


As a data analyst, I usually work on the numeric data. However, the text data can also give me some insight. Specifically, most companies that sell products, want to hear feedback and reviews from the customer. The text data from the feedback and reviews are very helpful, and insightful.
Based on that text data, I can analyze it to get insight into how the customer likes/dislikes the products, and what should be improved/ removed, which departments are doing good/bad. Then, the R&D department can make a decision or strategy to develop the product better or make some changes in a specific department.
With that useful case, I write this blog to share how to extract the word from each sentence in a dataset. Then, find the frequency of each word. At the end, I will share how to build a word cloud based on that data. I will walk you through:
1/ Write the Python script to extract words and find the frequency
2/ Apply Python script in Tableau Prep Builder
3/ Build a word cloud in Tableau Desktop
Throughout this blog, I used the Harry Potter script dataset from Kaggle. You can find the dataset that I used here.
Note that, the script could include some punctuation (commas, dot, ...). The dataset is in CSV format (Comma-Separated Values). It could be an issue when you download and put that dataset in the prepping data tool because it automatically recognizes commas as delimiters. To shorten this blog, I already prepared the data and stored it as an Excel file (.xlsx).
If you are ready, let's get started!
1/ Write the Python Script to Extract Words and Find the Frequency
First of all, you need to make sure that you already installed Python on your computer and also installed the Pandas and Scikit Learn packages. You can use any Python IDEs you like. I use Jupyter Notebook to demo.
First, I need to import the library that I need to use. In this case, I need to use the Pandas package for reading the file and storing data as a data frame. I also need to import the CountVectorizer function from Scikit Learn. (Fig. 1)

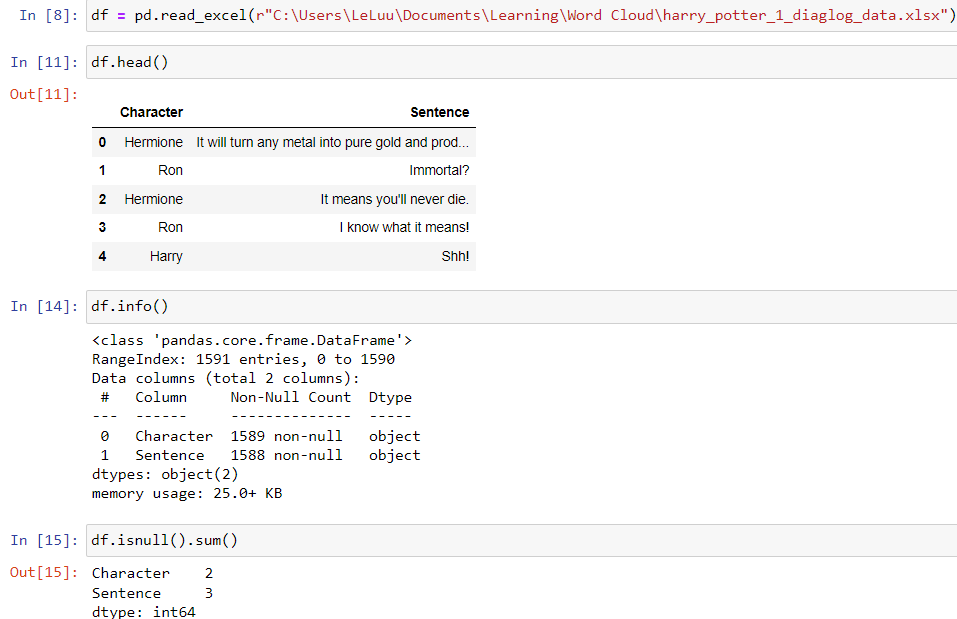
Next, I imported the dataset into Jupyter Notebook. The dataset is an Excel file, so I used the function read_excel from the Pandas package and stored it in the df variable. The file path has "\", but the Pandas package cannot decode it. You can type "\\" or put a letter r at the front of the file path. It will let Pandas package know that is a raw file path. (Fig. 2a)
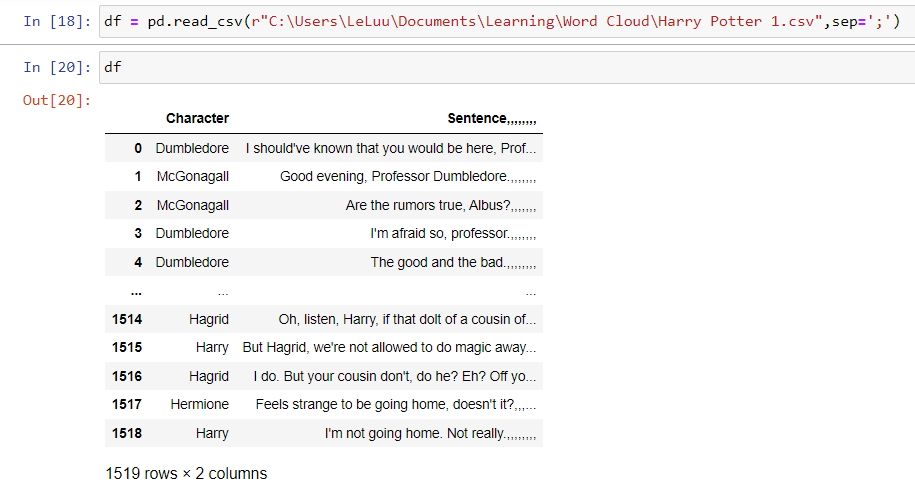
You can also import the CSV file with the delimiter as a semicolon ";". But then you also need to remove commas at the end.
There are two columns total (Character and Sentence). The total number of rows is 1591, but there are 2 null values in the Character column and 3 null values in the Sentence column. In this example, it doesn't matter, so I will keep those null values.
Next, I called the function CountVectorizer. Again, I recommend you read the documentation page from the Scikit Learn first at this link. The function has many parameters that you can apply. In this example, I will use the parameter stop_words.
Stop words are common words like "a", "an", "the", "also", "even",... To check the list of the stop words. I need to call the CountVectorizer and set the stop_words in English (you can set any language depending on the language of the text you are working on).
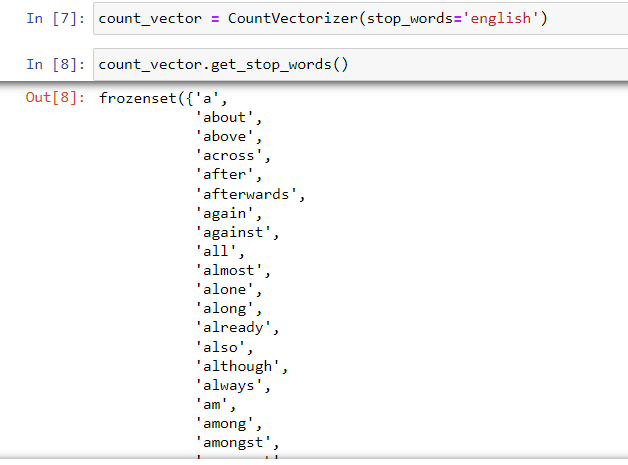
In Fig. 3, I called and assigned the CountVectorizer function to the count_vector. To get the list of the stop words, I call the function get_stop_words() from the variable count_vector.
Next, I fit and transform the text column that I want to count. In this example, my text column is df['Sentence']. So each unique word in a sentence will be stored in an index and count (not including the stop word). In the Sentence column, there are some number values, to make sure that is a string, I converted it into Unicode.
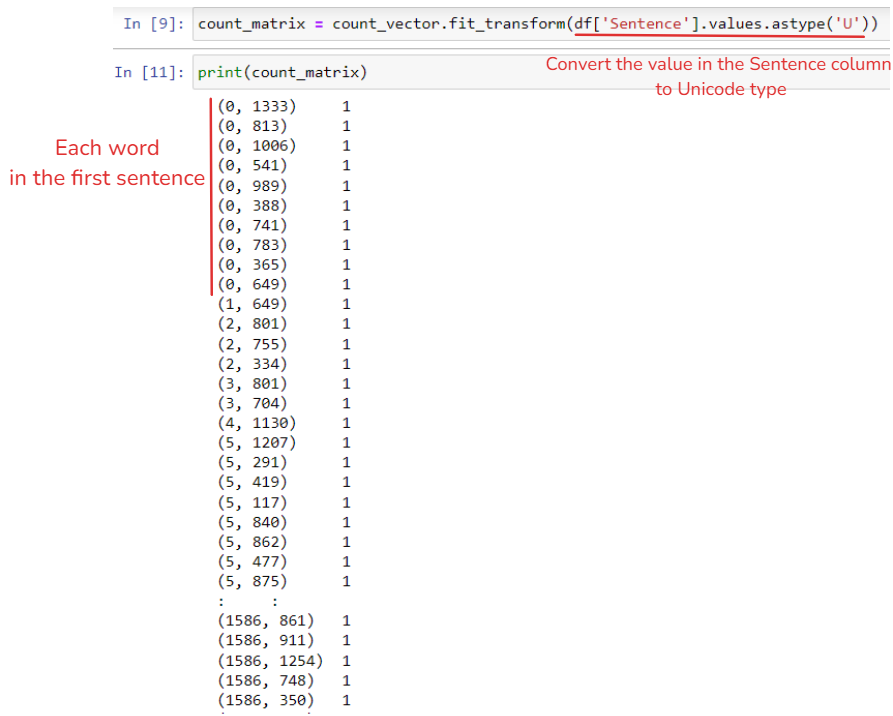
From Fig. 4, you can see each word is stored in a 2D matrix with the count value. However, it's difficult to know which word is that and how many repeated times of each word is for the whole column not a single sentence.
In the next step, I combine the word with the count number of each word by using the zip() function. The zip function will return the value that includes 2 values (the word and the frequency number). I used the sum function with axis=0 means I counted how many times the word repeated. (A1 is converted from the 2D matrix into the 1D matrix for counting). At the end, I assign the tuples to the freq variable. (Fig. 5)

In the final step, I only need to store the freq tuple in a data frame with 2 columns (Word and Frequency).
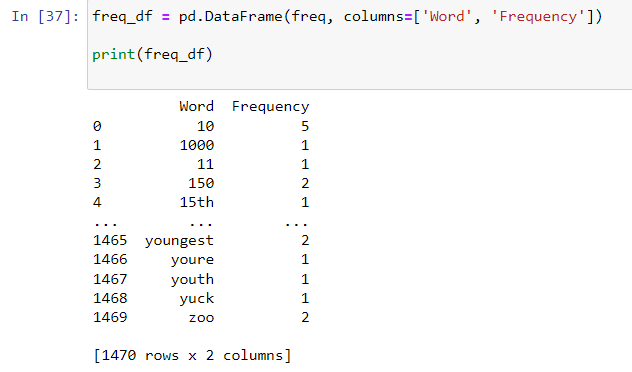
In Fig. 6, I stored the tuple in a data frame and printed that data frame out. There are 2 columns for Word and Frequency (1470 rows as 1470 unique words).
Cool! That is the code that I will put in a Python file to input in Tableau Prep Builder.
2/ Apply Python script in Tableau Prep Builder
You can use any text editor software to type the Python code in. First of all, remember to import the CountVectorizer from the Scikit learn package. Then, I defined a function called word_count with an argument as a data frame. Later in Tableau Prep Builder, we will pass the dataset (as a data frame) into the word_count function.
In the CountVectorizer function, I changed a little bit by adding some parameters. The analyzer will define that I want to tokenize the word. ngram_range(1,2) will define the word should be unigrams and bigrams. At the end of the function, I return the data frame.
In Tableau Prep Builder, the Python script is a little bit different. You should have a function called get_output_schema to declare the variable that you will output with its data type. You can read more from the Tableau page here.
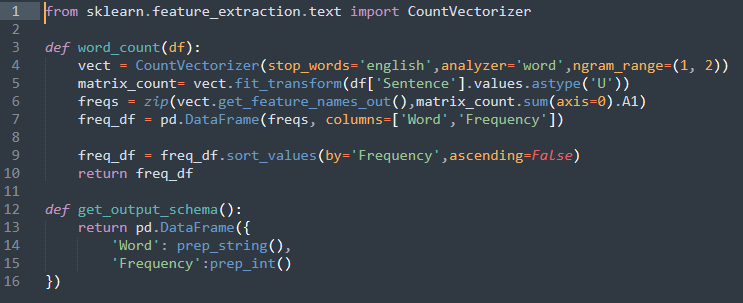
Then, save it under the Python format (.py).
Next, open the Command Prompt on Windows (Terminal on Mac) to activate TabPy. Make sure that TabPy is listening.
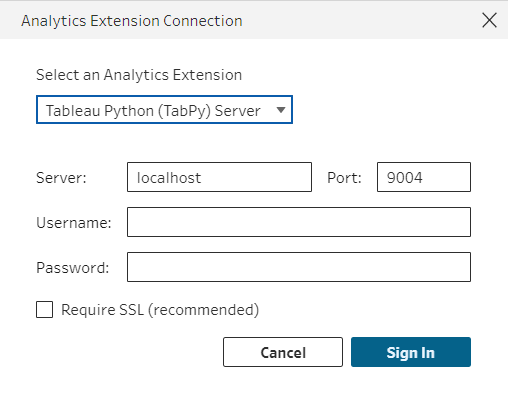
Then, open Tableau Prep Builder. Go to menu Help > Settings and Performance > Manage Analytics Extension Connection. Choose Tableau Python (TabPy) Server. I am running on the local machine, so I type localhost for Server and 9004 for the port number. (Fig. 9)
Then, I input the Harry Potter dataset into Tableau Prep Builder. From the Raw dataset (.CSV file), the system automatically chooses the delimiter as the comma (But we don't want that because there are many commas in the text). Many columns were generated as F1, F2, .... (Fig. 10)
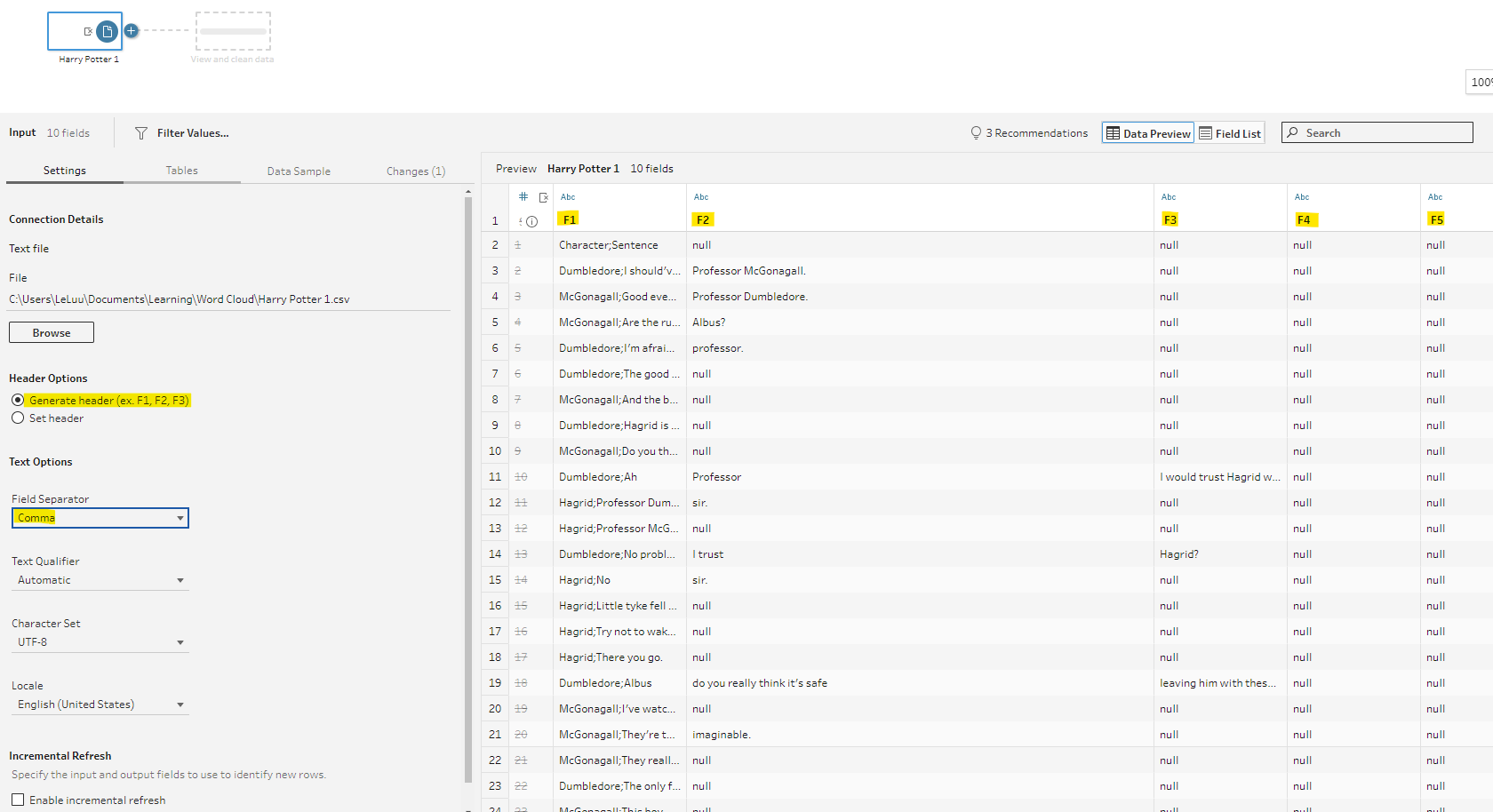
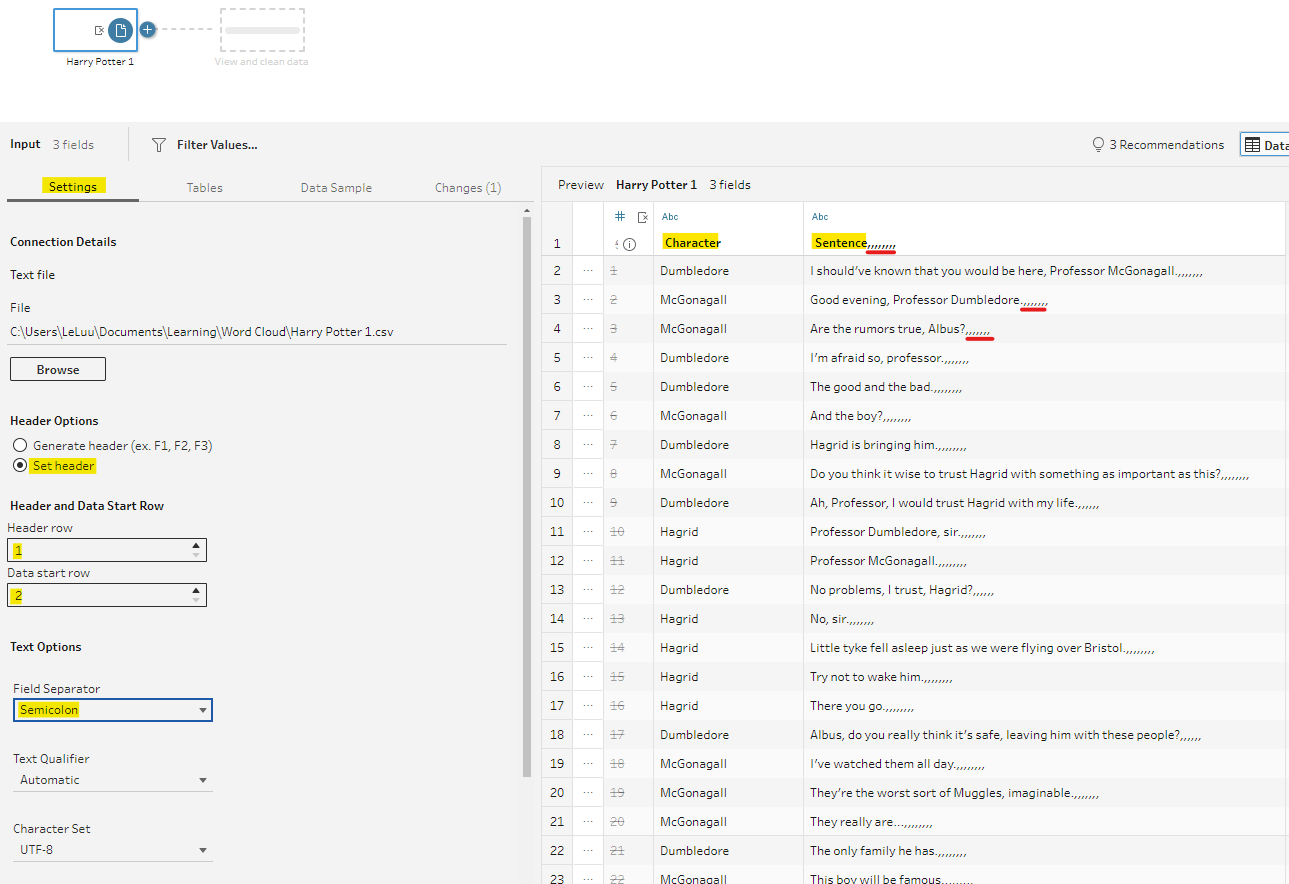
To fix that issue, in the Settings tab, I chose Set Header for the Header Options. Then, set the Header Row is 1 and the Data Start row from row 2. The Field Separator now is Semicolon. However, you can notice that the result in the Sentence column included many commas at the end (Fig. 11). It doesn't matter with our Python script because we only count the words.
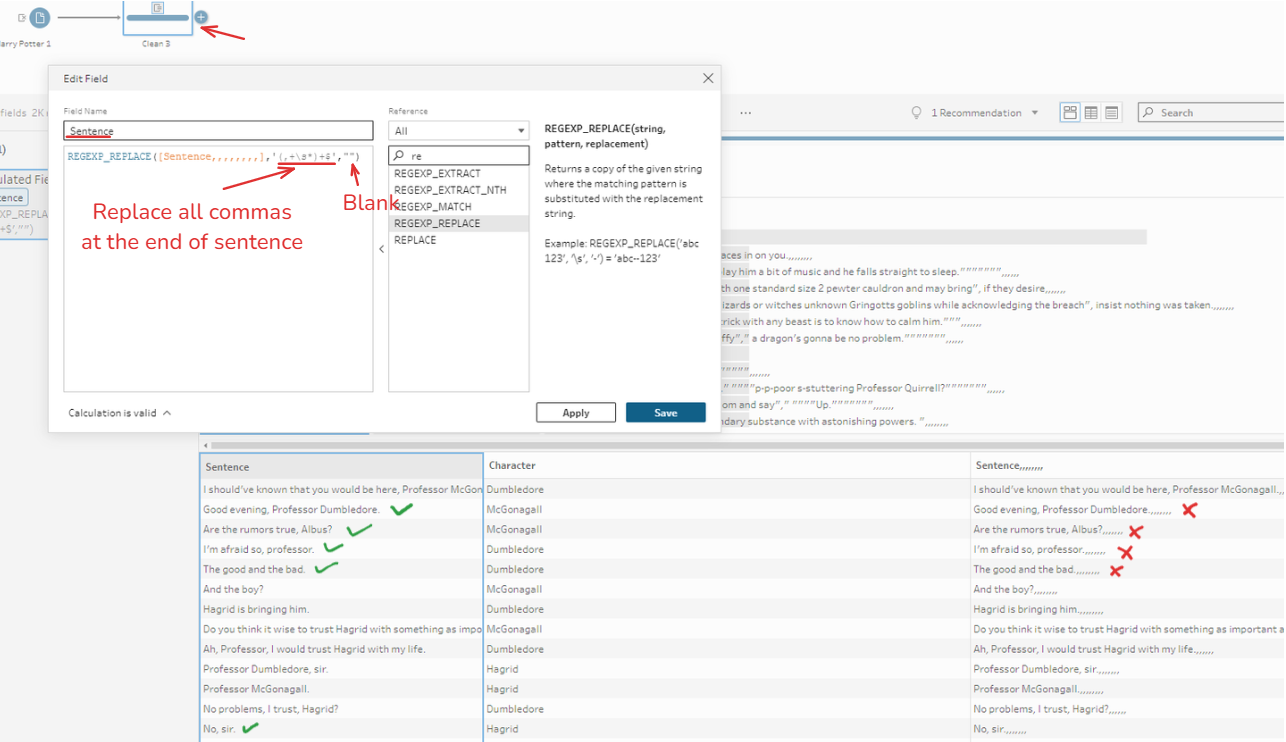
To get rid of those commas, I use the REGEX_REPLACE function in Tableau Prep Builder. I created a new calculated field from the Clean tool. I put the name for that field as Sentence.
REGEXP_REPLACE([Sentence,,,,,,,,],'(,+\s*)+$','')
That calculation means replacing everything after commas (one or more than two or could be a space) with a blank.
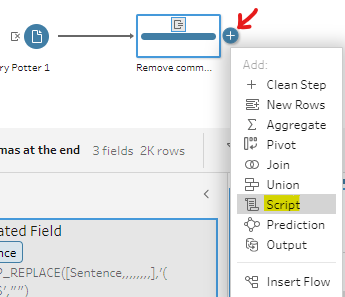
Then, click Apply and Save. You will see the result in Fig. 12 above. Next, I hover over the clean tool at the end to add the Script tool. (Fig. 13)
Click on the Script tool, and in the Settings tab, choose Tableau Python (TabPy) Server. The File Name is the Python file that I saved earlier. The function name is the name of the function that I declared in that file. (Fig. 14)

Congratulations!!! You got the frequency of each word from the Harry Potter script. Next, I only need to connect to an Output tool and output the file to import in Tableau Desktop.
3/ Build a word cloud in Tableau Desktop
In Tableau Desktop, I import the output file from Tableau Prep Builder. In the Marks panel, I choose Text. Then, drag the Word field into Color, and Text Label. I drag Frequency into the Size.
There are many words, but I don't want to show them all. I drag the Frequency field into the Filters box. Then, you can adjust the frequency you want. (Fig. 15)
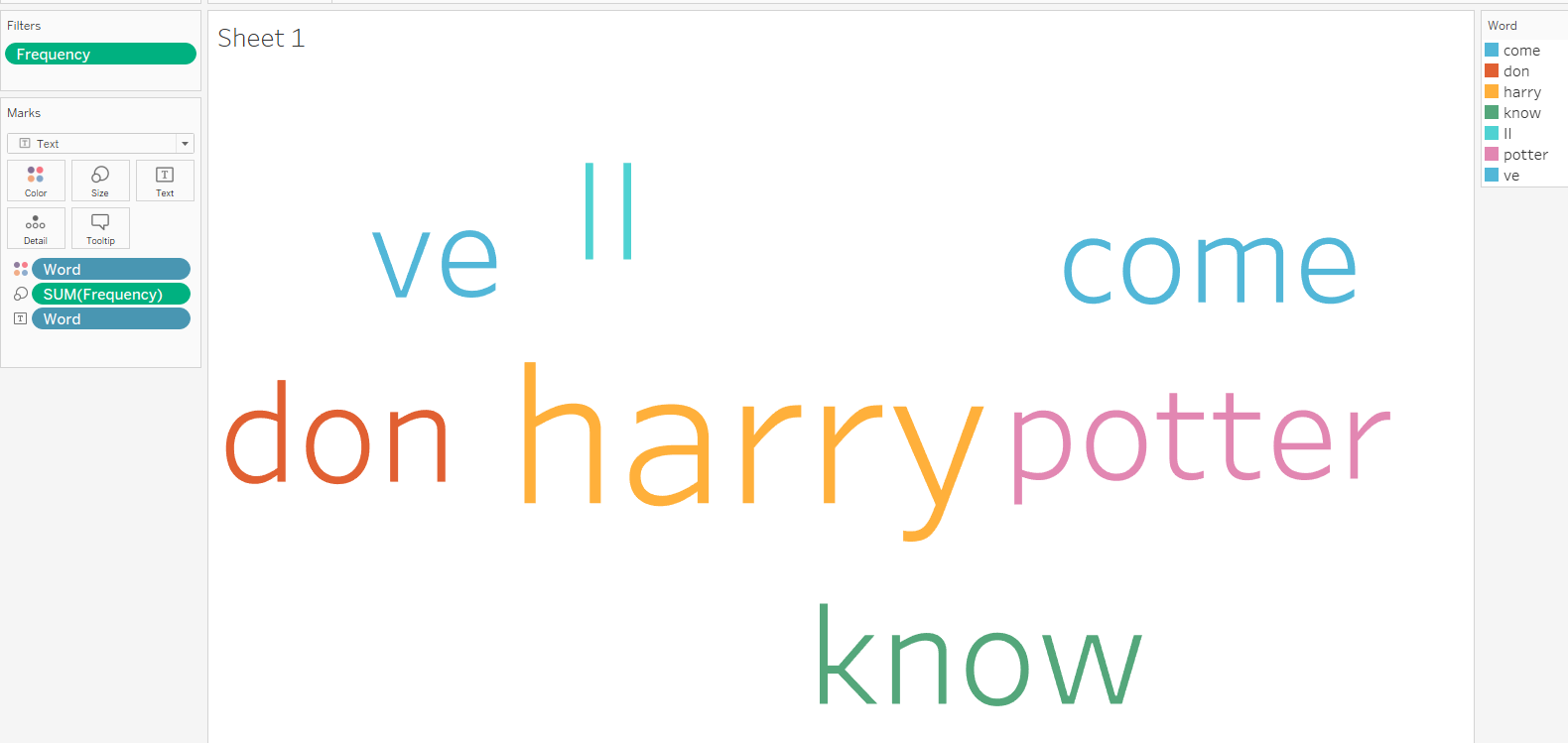
I set the parameter in the CountVectorizer with ngram_range(1,2). So you can use the calculation to show the word cloud with unigrams or bigrams by letting the user switch it by parameters.
This blog is long. But I hope it's helpful to you. By going through this blog, I hope you know how to write the Python script to extract the word from each sentence in a column and how to get the frequency values of each word. Also, you know how to prepare data if the system separates the column wrong and apply Python script in Tableau Prep Builder. Finally, you can get the word cloud on Tableau Desktop.
I hope you enjoy my blog and see you soon in the next blog! ^^