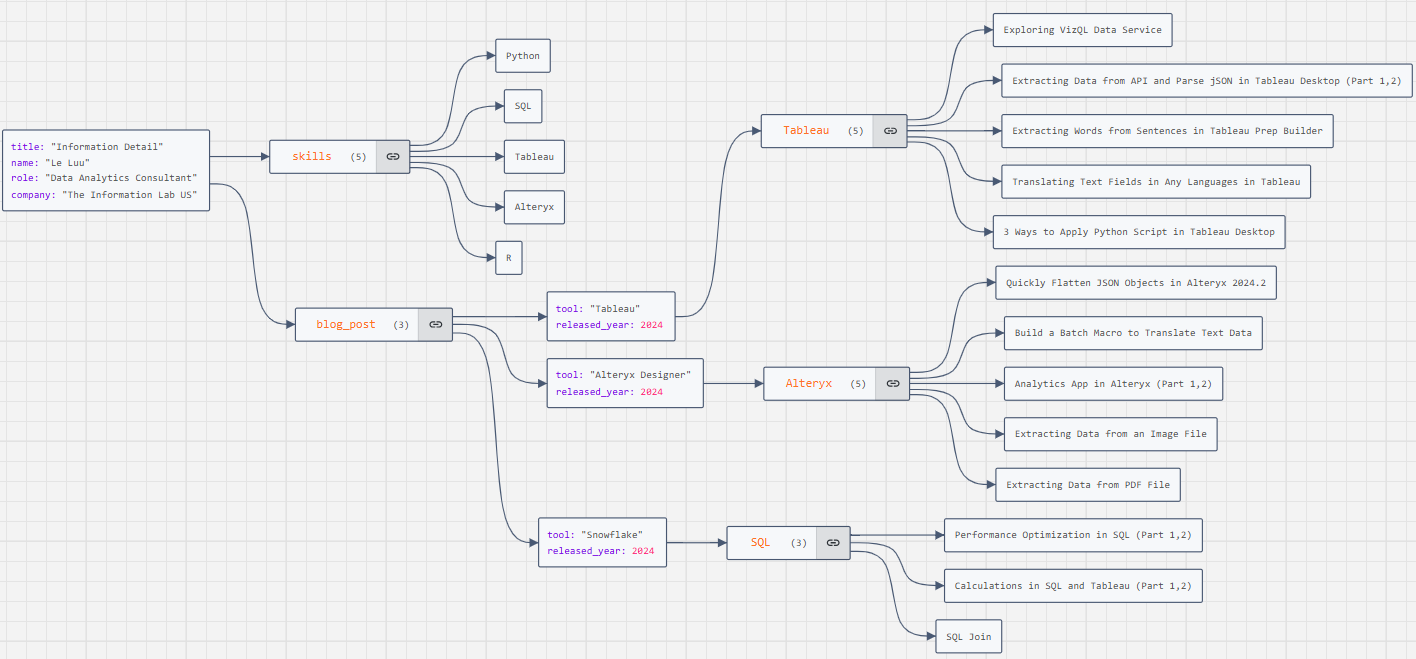
First, let's explore 3 main data types in Snowflake.
- VARIANT: the variant data can contain OBJECT and ARRAY values.
- OBJECT: JSON Objects are written inside curly braces({}). An object contains multiple key-value pairs. An Object can include a VARIANT value.
- ARRAY: JSON Arrays are written inside the square brackets ([]). An array contains multiple objects, and values and is separated by commas. An array can include a VARIANT value.
In Fig. 1, you can see we have a VARIANT that contains objects and arrays. There are 4 key-value pairs (title, name, role, company) and 2 arrays (skills, blog_post). The skills array includes 4 values. The blog_post contains 3 objects. Each object contains an array and 2 key-value pairs.
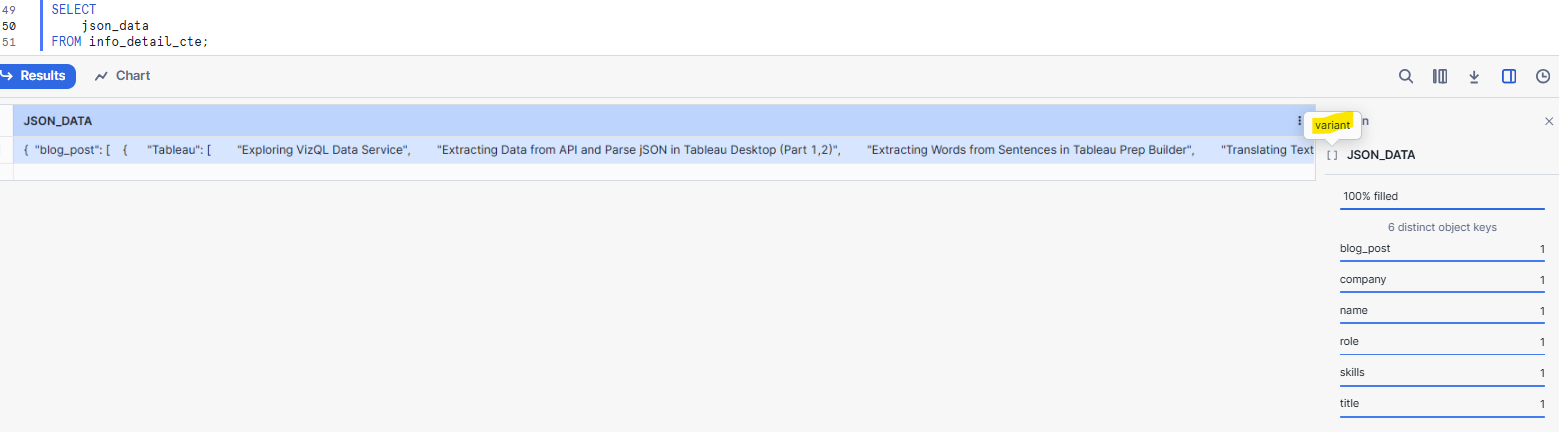
In Snowflake, I copy the JSON data above as a CTE. I declared an info_detail_cte CTE. Then, I use the PARSE_JSON function to interpret a string as JSON data and store it as an alias json_data (Fig. 2). You can also use the TRY_PARSE_JSON function; if there is something wrong during parsing JSON, it will return Null. The data type of the output is VARIANT.

If I use the SELECT clause to select json_data from the info_detail_cte, I will get the json_data in the output. When I check the data type of that json_data column, it shows a variant data type (Fig. 3).
However, if I use the typeof function to check the type of json_data, it will return an Object as all key-value pairs are wrapped by curly braces outside (Fig. 4).
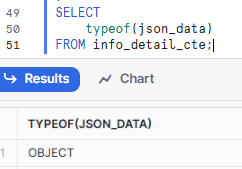
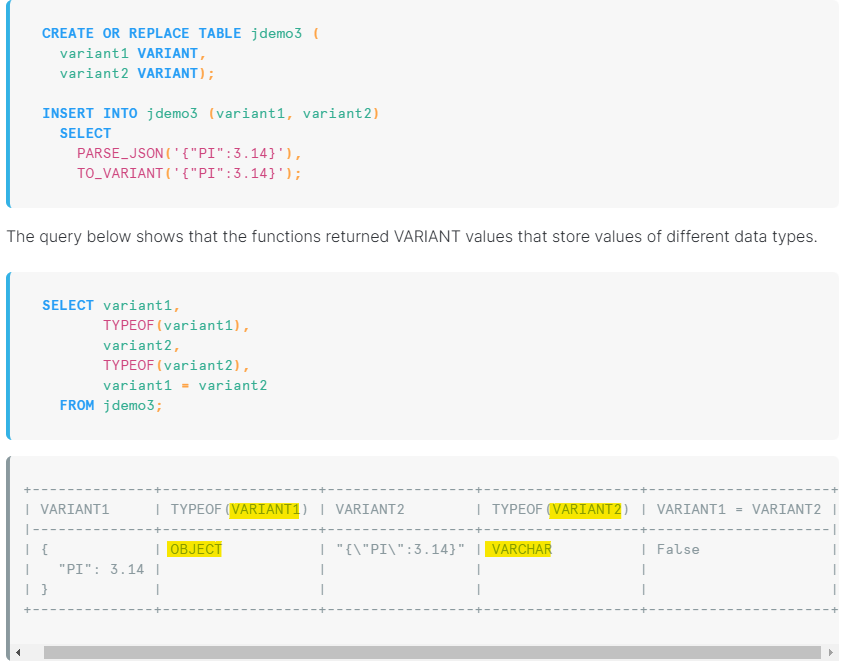
Both PARSE_JSON and TO_VARIANT can take a string and return a VARIANT value, but they are not equivalent (Fig. 5). You can read more on the Snowflake documentation page here.
2/ Data Flattening
In this section, I will walk through some functions that help us to extract and flatten objects, and arrays.
a) Extract data from key-value pair
The object contains 4 key-value pairs (title, name, role, company) and 2 arrays (skills and blog_post).
I will start extracting data from 4 key-value pairs first. In Snowflake, after creating a CTE same as Fig. 2, the name of the CTE is info_detail_cte and the field is json_data.
In the primary query, I would like to output the key and value of each pair. There are 2 ways to return it in the table:
Option 1: Print the key value as a VARIANT type. It means that the value could be an object or an array. If it contains an object or an array, you can continue to flatten it later.
<field_name>:<key>
On line 50 in Fig. 7, I type json_data:"title" as title_no_cast. In the result table, you see the value in TITLE_NO_CAST contains the quotation marks.
Option 2: Print the key value as a STRING type. The title is a text, so I will convert the data type of the title value into a string. I used "::" for casting the data type of the title value from VARIANT into STRING.
<field_name>:<key>::<casting_data_type>
On line 51 in Fig. 7, I type json_data:"title"::STRING as title_with_cast. In the result table, you see that no quotation marks around the text.
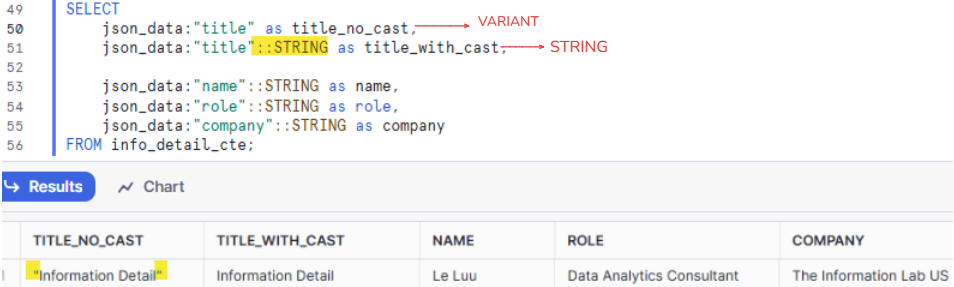
I keep doing option 2 for name, role, and company key.
As you know, the skills and blog_post are 2 arrays in the object. What will the result table return if I keep applying this method for those 2 arrays?
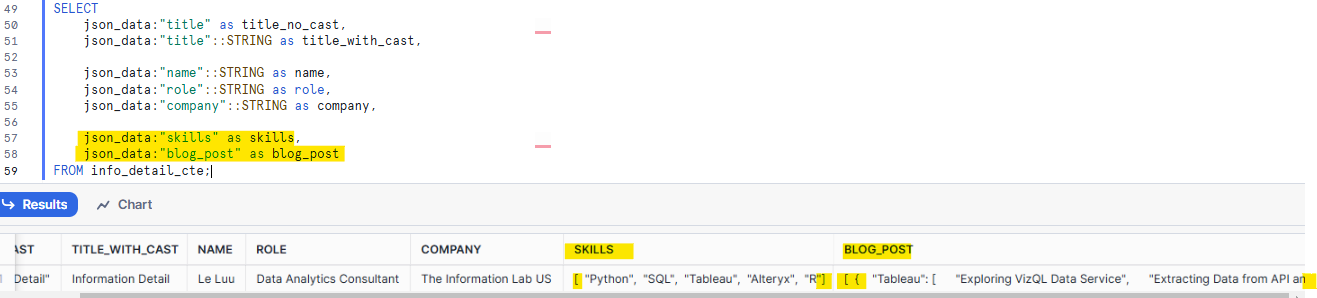
It cannot flatten all the values in those arrays. In Fig. 8, If I don't use casting (::) for skills and blog_post, the result is still VARIANT with the value being JSON data.
b) Flatten Objects and Arrays
Depending on the JSON structure and the purpose you want to extract data, you will decide to flatten objects and arrays or keep them as a VARIANT. In this scenario, the skills array belongs to the main object, so I don't want to extract each element in the skills array into each row. Instead, I want to keep Python, SQL, Tableau, Alteryx, and R on the same row.
For blog_post, this array contains 3 Objects. In each object, it contains 2 key-value pairs and 1 array (Fig. 9).

To flatten all values in the blog_post into each row, we need to flatten data from the outer array -> each object -> key-value pairs -> nested array.
First, I need to break the outer array from the blog_post. To do that, I need to use the FLATTEN function in Snowflake. You can read more about its documentation here. The FLATTEN function requires an input value which is VARIANT, OBJECT, or ARRAY. There are 4 other parameters in the FLATTEN function (path, outer, recursive, and mode).
To use the FLATTEN function, I also need to use the LATERAL clause. The purpose of using the LATERAL clause is to allow Snowflake to access the preceding table in the FROM clause.
In Snowflake, after the FROM clause, I type:
FROM info_detail_cte,
LATERAL FLATTEN(input => json_data:"blog_post") AS blog;
It means flattening data from the array blog_post of the json_data in the table info_detail_cte. Then, I store it as an alias blog. In the SELECT clause, I add:
blog.value:"tool"::STRING as tool,
blog.value:"released_year"::NUMBER as release_year
After breaking the outer array by using the FLATTEN function, I treat the JSON object the same as I did in part a. To extract the data from key-value pairs, I use the property value for the blog and cast the data type.
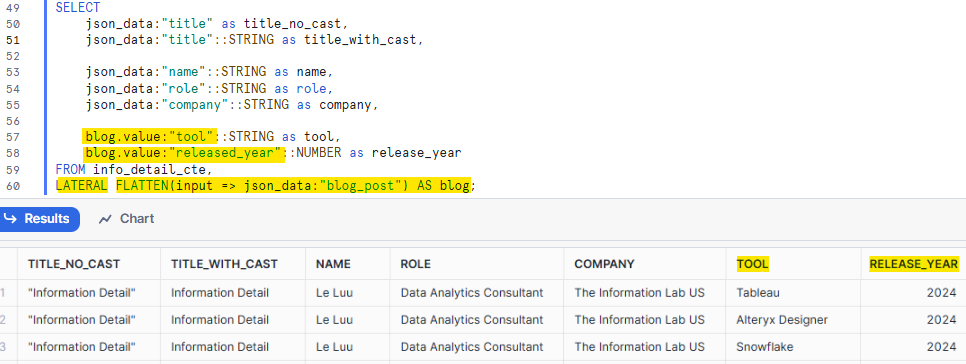
After I get the tool and released_year data, I want to flatten the data for each array in each object. In this case, I want to flatten values in Tableau, Alteryx and SQL arrays.

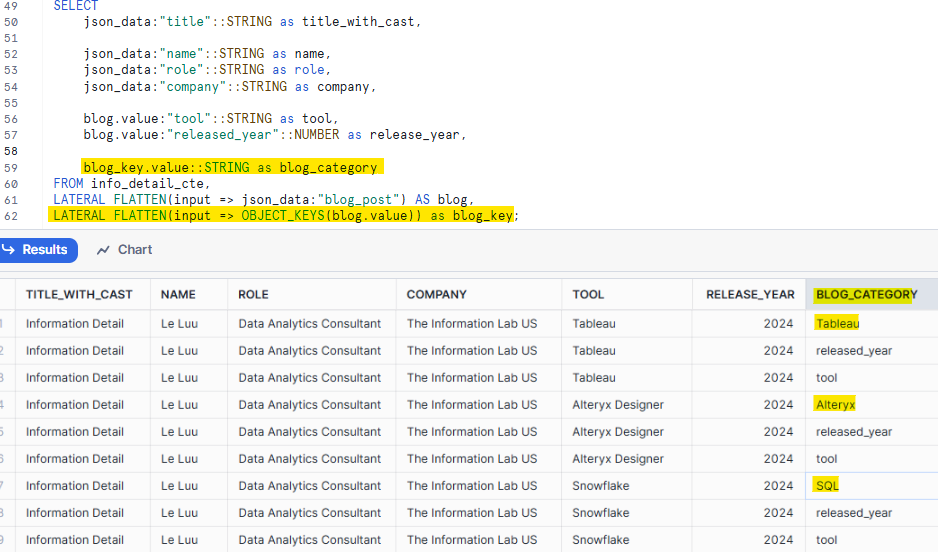
But I need to extract the key value of those arrays first. To do that, I use another FLATTEN function to get all the keys inside blog_post by doing:
LATERAL FLATTEN(input => OBJECT_KEYS(blog.value)) as blog_key
In the SELECT clause, I print out all the keys in the blog_post array and cast them to STRING by doing:
blog_key.value::STRING as blog_category
In the result table, you will see the blog_category includes Tableau, Alteryx, SQL, released_year, and tool. However, I only want to keep Tableau, Alteryx, and SQL for the blog_category because I already got the tool and released_year field in separate columns.
c) Flatten nested array
After getting all object keys in the blog_posts, I want to flatten all data in the nested array (Tableau, Alteryx, SQL). To flatten data again, I need to use the FLATTEN function.
In the FROM clause, I add another FLATTEN function:
LATERAL FLATTEN(input => blog.value[blog_key.value]) as blog_posts
In the SELECT clause, I print out the value of blog_posts and casting it to STRING.
blog_posts.value::STRING as blog_post
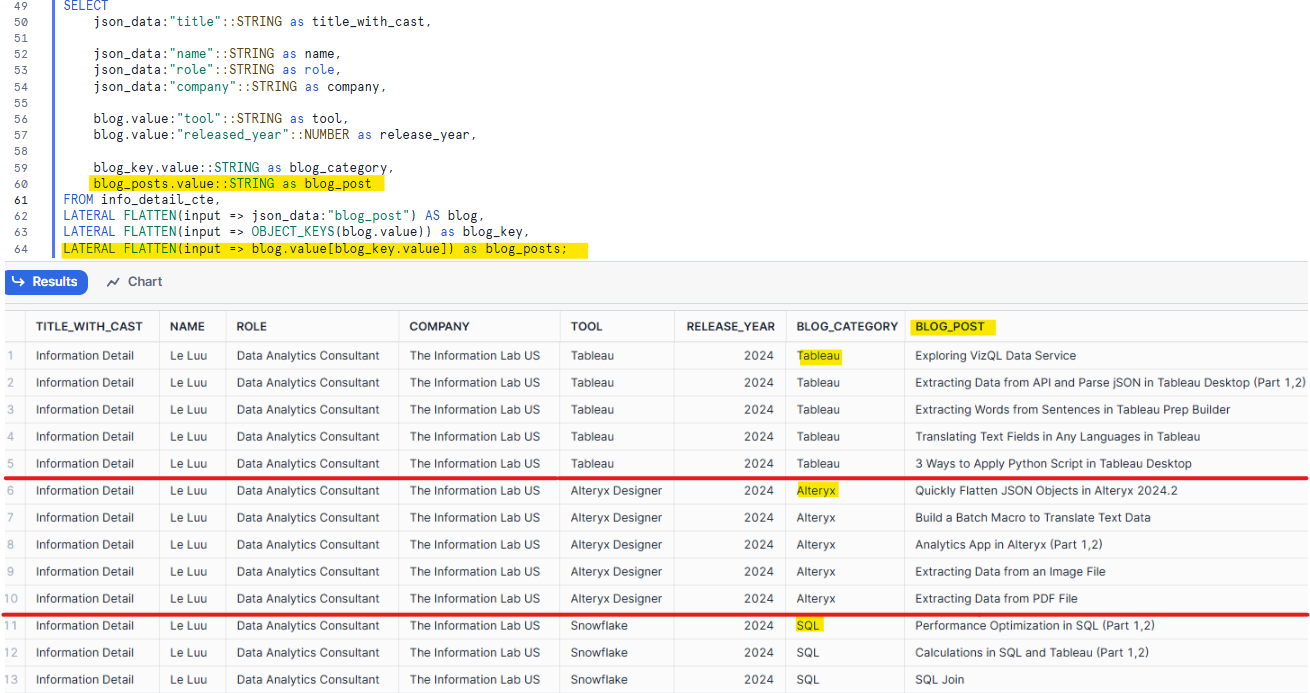
As you see in Fig. 13, I flattened all values in the blog post array. If you notice that the blog_category field now only shows Tableau, Alteryx, and SQL. In Fig. 12, it also shows released_year and tool.
The question is: Where are the tool and released_year values in the blog_category field?
Answer:
In Fig. 12, at that time, I only have the FLATTEN to extract all object keys from all three objects in the blog_post array. However, after I add another FLATTEN function with the input is the value inside the blog_post which has blog_key value in the nested array, it will iterate to each value inside the nested array.
At this time, the blog_key.value in the SELECT clause will return the key of the nested array. The blog_posts.value will return all values in each nested array.
3/ Data Wrangling
We are almost done with the table format. The last step is cleaning the table. I changed the aliases of some columns. With some fields that I don't want to flatten, it shows the squared brackets and quotation marks, I need to remove them. The skills array is an example (Fig. 13).
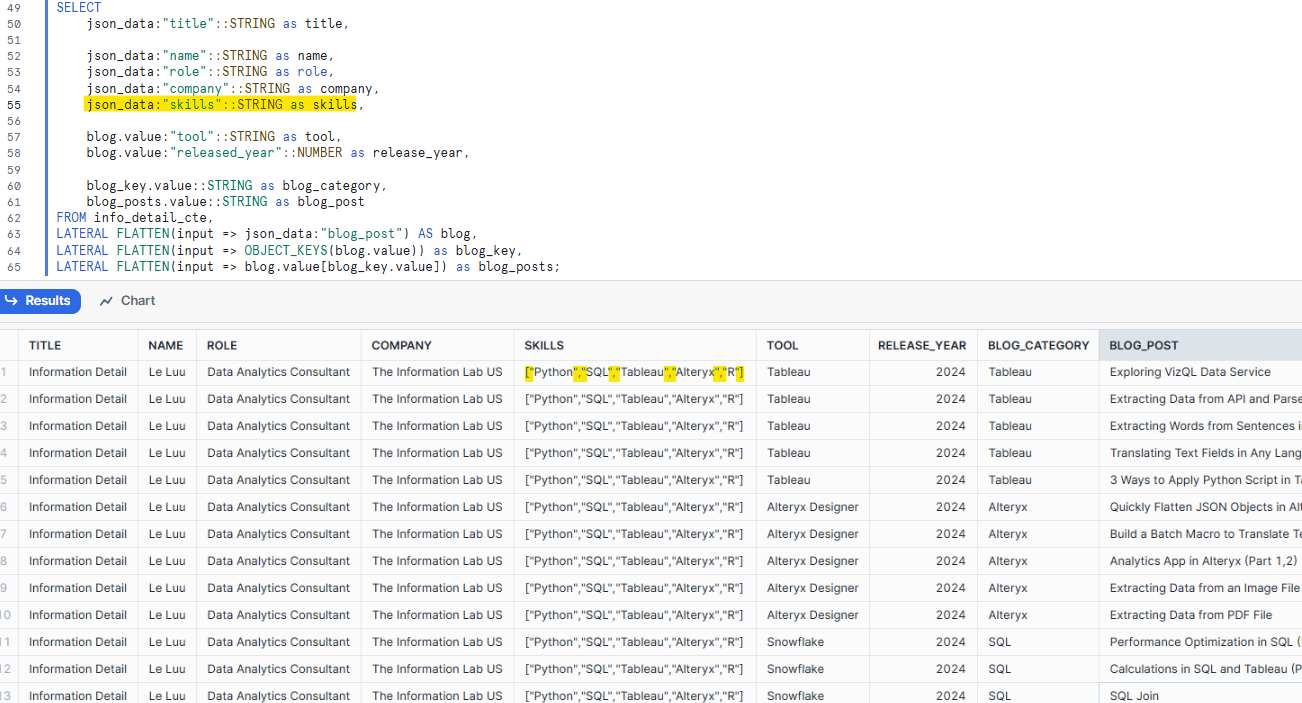
There are 2 options for you to remove the squared brackets and the quotation marks.
- The first option is using the REPLACE function to replace the "[","]", ' " ' by empty string ''.
- The second option is to use the ARRAY_TO_STRING function. The requirement of the ARRAY_TO_STRING function is the input should be an array. It will split each element in the array and concatenate them again with a separator. You can read more about that function here.
In Snowflake, I will add this line in the SELECT clause:
ARRAY_TO_STRING(json_data:"skills"::ARRAY, ', ') AS skills
It will convert the data type of the skills field in the json_data to ARRAY. Then, apply the ARRAY_TO_STRING function to it and separate each element by a comma with a space.
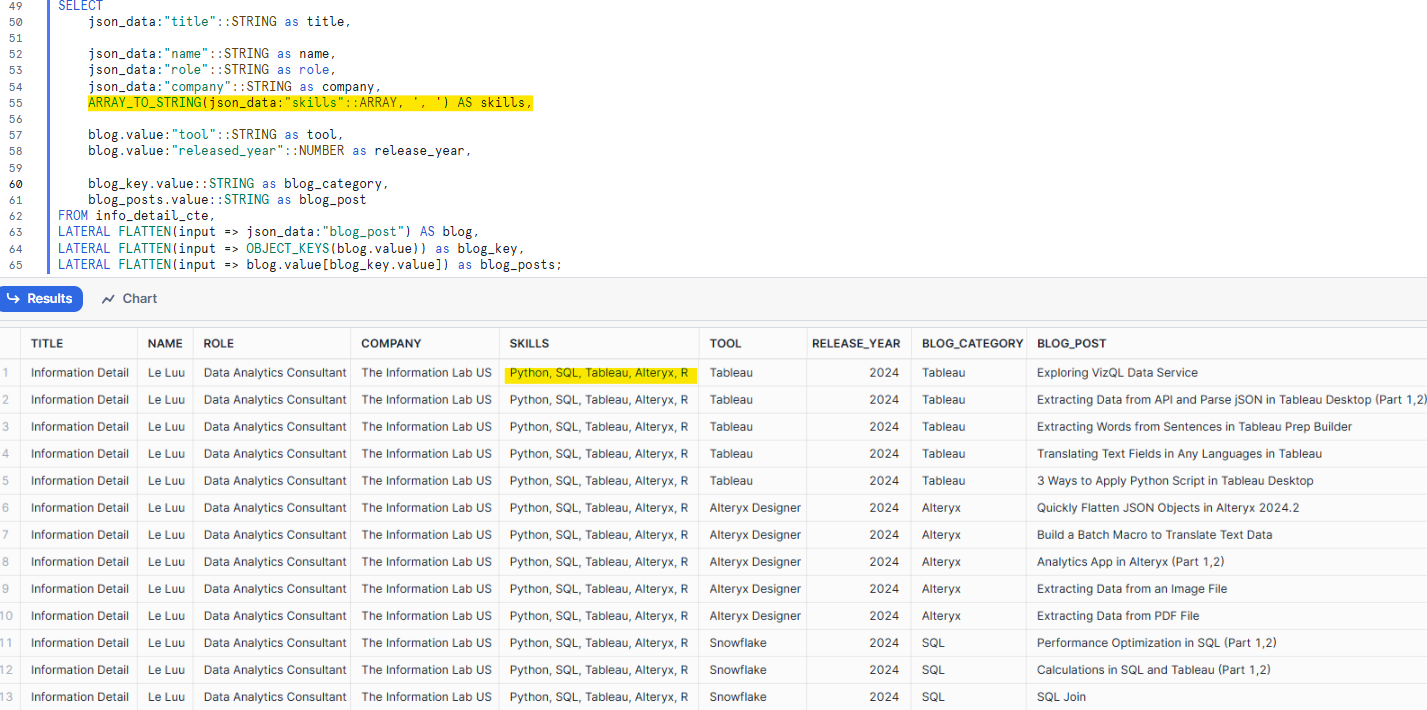
Now, you can format the table as what you want. For example, I use the ROW_NUMBER function to count the number of blogs by each blog_category and concatenate it with the first character of the blog_category for the blog_id field.
The final result table will look like this:
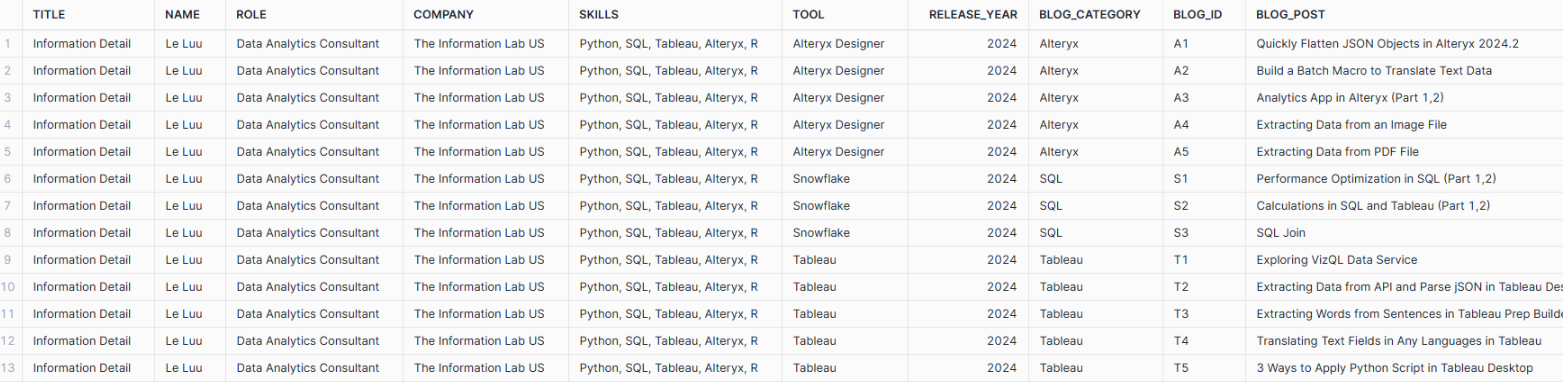
The values in Title, Name, Role, Company, and Skills are repeated multiple times. You can also split that table into 2 small tables to show information about the employee in 1 table with the employee ID, title, name, role, company, and skills fields. Another lookup table with employee ID, tool, released_year, blog_category, blog_id, and blog_post.
In this blog, I shared how to analyze the JSON structure, and how to flatten the data in objects, arrays, and nested arrays. In the final part, I shared some tips how to clean, and prepare the data in Snowflake.
This blog is long with more details on parsing JSON and flattening data in Snowflake. I hope my blog is helpful if you are working on JSON with Snowflake.
See you soon in the next blog!