


In the previous blog, I compared the difference in the order of writing SQL queries and the order of execution in SQL (link). Acknowledge the execution order in SQL is significant and helpful because the user will know how the SQL queries execute in the system which they can't see. Furthermore, the order of execution in SQL will help give some tips for optimizing performance.
Many factors can affect the performance. It could be from the network traffic, the peak hour when most users access the data source at the same time. Besides that, writing SQL queries can also affect the performance when extracting the data.
Recall, below is the order of writing SQL queries and the order of execution. In this blog, I will share some ways to improve performance based on the order of execution. I will go through from the highest to the lowest order.
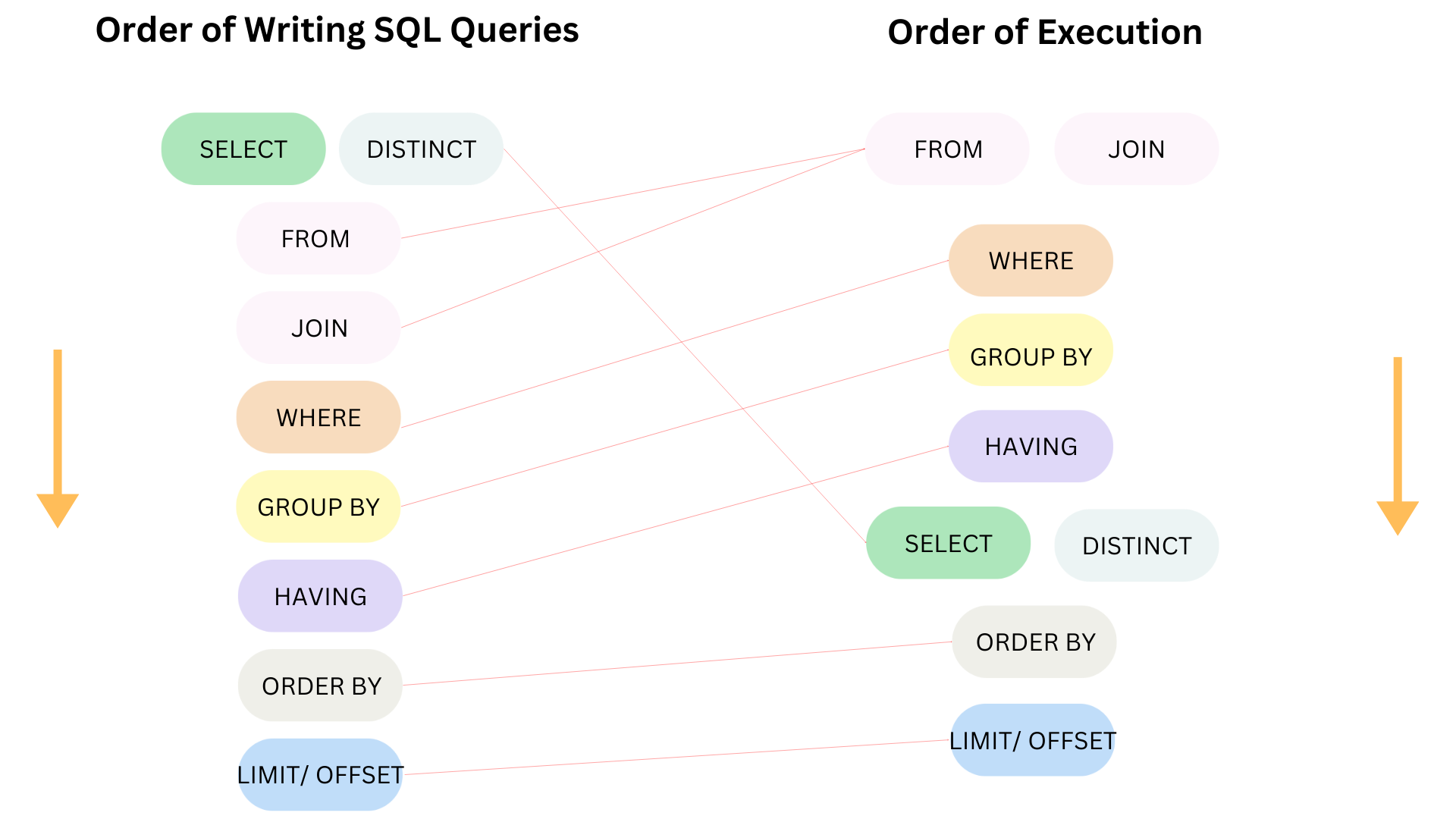
1/ FROM/ JOIN
From/ join is executed first. Therefore, if we can find some ways to improve performance in this step, it would be better later.
Some advice in this stage:
- Avoid the peak hour when refreshing the database.
But we cannot do anything much in this option if you are not the data owner or in the IT department.
- Have a good database design.
If there are many rows/ columns in the table and many columns have long text in each row, it would take a longer time to load. In this case, consider partitioning/ clustering the table. This method will split a large dataset into small datasets.
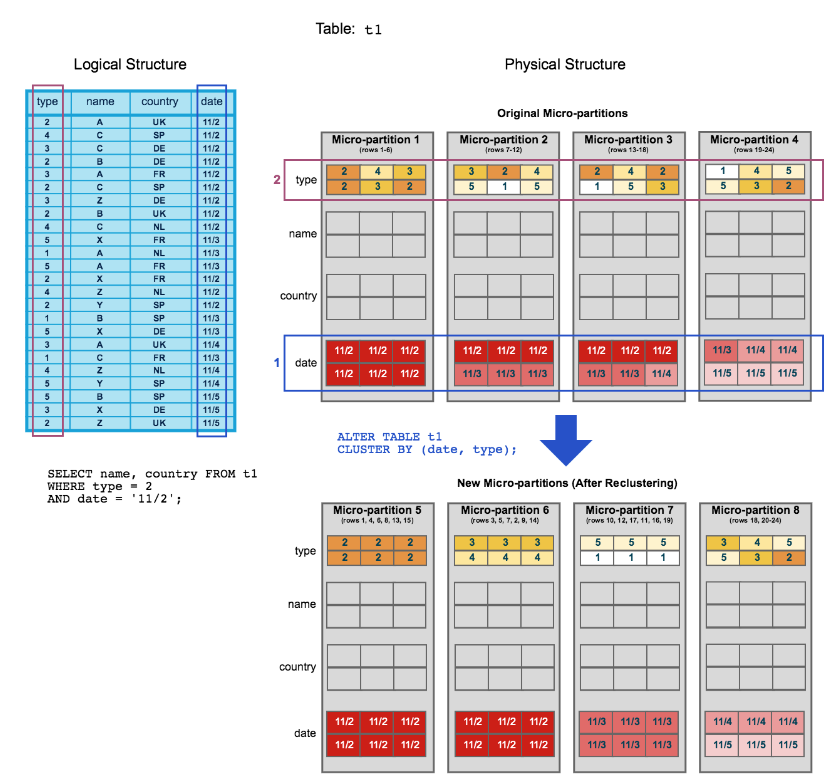
For example: In the image below from the Snowflake documentation page, there is an original table t1 at the top with Micro-partition from 1 to 4. After clustering the table based on the type and date columns, there are 4 new micro-partitions from 5 to 8. Those micro-partitions are grouped by the type and date. So we can ALTER the table from the beginning.
You can read more about it from the Snowflake documentation page here.
- Avoid using subqueries.
If you need to pull data from other tables, try to avoid using subqueries. Instead, use CTE, temporary tables, or join. Especially, when the subquery returns so many rows from a large dataset, it could cause performance to slow.
For example:
Avoid using this way because the system needs to check each product_id in the table Order with the id in the subquery from the Product table.
SELECT customer_name, product_id
FROM Order
WHERE product_id IN (
SELECT id
FROM Product
WHERE product_name = 'Laptop';
)
Try this:
SELECT o.customer_name, o.product_id
FROM Order o
INNER JOIN Product p
ON o.product_id = p.id
WHERE p.product_name = 'Laptop';
- Consider using the right data type when creating the table.
For example, if the value in a field only has positive numbers with 4 to 5 digits, using the TINYINT data type would save much more space than using INT. It will reduce the size of the database and optimize its performance. Check SQL data types from the GeeksforGeek page here.
- Avoid complicated joins or many joins.
Try using INNER JOIN instead of LEFT/ RIGHT JOIN if don't need the unmatched values. The LEFT/RIGHT JOIN will return both matched and unmatched values while the INNER JOIN only returns the matched values => less row. I have a blog about all types of SQL join, you can read it here.
2/ WHERE
The Where is executed after pulling data from the FROM and JOIN clause. The Where is followed with a condition. It will help to filter out many rows if the condition is satisfied.
Some advice in this stage:
- Avoid using complicated conditions.
If there are many conditions in which you need to use many operators like AND/ OR, "=" or not (!=), ..., you can consider partitioning/clustering the table as I mentioned above.
- Avoid applying function in the WHERE clause.
If you need a condition with function or aggregation, you can consider creating a temporary table or CTE. Then apply a condition with the field from a temporary table or CTE.
For example, if you need to filter the data for the year 2024 and the month is 09.
Try avoiding this way:
SELECT customer_name,product_name
FROM Order
WHERE YEAR(Order_date)=2024 AND MONTH(Order_date)=09;
Instead, you can try this:
SELECT customer_name, product_name
FROM Order
WHERE Order_date BETWEEN '2024-09-01' AND '2024-09-30';
- Avoid using Wildcard/ REGEX conditions.
They could cause performance to slow. The user usually uses the LIKE operator to search for a specified pattern in a string value in the column with characters "%" and/or "_".
Especially, using "%" at the beginning of the pattern could cause performance to slow. The character "%" represents zero or more characters. Therefore, if the pattern is LIKE "%Apple". The system needs to check all values in the column if there are any characters or no characters before the Apple word. If the dataset is large, it could cause slower. Instead, we can put the character "%" at the end or use INDEX.
REGEX or REGEXP could cause performance worse than LIKE if the pattern is complicated in the large dataset. If you need to use REGEX, you can consider narrowing down the dataset (using CTE, partitioning/clustering table) and using a simple pattern.
- Consider using the index. The index is used to retrieve data quickly from the database. We can't see the index. The purpose of using the index is each value in the column will be assigned by an index. Whenever we need to filter the data, it will directly retrieve that data without scanning each row of the table.
To create INDEX in Snowflake:
CREATE [OR REPLACE] INDEX [IF NOT EXISTS] <index_name> ON <table_name> (<column_1>, <column_2>,...)
To drop INDEX:
DROP INDEX [IF EXIST] <table_name>.<column_name>
The index would be great for improving performance. However, we shouldn't overuse the index. With a large dataset, when we create the index for many columns, the system will need a large storage to store the index. The index will also be updated if we alter the table (INSERT, DELETE, UPDATE).
- Use EXISTS instead of using IN when having a subquery.
The EXISTS operator will stop searching if the system finds a matched value. For the IN operator, it will check the value with each value in the IN operator list (like an OR operator).
- Avoid using ANY/ALL if the subquery returns many rows from a large dataset.
For the ANY operator, the system will check the value if it finds any matches from the subquery and return True. For the ALL operator, the condition will return True if the value matches with every row in the subquery.
ANY and ALL operators are good to use if the subquery returns not many rows. However, if the subquery returns many rows from a large dataset, you can consider using a JOIN table. If you use the index for the column with JOIN, it would optimize the performance.
3/ GROUP BY
The GROUP BY clause is used when using aggregate functions in the SELECT. Besides that, the GROUP BY can be used to return the unique rows. It would be helpful when you want to create a lookup table. It could be also helpful in using a subquery to check if the value exists in the subquery.
However, consider using it if the dataset is not large.
In the example below, I want to return the unique sub-category of each category. In the SELECT, I choose category and sub-category and also group by category and sub-category. (Fig. 3)
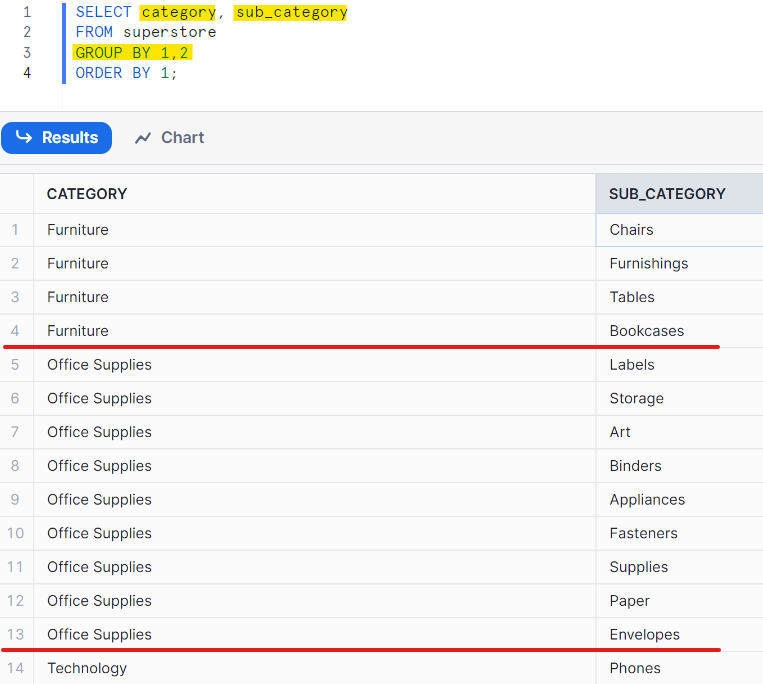
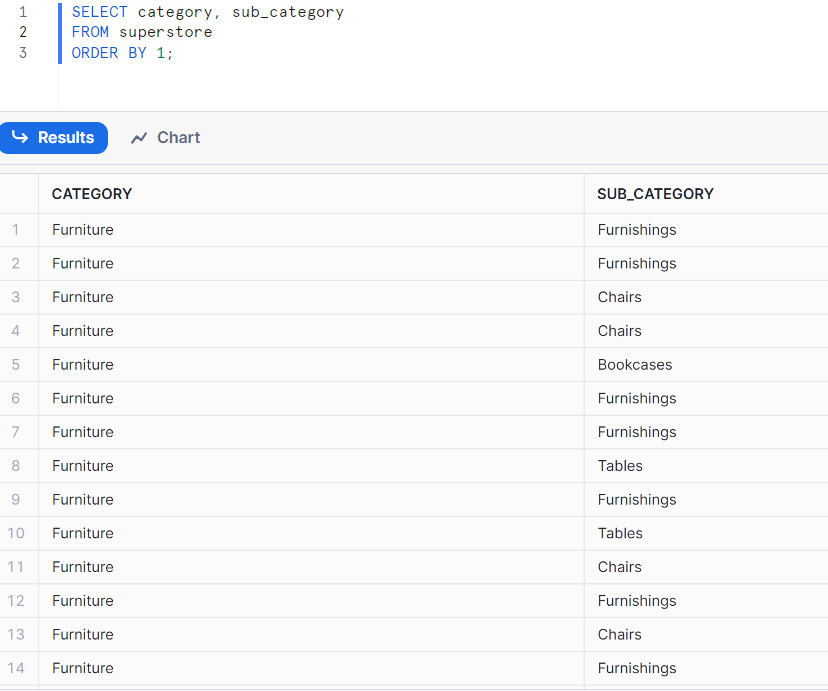
If I don't use GROUP BY, it will return so many rows with duplicated values. (Fig. 4). If the dataset is big, it will take a long time to return the result. Imagine if you need to compare the value from a table with the value in this table. It would take a long time.
This blog is quite long. So I will split this topic into 2 parts. In this first part, I followed the order of execution in SQL to list many options to optimize the performance. The structure of data and how big of the dataset also affect the performance.
The earlier filter you apply following the execution in SQL, the better performance will be. In the next part, I will continue with the HAVING, SELECT, ORDER BY, and LIMIT clauses. I hope this blog is useful to you if you are using or will use SQL in your data journey.
See you soon in the next blog! ^^