


In the first part, I introduced what is API and its process. I also walked through some main points about the JSON structure, extracting data from API in Python, and in Tableau Desktop with TabPy. However, the JSON structure in the first blog is simple.
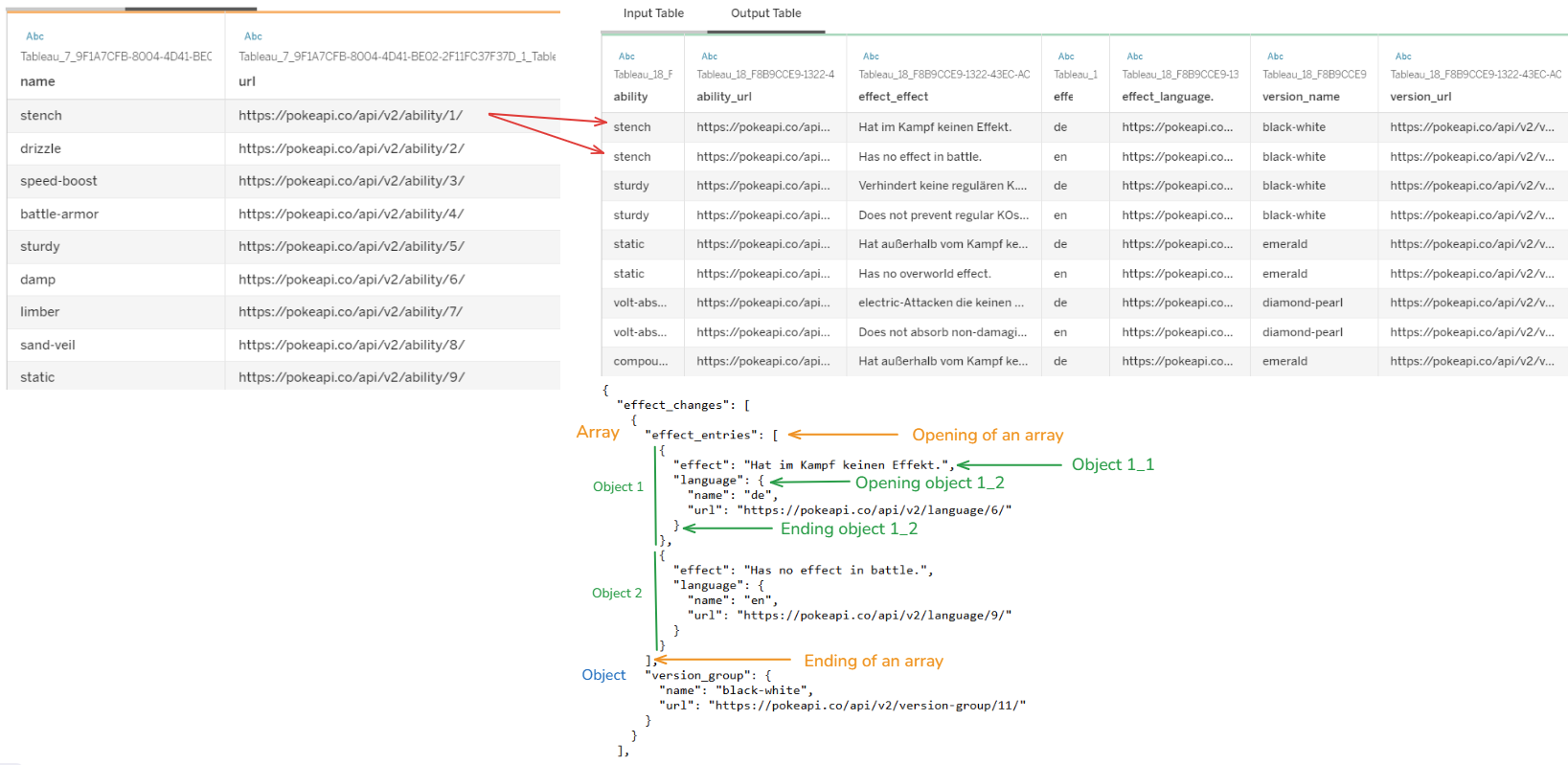
In Fig.0 above, the table on the left side is the output table where we extracted data from the previous blog. From each URL in that table, I want to extract data and store it in a table with a complex JSON structure. As you see the JSON structure at the bottom, the effect_change is an array with 2 elements: effect_entries array and version_group object. Inside the effect_entries array, there are 2 small objects.
That JSON structure mixed array with object. So, in this blog, I will share:
1/ Analyze the complex JSON structure
2/ Parse data from the complex JSON structure into a data table with Python
3/ Relationship between tables and apply the Python script in Tableau Desktop
Are you ready to continue to extract data from API? :)
Let's get started!
1/ Analyze the complex JSON structure
As I mentioned in the first part, the JSON structure can contain object(s), and array(s). In each object or array, it could contain multiple objects and/or arrays. Let's dive deep into the complex JSON structure.
For example: I have a sample URL from the output table from the previous part: https://pokeapi.co/api/v2/ability/1/
If you click on that link, you will see the JSON structure from the first ability. It's difficult to see what is showing on the screen. There are many arrays, objects with squared brackets, and curly braces everywhere.
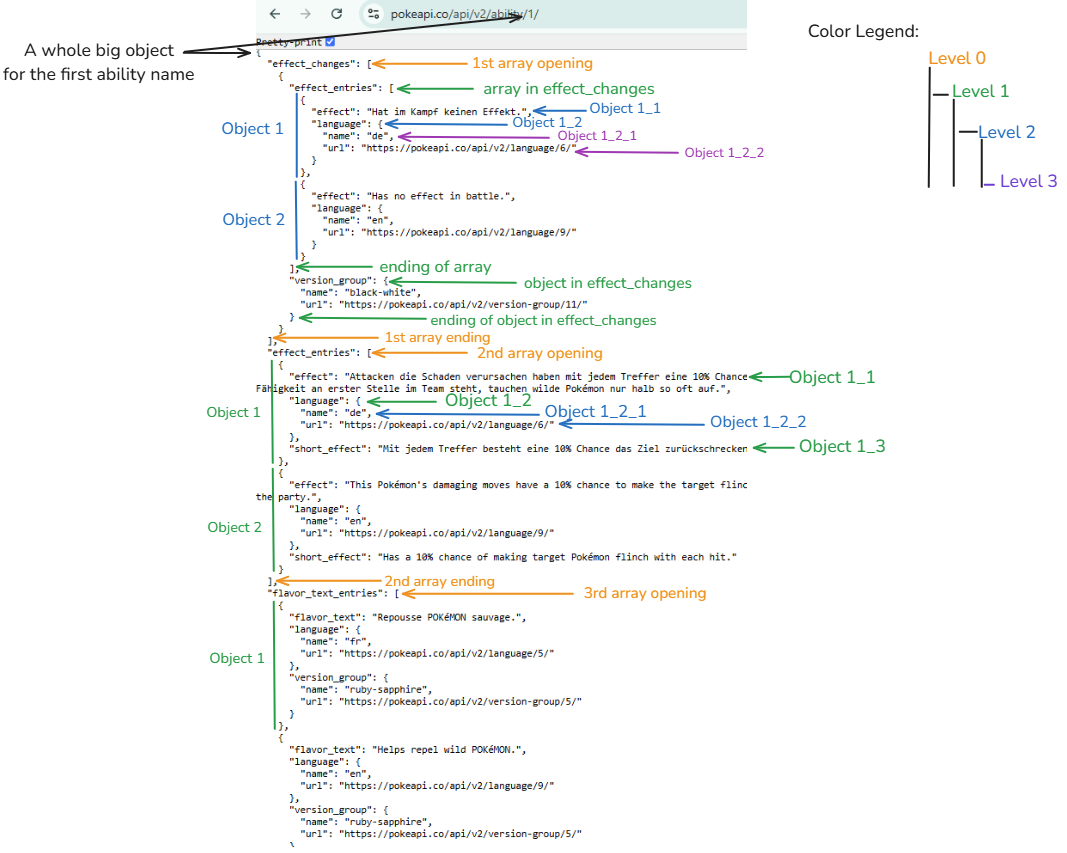
If you use the JSON editor, it could help a little bit with the indentation. However, it's still hard to see the structure. In Fig. 1, I analyzed the JSON structure and took a note on the screenshot. From Fig. 1, you can see there are 3 arrays in the big object. The structure for each array is also different.
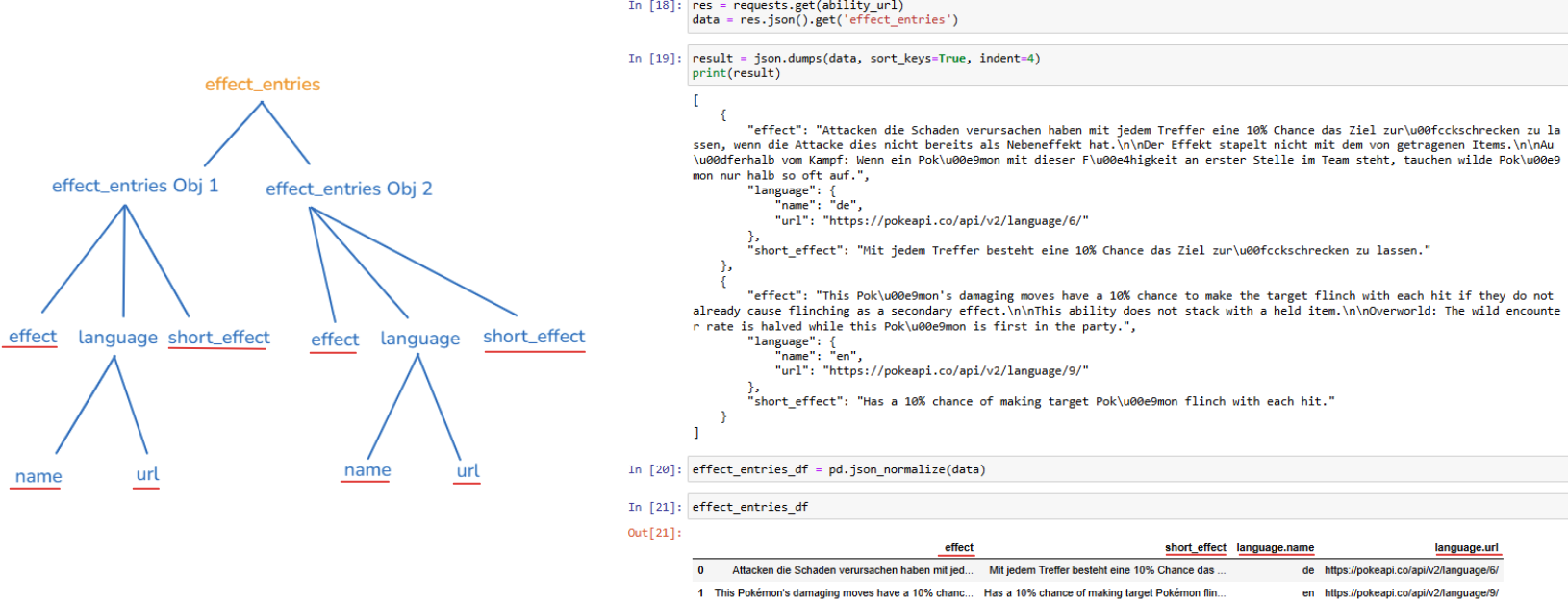
- In the first array (effect_changes), there is an array (effect_entries) and an object (version_group). In the effect_entries, there are 2 objects.
- In the second array (effect_entries), there are only 2 objects. Each object contains multiple objects without any arrays inside.
- In the third array (flavor_text_entries), there are multiple objects. For each object, there are 3 objects insides. The structure is consistent.
The second and third array structure is quite easy to flatten. However, the first array contains a mixed object and array. It could be a challenge for us.
If I split that JSON structure into a tree diagram, it would look like this:
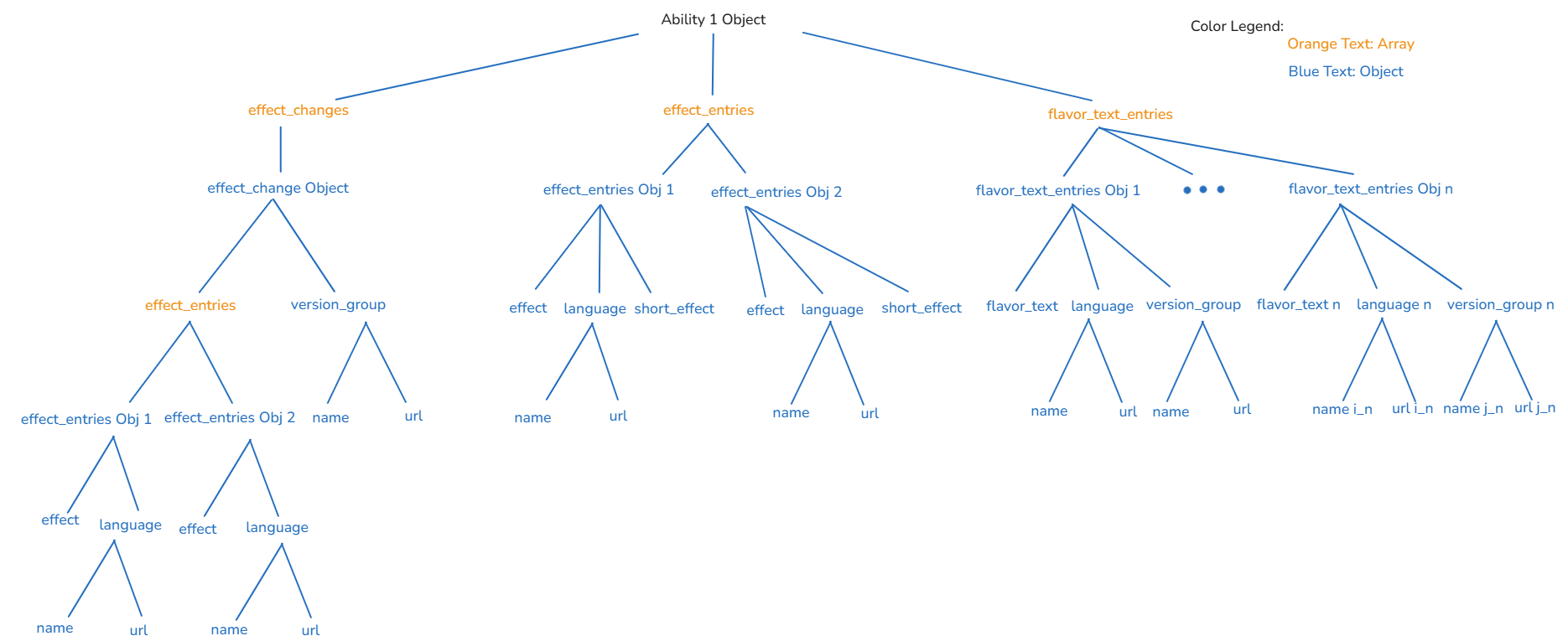
From the tree diagram in Fig.2, it's easier to see the structure of JSON data. Let me explain from that tree diagram:
- At the top, there is a big object when retrieving data from the ability API.
- Inside that big object, there are 3 keys (effect_changes, effect_entries, flavor_text_entries). The value of each key is an array.
- In the effect_changes array, there is only 1 object containing 2 keys (effect_entries array and version_group object).
- The value in effect_entries is an array containing 2 objects (effect and language). The language key contains 2 objects (name and url).
- The version_group key value contains 2 objects (name and url).
- In the effect_entries array, there are 2 objects. For each object, it contains 3 objects (effect, language, and short_effect).
- In the language object, contains 2 objects (name and url).
- In the flavor_text_entries array, there are n objects. Each object contains 3 objects (flavor_text, language, and version_group).
- In the language object, there are 2 objects (name and url).
- In the version_group object, there are 2 objects (name and url).
After understanding the JSON structure, the question is: How to convert that JSON data into tables?
Let's go to the next section!
2/ Parse data from the complex JSON structure into a data table with Python
From the JSON structure, we know that an object contains many arrays and an array contains many objects. To solve this problem, I will split each array into a separate table. It means that I have 3 tables (effect_changes, effect_entries, and flavor_text_entries).
I open my Jupyter Notebook to continue from my previous work. If you haven't read my first part, you can read it here. I will start extracting data from the easy table first and the complex JSON structure at the end.
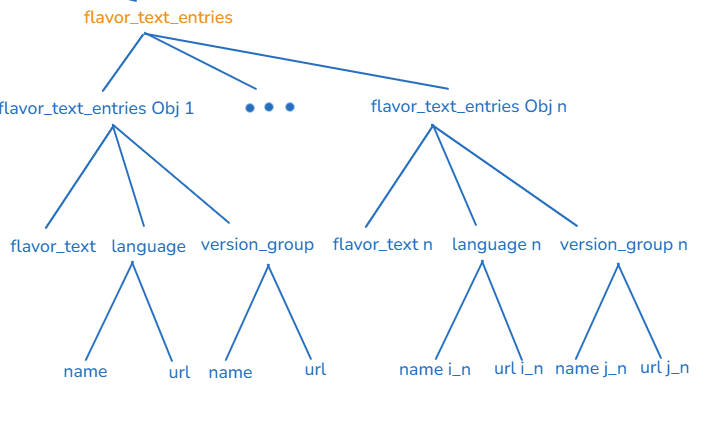
a/ flavor_text_entries
The structure of flavor_text_entries is an array containing objects and nested objects without a nested array (Fig. 3).
I do the same steps as in the previous blog. I took the first ability url as an example and assigned it to the variable ability_url. Then, imported all necessary packages.
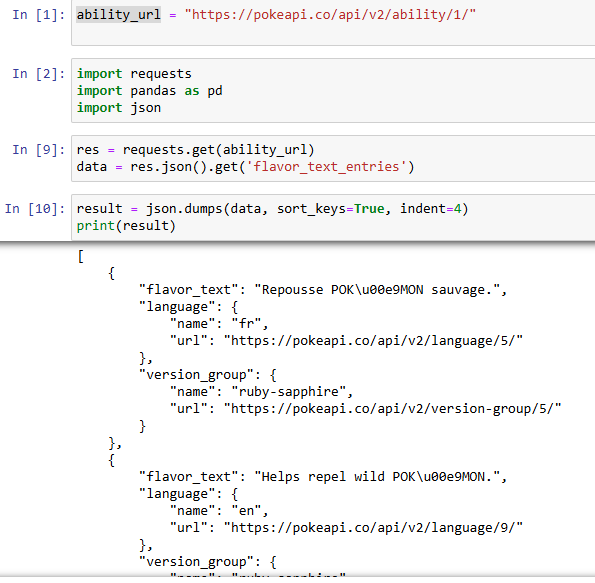
In line 9, I sent the request with that ability_url and assigned it to the res variable. Now, if I only want to retrieve the flavor_text_entries array, I will use the get function with the name of the array I want.
data = res.json().get('flavor_text_entries')
Then, I print out the result. You can see the output of flavor_text_entries data is the same as Fig. 1.
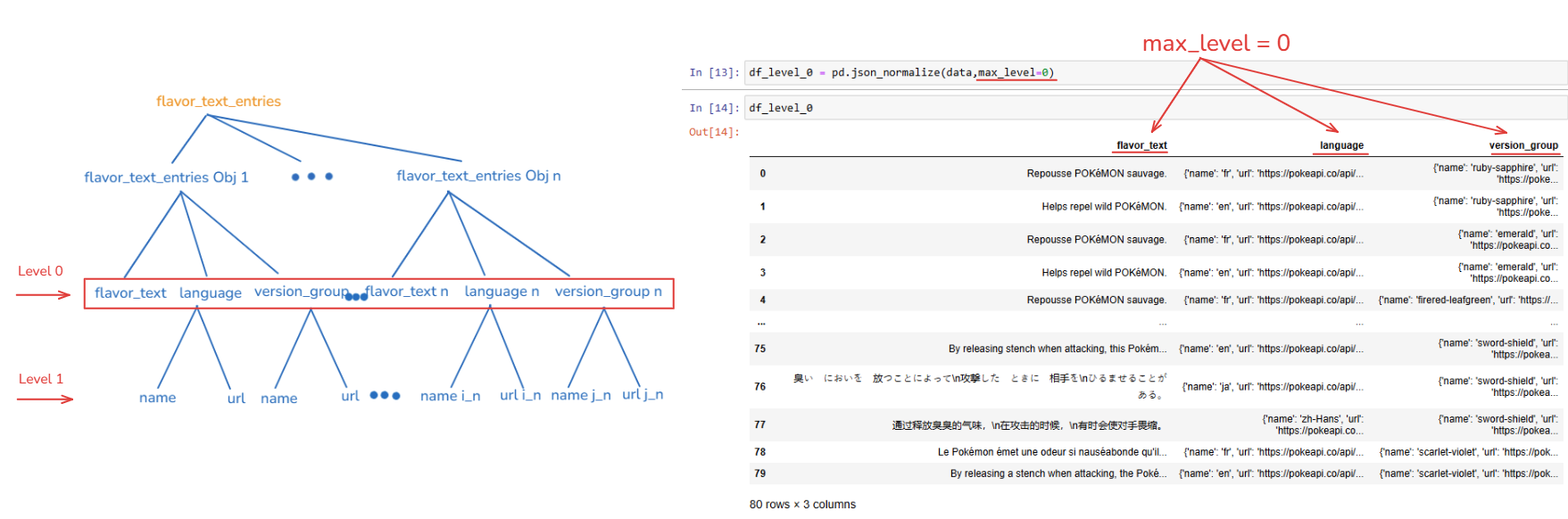
There is a parameter in the json_normalize function from the pandas package called max_level. You can adjust the level (depth of the dictionary) to normalize.
If you put the max_level=0, you can see the output has 3 columns (flavor_text, language, and version_group). The language and version_group fields contain a dictionary.
By default, it is None (normalize all levels). If you want to flatten all levels, you don't have to set the max_level or you can also set the max_level=1. Both ways return the same output (Fig. 6).
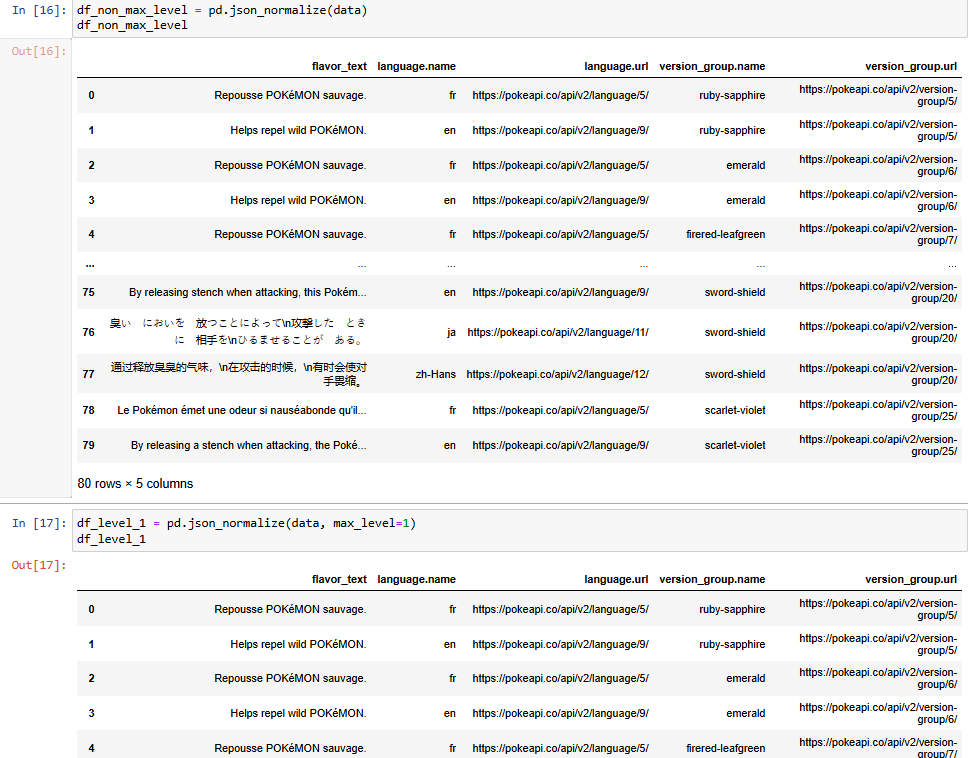
From the output in Fig. 6, you can see the output is the same. There are 5 columns in total. The language object and version_group object contain 2 nested objects. So pandas package automatically renamed the column name (language.name, language.url, version_group.name, version_group.url).
b/ effect_entries
For the effect_entries table, I also do the same as the flavor_text_entries table above (Fig. 7).
c/ effect_changes
This table is complicated when an array contains 1 object. That object contains an array and an object. The nested array also contains multiple objects.

We cannot apply the same method that we did in flavor_text_entries and effect_entries above. The reason is in the effect_change object, we have a nested array (effect_entries), which is not a dictionary. Therefore, in Fig. 8, you can see the output containing 3 columns (effect_entries, version_group.name, and version_group.url).
Now, my goal is to normalize data in the nested array branch and then normalize data in the version_group branch.
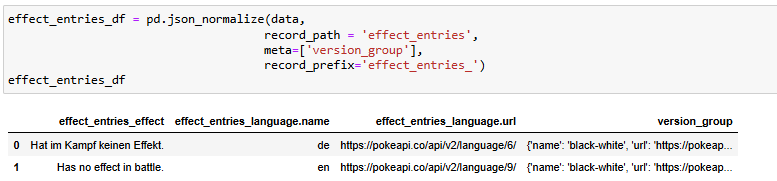
I also used the json_normalize function from the pandas package. In this case, I added some parameters:
- record_path: is the path in each object to list of records. In our case, we have effect_entries as a list. So, I put effect_entries here.
- meta: will list all fields to use as metadata for each record in the result table. Same as the index, the object will appear in each row in the result table. In our case, I want to keep version_group to normalize later. So, I put the list of version_group.
- record_prefix: is the prefix you want to add to the field after normalization. I put effect_entries because we are normalizing in the effect_entries branch.
In Fig. 9, you can see from the output table that we normalized all levels in effect_entries, but the version_group branch is still the same. So we need to normalize all levels in version_group branch.

I also used the json_normalize function from the pandas package and input column version_group from the effect_entries_df data frame. Then, assign the value back to the data frame with 2 new columns (version_name, version_url). In the final step, you only need to drop the version_group column.

Let's jump into Tableau to build the relationship between tables.
3/ Relationship between tables and apply the Python script in Tableau Desktop
In this step, make sure that you already activated TabPy and connected Tableau Desktop with TabPy. I used the same workbook that I was doing in the previous blog (Fig. 12).

Next, I drag the New Table Extension to connect to the previous table extension. Then, double-click on the new Table Extension you just dropped.
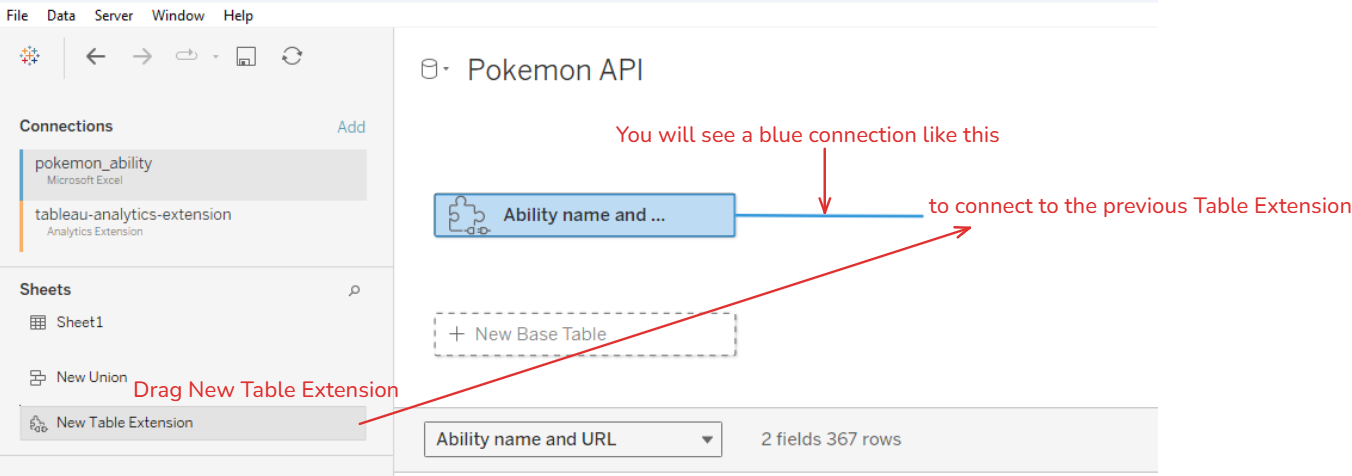
We want to continue with the output from the previous table extension which means we want to extract data from each URL in that table. On the left panel, I do:
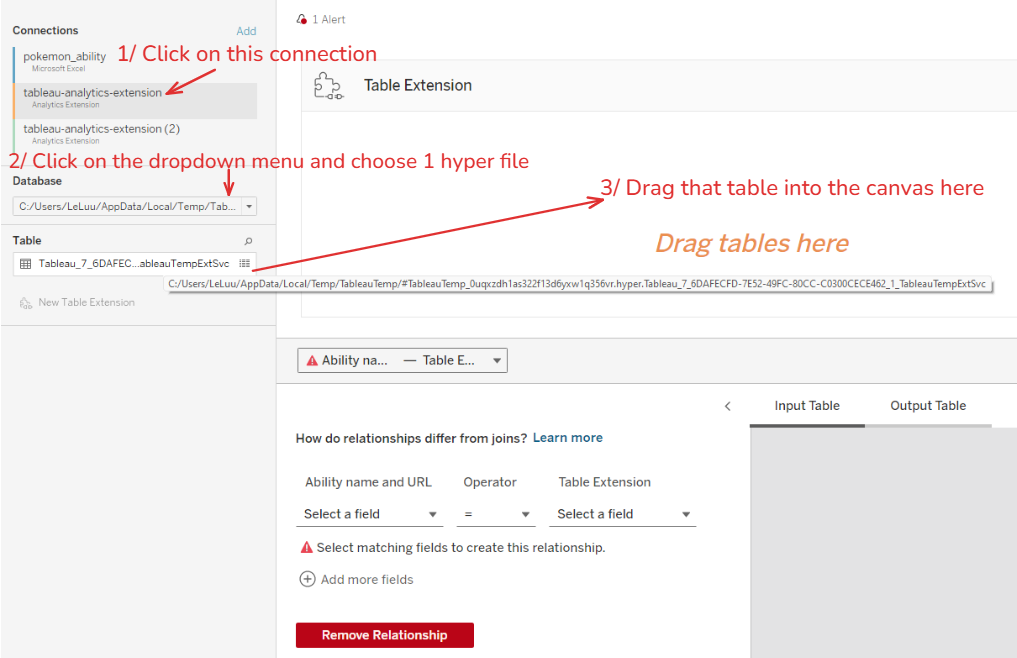
- Click on the connection table-analytics-extension. That is the output table from the previous table extension.
- In the Database area below, I click on the drop-down menu. It will show 2 temp hyper files. That is the dataset from the previous table extension. You only need to select either one.
- Your selected table will appear in the Table area below. Then, drag that table into the Table Extension canvas.
Now, you will see the data in the Input Table tab at the bottom right corner. Let's start adding the Python script. There is a little difference from what we did in Jupyter Notebook because I want to write a function and apply it to each URL in the previous table.

- First, we need to import some packages. I see that Tableau already added the pandas, json, and requests packages. For me, I use the alias from pandas as pd. If you don't use that alias, you have to write the full "pandas" word.
- Second, get the input from the output table that we drag and drop before. It will be represented as _arg1.
- Then, define a function called parse_json_from_url and pass 2 arguments (ability_name, url). Those arguments are 2 columns from the previous table.
- I will copy the same code that we did in Jupyter Notebook here. But there is 1 different point.
- At lines 9 and 10, I added 2 lines of code to handle errors if data is missing, I will return the empty data frame. When you normalize the data with meta is version_group, the output in Tableau will return Null. It will cause the normalization step at line 20 error because cannot normalize the null data. Therefore, we need those 2 lines. It will solve the problem.
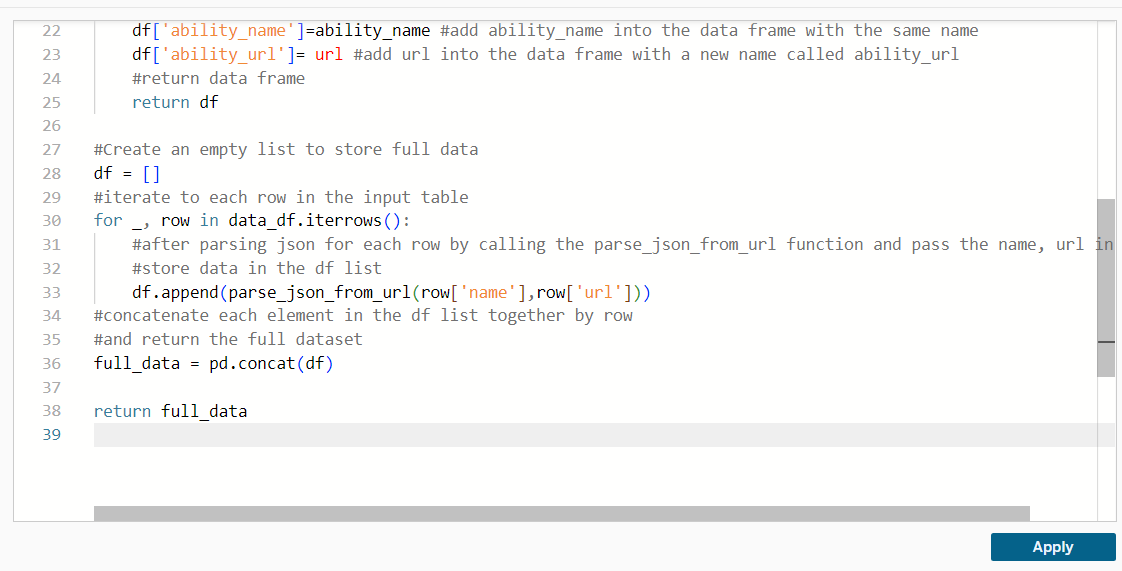
After defining the function, I need to iterate each row in the input table to retrieve data from each API in the url column. Then, I combine all data by row using the concat function from the pandas package. Finally, I only need to return the full_data.
Click on the Apply button. But you won't see the result in the Output Table tab because we built a relationship with the previous table but didn't set the key to join.
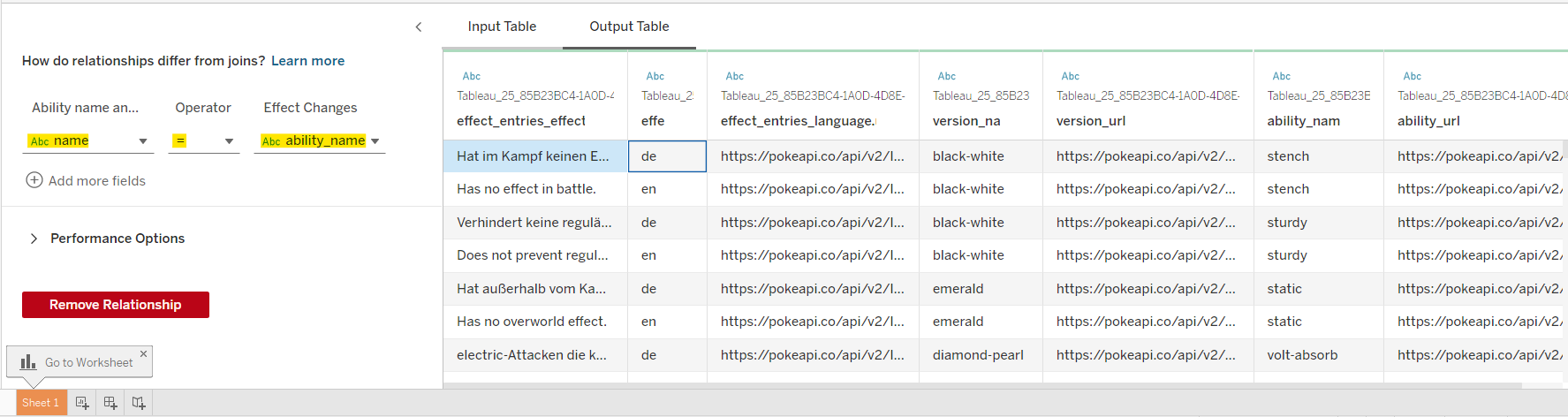
I set the name column in the Ability name and URL table and ability_name from the Effect Changes table that we just output.
Congratulations!!! You have the full dataset now. But wait a second, how about the other 2 tables?
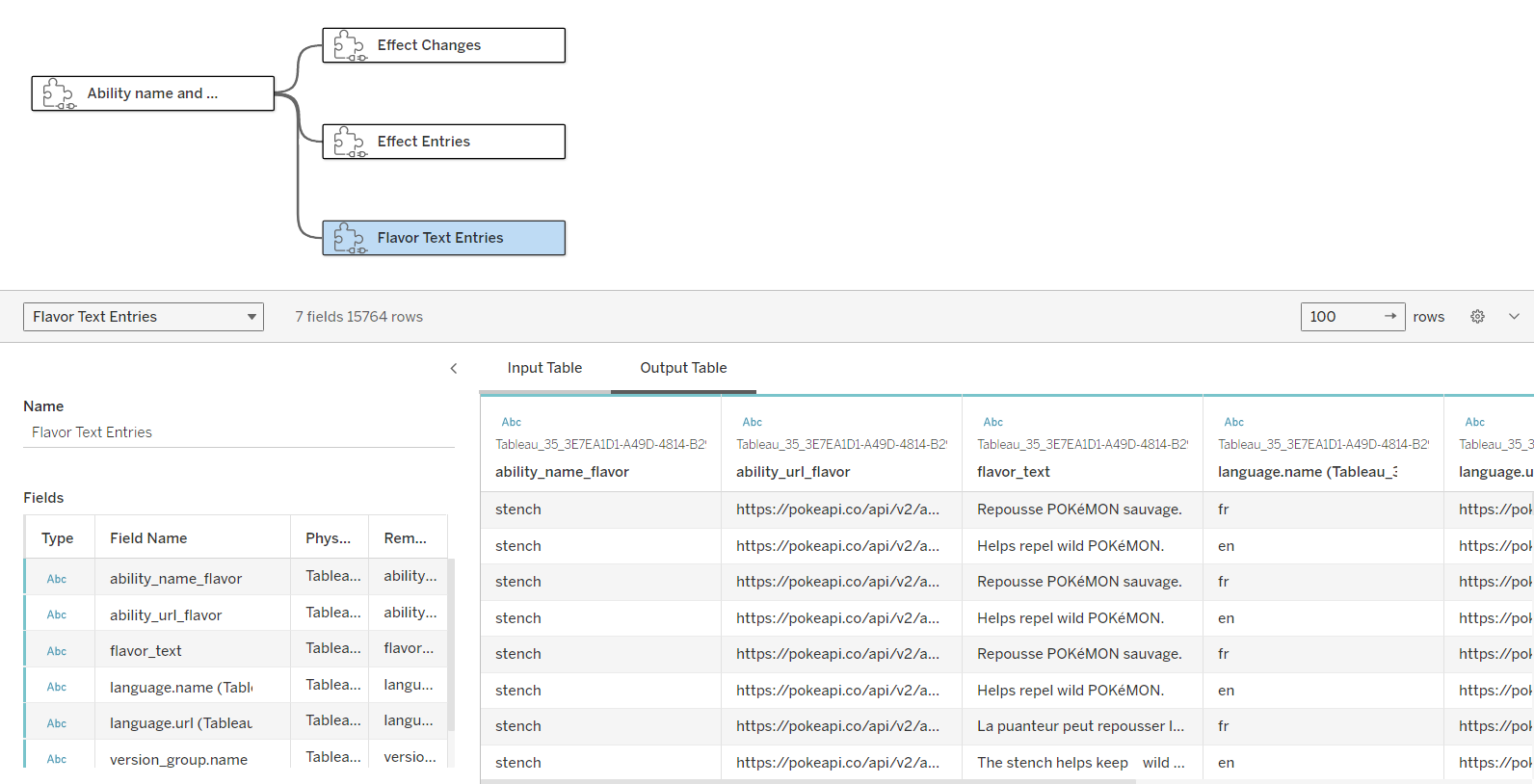
I also do the same for the other 2 tables. But one thing that you should notice is the column name. I used the ability_name and url for all 3 output tables. If you don't change the name of each table, Tableau will automatically generate the column name by adding Tableau_..... So rename the column name before outputting the table.
If you read my blog until here, I hope that my blog brings some helpful resources to you. I know this blog is long, but I try to explain everything in detail. Then, you can try to apply it to your projects.
In this blog, I analyzed the complex JSON structure and how you can split it into tables. I shared how to normalize the data in Python for the complex JSON structure. In the final part, I built a relationship model in Tableau by using the Table Extension in Tableau Desktop to retrieve the full dataset from API.
The key is the JSON structure. After you understand the JSON structure, it will be easy for you to flatten data in the way you want. I hope the tree diagram is helpful for the JSON structure.
Thank you for reading my blog! Hope to see you again in the next blog with more interesting things ahead :)