


In the previous blog, I shared some tips to improve the performance in SQL following the order of execution. I stopped at the GROUP BY clause. If you haven't read my first part, you can read it here.
In this blog, I continue to share some tips from the HAVING clause until the end.
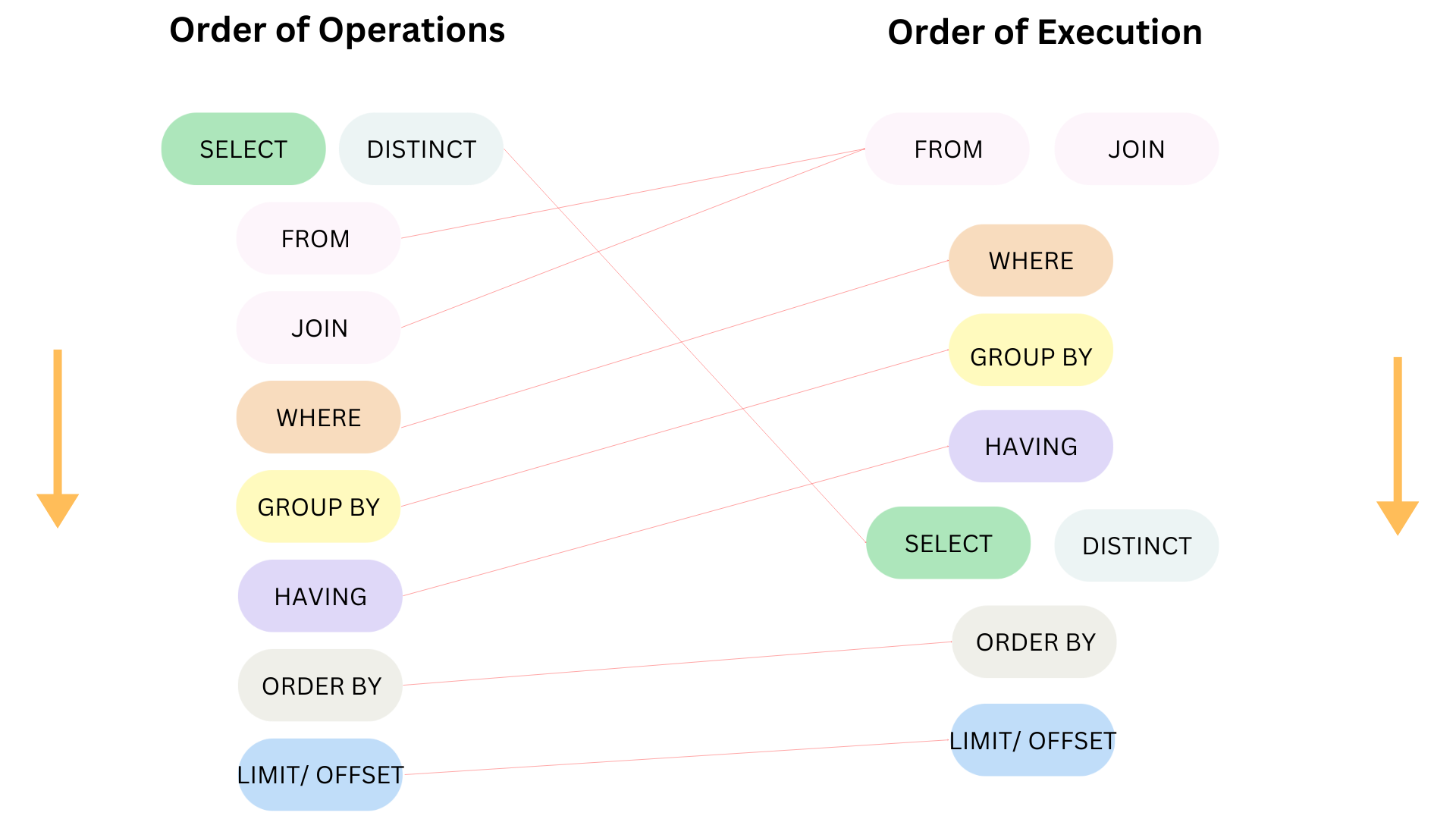
1/ HAVING
As I mentioned in the blog Order of Operations and Order of Execution in SQL (link), the Having clause is used to filter the data with the aggregation function (COUNT, SUM, AVG, ...), but it also can filter the data without using the aggregation functions. That is the first point we should avoid.
- Avoid using the HAVING clause to filter data on the fields without aggregate functions
For the normal fields (without using an aggregate function), we should filter the data from the WHERE clause. The WHERE clause will be executed early (second stage from the image above). It will reduce many rows if the condition in the WHERE clause is True.
- Avoid complex expressions in the HAVING clause
If you have complex expressions, you can consider using the temp tables, and CTE to calculate the value. Then, in the primary query, you can filter the data with the WHERE clause. At this time, all the calculations were executed in the CTE already, in the primary query, only need to filter the rows by the field.
2/ SELECT / DISTINCT
- Avoid using SELECT * if not necessary
As you know, the SELECT * will return all the fields in the table. If not necessary to print all the columns into the result table, you can consider listing some columns to return. It will reduce the number of marks on the view. The system doesn't take a long time to load all the columns.
- Avoid using complex subqueries in the SELECT clause if not necessary
Sometimes, when you need to return the values from other tables, you can add a sub-query in the SELECT clause. However, it could affect the performance. Instead, you can consider using the JOIN and/or the CTE to combine the dataset. In the primary query, you only need to return the column you want.
- Don't overuse the DISTINCT
The Distinct operator could help to remove the duplicated rows. But it could cause the performance to slow if overuse it. If the DISTINCT operator appears in the SELECT clause with many columns, the system will scan the whole table to check the value row by row; if the dataset is large, the performance will be very bad. Instead of using the DISTINCT clause, you can check the structure of the dataset first to see if there are any conditions in the fields to apply to filter rows.
1/If you find that you don't want the duplicated values in a few columns and you see the different values in other columns, you can create a flag column. Then, use the WHERE clause to filter rows.
2/ You can consider using the GROUP BY clause instead of using DISTINCT. I had an example of doing this in the previous blog. You can read it here.
3/ ORDER BY
- Consider using the filter in the WHERE or HAVING clause before Order the data
By filtering the data early, the dataset will order the data table faster.
- Avoid using ORDER BY on the large text columns
For the large text columns, the system will take a long time to compare the value in the current row with the other rows. Instead, you can consider using the Index and order by the indexed columns.
- Don't overuse the ORDER BY for multiple columns if not necessary
The more columns listed, the slower the performance will be. The system will need to compare the value in the current row of the listed first column with other rows. Then, keep working like that for other columns. Imagine if the dataset is large, it will take a longer time.
4/ LIMIT /OFFSET
- Using the LIMIT /OFFSET to limit the number of rows in the result when combining with ORDER BY
In some problems with the top/bottom N values, the user usually uses the LIMIT with the ORDER BY clause. There is another way to solve that problem is using RANK with the WHERE clause.
So, the question is: Between using the RANK with the WHERE clause and using the ORDER BY clause with LIMIT, which option will be better for performance?
=> The answer is the ORDER BY clause with LIMIT is better with the simple dataset. The RANK function is in the list of the WINDOW function. It will give a rank number for each row of the dataset, so it needs to scan for the whole dataset. However, in some complex problems, the RANK function is also an option. I have a blog that talks about all rank types in SQL here.
- For large datasets, consider filtering data instead of using OFFSET and using the small number value for OFFSET
OFFSET is used to skip the row in the dataset. Instead of letting the system process many rows in the large dataset. You can consider filtering data early in the WHERE, HAVING, or partitioning the table early. For the large number value of OFFSET, the system will take a long time to process.
These are all the tips that I summarized. I hope it's helpful for you if you are looking for a way to improve your SQL performance. Depending on each case, you can apply those tips differently. Again, the order of execution is important. When you understand how the RDBS works in order, you will get some tips to improve the performance.
I hope you enjoy reading my blog and good luck!
See you soon in the next blog!