


Before starting a data analytics project its important to make sure that you fully understand the data by doing as much data discovery as possible. Data discovery will allow you to detect patterns and answer specific questions based on your project aims. By the end of your data discovery you should be able to explain what a row in your data shows and what your level of granularity is.
Firstly, upload your data into Alteryx and connect it to any data discovery tool. Depending on the format of your data I would recommend either using the field summary or basic data profile.

The Basic Data Profile tool shows an overview of your dataset and outputs the information for further analysis. You can select the number of records you would like to output in the configuration pane. The output will provide information for each field which will be shown at row level.

The field summary tool outputs a summary report of descriptive statistics for the selected data columns.

The "O" output displays a table in the Results window with detailed information about each column in the incoming data. Each column becomes a row in the results, with column type and additional information.

The "R" Output should be connected to a browse tool which will then produce a static report that appears in the Configuration window of a Browse tool.
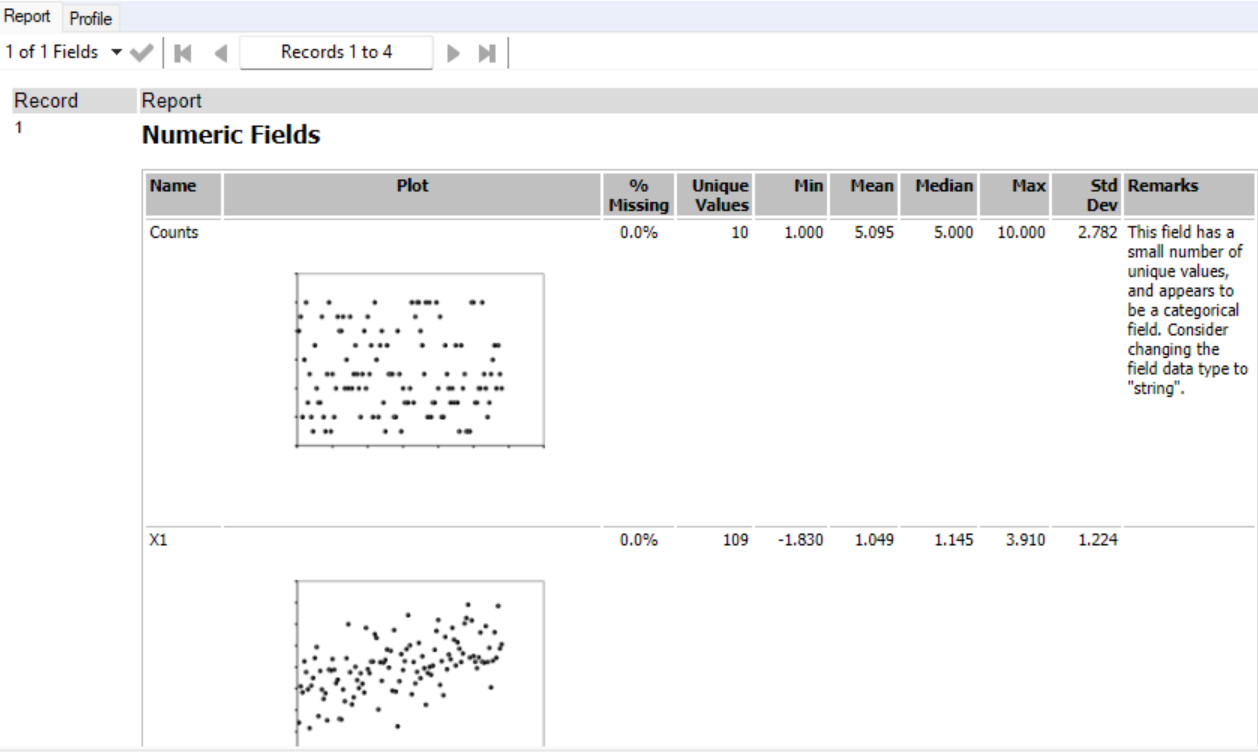
Alternatively, you can use the browse tool alone, although it might not be as informative and additional tools might be needed to explore the data. For example, with large datasets the browse tool will not show the exact number of unique values and you will need to add a unique tool.
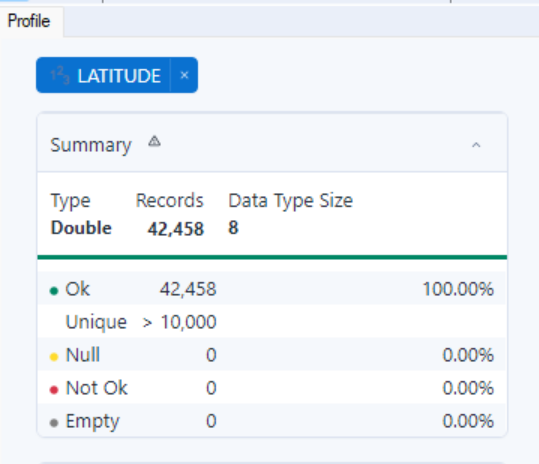
Once you have run these tools, write down the answers for these questions:
- What does each column tell us?
- What type of field is each column? (string, numeric, boolean, spatial, etc)
- What range of values are there for each column? (min, max, median, average, number of unique and missing values for numeric and string where possible). This will mainly be found in the data discovery tool output.
- Is this a realistic range/expected range of values based on your knowledge of the topic? For example, is the average too high/low etc.
- When there are any missing values, is this expected or a potential problem?
- Then finally: what defines a unique row in each data set?