


In 2020, the world generated a staggering 64.2 zettabytes of data, and by 2025, this number is expected to soar to 181 zettabytes (source Statista.com). To put this into perspective, 1 zettabyte equals 1021 byte, highlighting the sheer volume of data being created every second. As organizations continue to collect and store massive amounts of data, the challenge won't be the size of the data you're working with, but rather how to design an efficient data ingestion framework that ensures the correct data is processed and cleaned for the applications that require it.
So what exactly is data ingestion, and why is it so important?
What is Data Ingestion?
Data ingestion is the process of collecting and importing data from various sources into a centralized system, where it can be stored, processed, and analyzed. It is the initial phase of a data pipeline, serving as the foundation for all subsequent data processing and analysis activities.
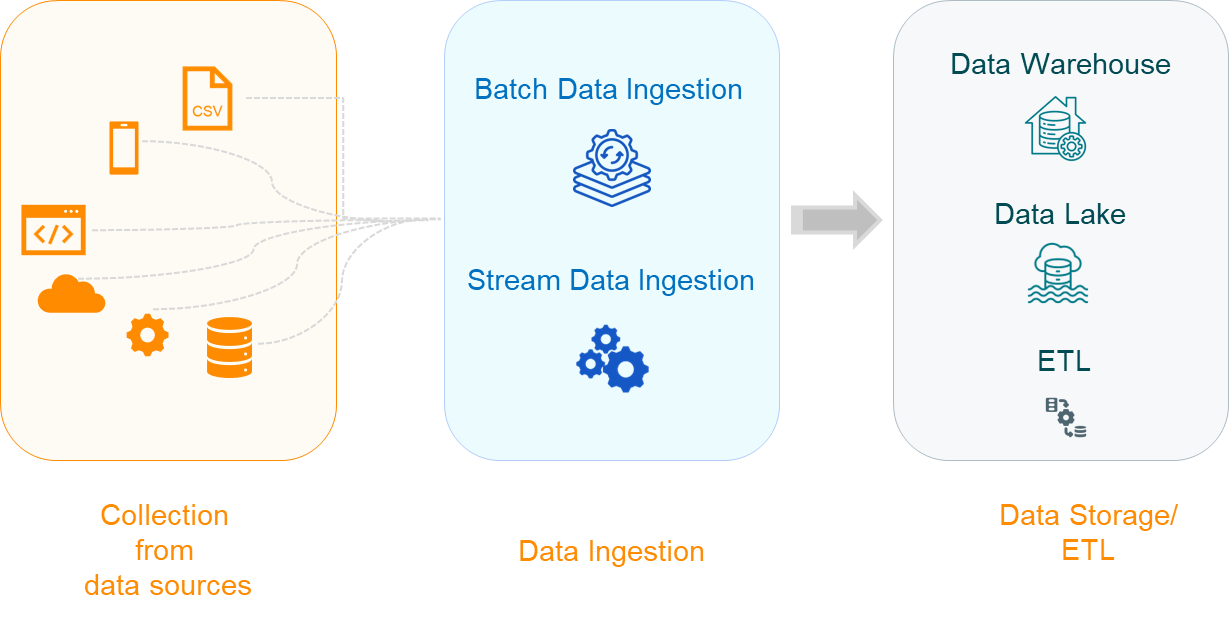
Data ingestion involves gathering data from a wide variety of sources, such as databases, APIs, IoT devices, and third-party applications, and then moving this data to a destination, such as a data lake, data warehouse, or cloud storage system.
Why is Data Ingestion Important?
Efficient data ingestion is crucial because it ensures that data is available in a timely and reliable manner for analysis. Without a robust ingestion process, organizations may face issues like data delays, inconsistencies, or loss, all of which can lead to incorrect insights, flawed decision-making, and missed opportunities.
Here are a few reasons why data ingestion is so important:
- Real-time Analytics: Many businesses rely on real-time data to make decisions. A well-designed data ingestion process ensures that data is ingested quickly and efficiently, enabling real-time analytics.
- Scalability: As data volumes grow, the ingestion process must be scalable to handle increasing amounts of data without compromising performance.
- Data Quality: Proper ingestion methods help maintain data quality by filtering out noise and ensuring consistency, which is critical for accurate analysis.
- Compliance and Governance: Data ingestion processes ensure that data is captured in compliance with regulations, making it easier to manage and audit later.
Types of Data Ingestion
There are two primary types of data ingestion methods:
-
Batch Data Ingestion: In this method, data is ingested in chunks or batches at scheduled intervals. It is suitable for scenarios where real-time data processing is not required, such as end-of-day reports or periodic data updates. However, it may introduce latency as data is not available immediately.
-
Real-time (Streaming) Data Ingestion: Real-time ingestion involves continuously collecting and processing data as it is generated. This method is ideal for applications that require immediate data updates, such as monitoring systems, financial transactions, and IoT sensors. While real-time ingestion minimizes latency, it can be more complex and resource-intensive to implement.
Tools and Services for Data Ingestion
When it comes to data ingestion, organizations have a variety of tools and services to choose from. These can be broadly categorized into two types: Ingestion SaaS (Software-as-a-Service) and Ingestion Tech. Let’s explore each in detail.
1. Ingestion Tech
Ingestion tech refers to the tools and frameworks that organizations can deploy and manage on their infrastructure. This approach offers greater control and flexibility but requires more technical expertise.
- Pros:
- Customization: Ingestion tech allows organizations to build tailored data ingestion solutions that meet specific requirements.
- Cost Control: By managing the infrastructure, organizations can optimize costs, especially for large-scale deployments.
- No Vendor Lock-In: Organizations retain control over their data and infrastructure, reducing the risk of vendor dependency.
- Cons:
- Complexity: Ingestion tech requires significant technical expertise and resources to implement and maintain.
- Maintenance: Organizations are responsible for updates, security, and scaling, which can be resource-intensive.
- Time-Consuming: Building and maintaining custom ingestion pipelines can be time-consuming, delaying time to insight.
- Examples of Ingestion Tech: Apache Kafka, Apache NiFi, Amazon Kinesis, etc.
Apache Kafka: A distributed event streaming platform known for its scalability and real-time data processing capabilities. It is one of the most popular tools for real-time data ingestion.
Originally developed by LinkedIn, Kafka is designed to handle high-throughput, low-latency data streams. It is often used for building real-time analytics applications, event-driven architectures, and microservices. Netflix, Spotify, LinkedIn, and Uber are some of the users of Apache Kafka.
- It can handle scale horizontally by adding more brokers to handle increasing data loads without degrading performance.
- It can process millions of message per second and uses a distributed commit log ensuring messages are stored on disk and replicated across the cluster to safeguard against data loss.
- While Kafka itself does not perform complex data transformations, it seamlessly integrates with stream processing frameworks such as Apache Kafka Streams, Apache Flink, and Apache Spark Streaming.
- Kafka’s distributed architecture can be complex to set up and manage, requiring significant expertise.
,2. Ingestion SaaS
Ingestion SaaS platforms are cloud-based services that offer a fully managed data ingestion solution. These platforms handle the complexities of data ingestion, including data collection, transformation, and loading, allowing organizations to focus on analysis and insights.
- Pros:
- Ease of Use: SaaS platforms are designed to be user-friendly, with pre-built connectors and workflows that simplify data ingestion.
- Scalability: These services are built to scale automatically as data volumes grow, making them suitable for organizations of all sizes.
- Maintenance-Free: SaaS providers handle all maintenance, updates, and security, freeing up internal resources.
- Cons:
- Cost: SaaS platforms can be expensive, especially as data volumes increase.
- Limited Customization: While SaaS platforms offer ease of use, they may lack the flexibility and customization options that some organizations require.
- Examples of Ingestion SaaS: Fivetran, Stitch, Airbyte, etc.
Airbyte: An open-source data ingestion platform designed to simplify and automate data integration workflow. has gained popularity due to its flexibility and developer-friendly approach. It allows organizations to build and manage custom data pipelines with ease, making it a viable alternative to commercial SaaS platforms.

- Airbyte is free to use and can be customized to meet specific requirements, making it a cost-effective solution.
- It supports a wide range of data connectors and allows users to create custom connectors as needed. The link to the connector registry is here.
- It supports Incremental Updates, i.e., it effectively updates only the data that has changed since the last extraction.
- Airbyte’s active community contributes to a growing list of connectors and features, ensuring continuous improvement. This also means that the quality and availability of connectors can vary.
- While suitable for small to medium-sized deployments, Airbyte may require additional configuration and infrastructure to scale for larger workloads.
Conclusion
Data ingestion is the critical first step in any data pipeline, setting the foundation for all downstream processes, from transformation to analysis. With the exponential growth of data, organizations must carefully choose the right tools and strategies for their data ingestion needs.
While Ingestion SaaS platforms offer ease of use and scalability, they come with higher costs and potential vendor lock-in. On the other hand, Ingestion Tech provides flexibility and control but requires significant technical expertise and maintenance.
Tools like Apache Kafka and Airbyte offer powerful options for real-time and custom data ingestion, each with its own set of pros and cons. Ultimately, the choice of tools will depend on an organization’s specific requirements, resources, and long-term data strategy.