


According to wikipedia, RegEx or Regular Expression is a sequence of characters that specifies a match pattern in text. Usually such patterns are used by string-searching algorithms for "find" or "find and replace" operations on strings, or for input validation. Regular expression techniques are developed in theoretical computer science and formal language theory.
In plain talk: it is basically created by a mathematician in the 50's but now we use it to help us find patterns of words within text or strings. I know it seems like we're speaking in math now, and in truth it is somewhat like learning a new language, but with practice you'll be able to master it. This blog will demonstrate how you can replace, tokenize, parse, and match words using RegEx.
Dragging in the RegEx Tool
First open up Alteryx and simply drag in your dataset, then navigate to your search bar or the ribbon on the top and find your RegEx tool.
The RegEx tool has one input on the left and one output anchor on the right.
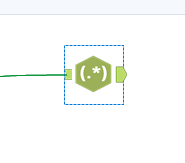
Configuring your RegEX
Now let's look at the configuration pane. When you have the tool selected, the configuration pane on the left will change.
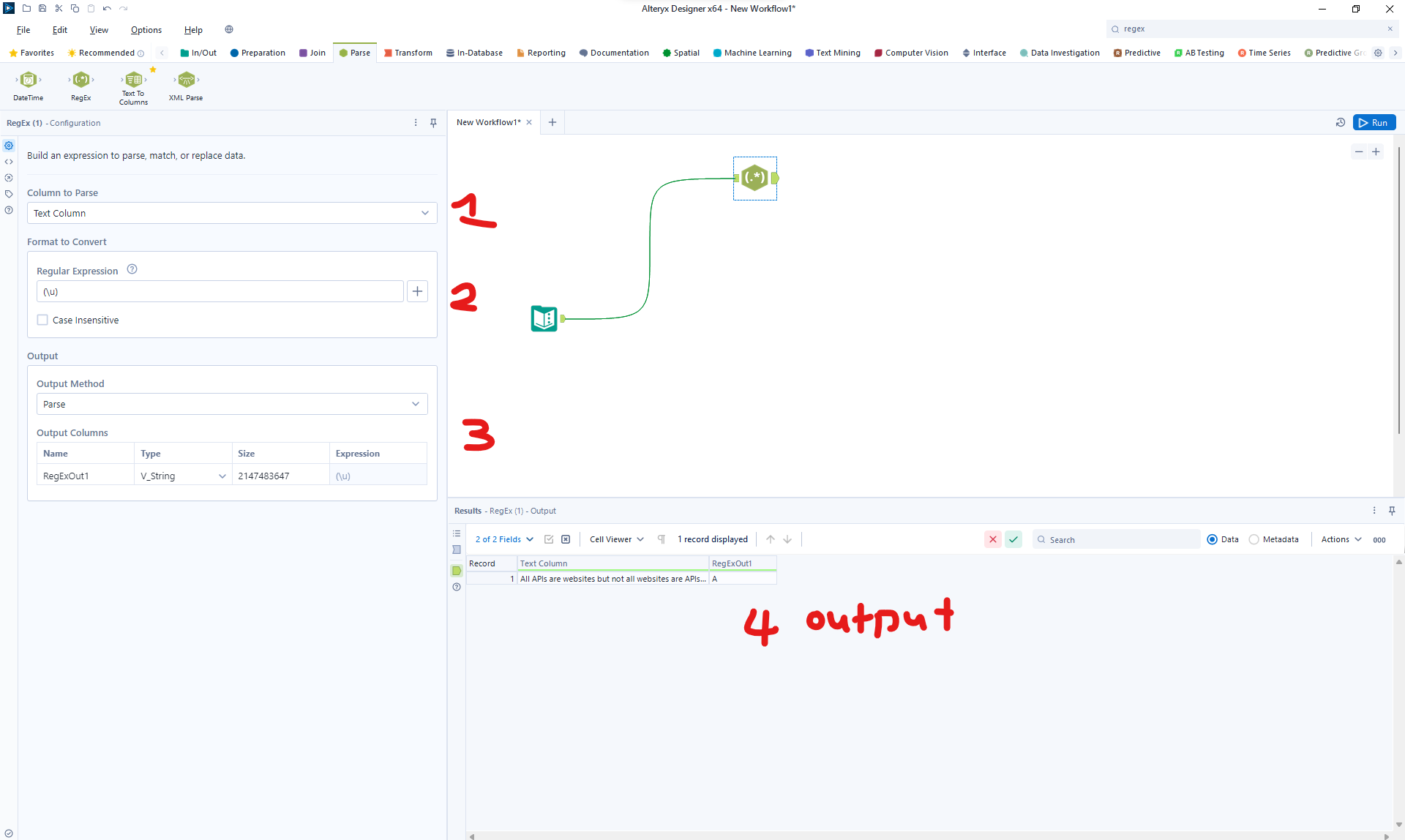
- Column to Parse: This section will allow you to choose which column of your data to target.
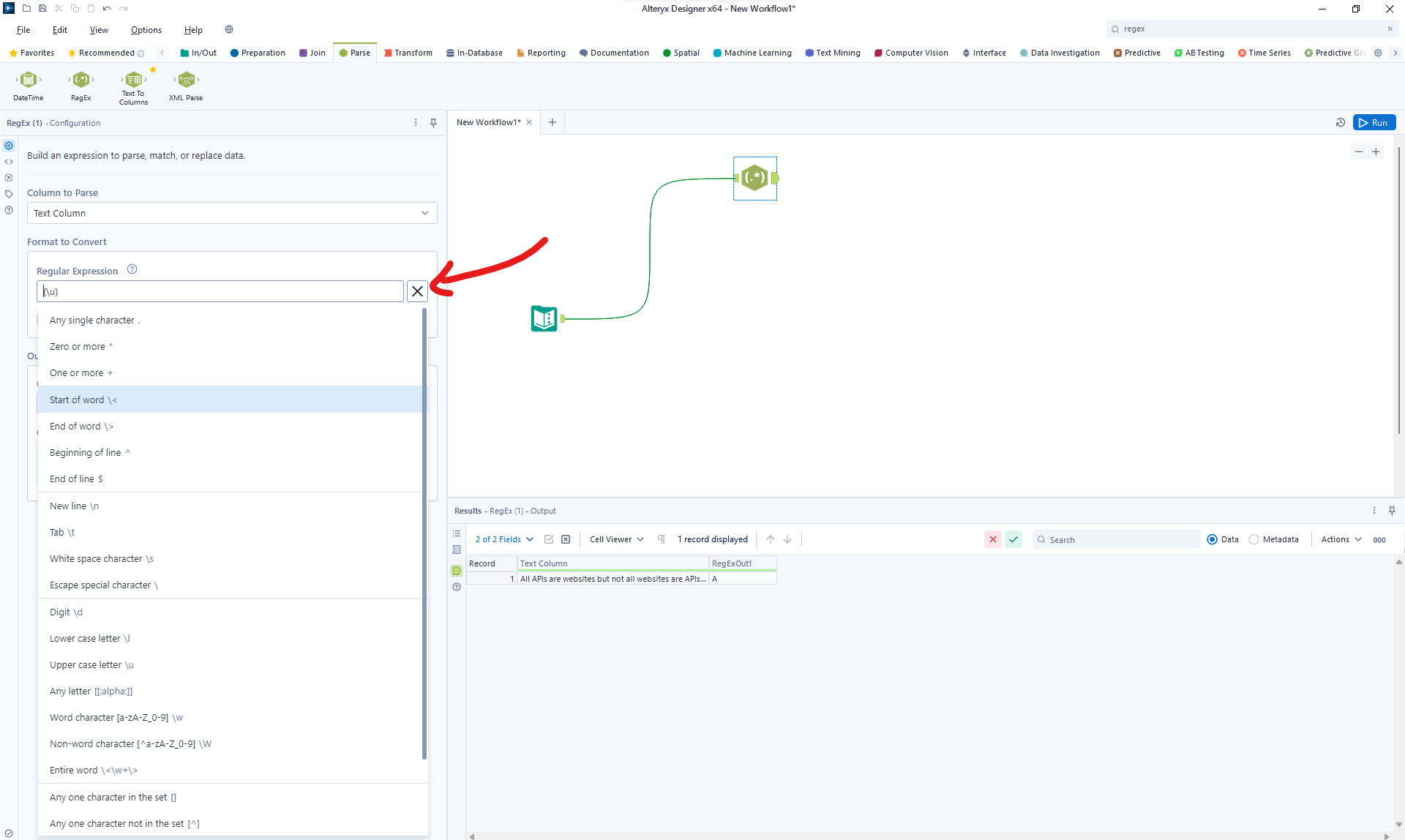
- Format to Convert: This section on the configuration pane will allow you to type in your regular expression. Additionally, you can click on the + sign next to the text bar to view the available options and the meaning of the symbols.
3. Output: Here you can choose the type of output you want. You can configure this in 4 ways – replace, tokenize, parse, or match. *This section will be expanded more at the final bit of the blog.
4. Finally in the results pane, you will see the actual output of your configuration, once you've ran the workflow.
Output Methods
This section will explain the different output methods as well as show you the results of the outputs. The sample text within my column is "All APIs are websites but not all websites are APIs, there is no vice versa." and the RegEx I am using here is (\u) :meaning all uppercase alphanumeric characters.
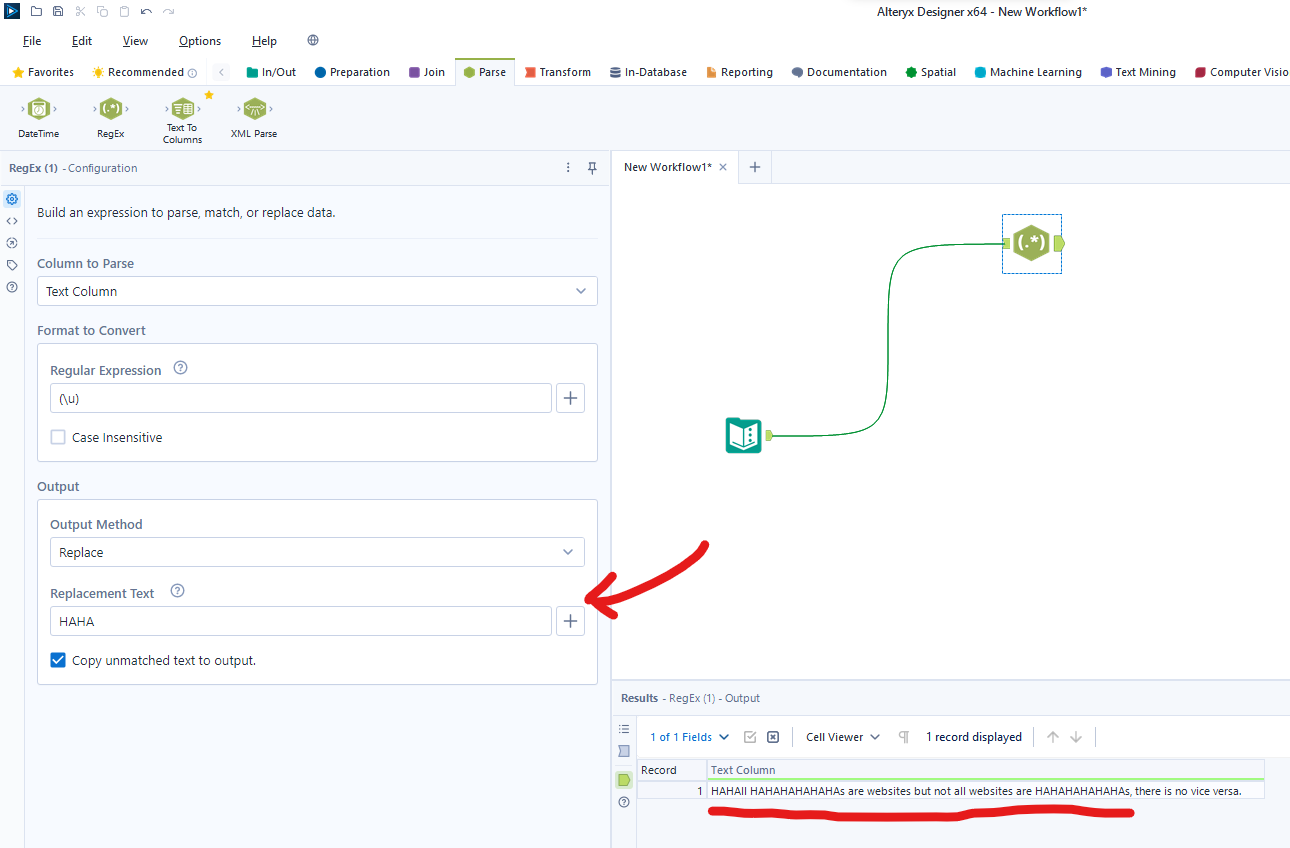
Replace: Find the RegEx pattern and replace the pattern with string(s) you input. The configuration pane will have an extra text column that will allow you to input what you want the replaced charcter(s) to be. In this case, I've prompted Alteryx to find all of the individual uppercase characters within my row and replace it with "HAHA".
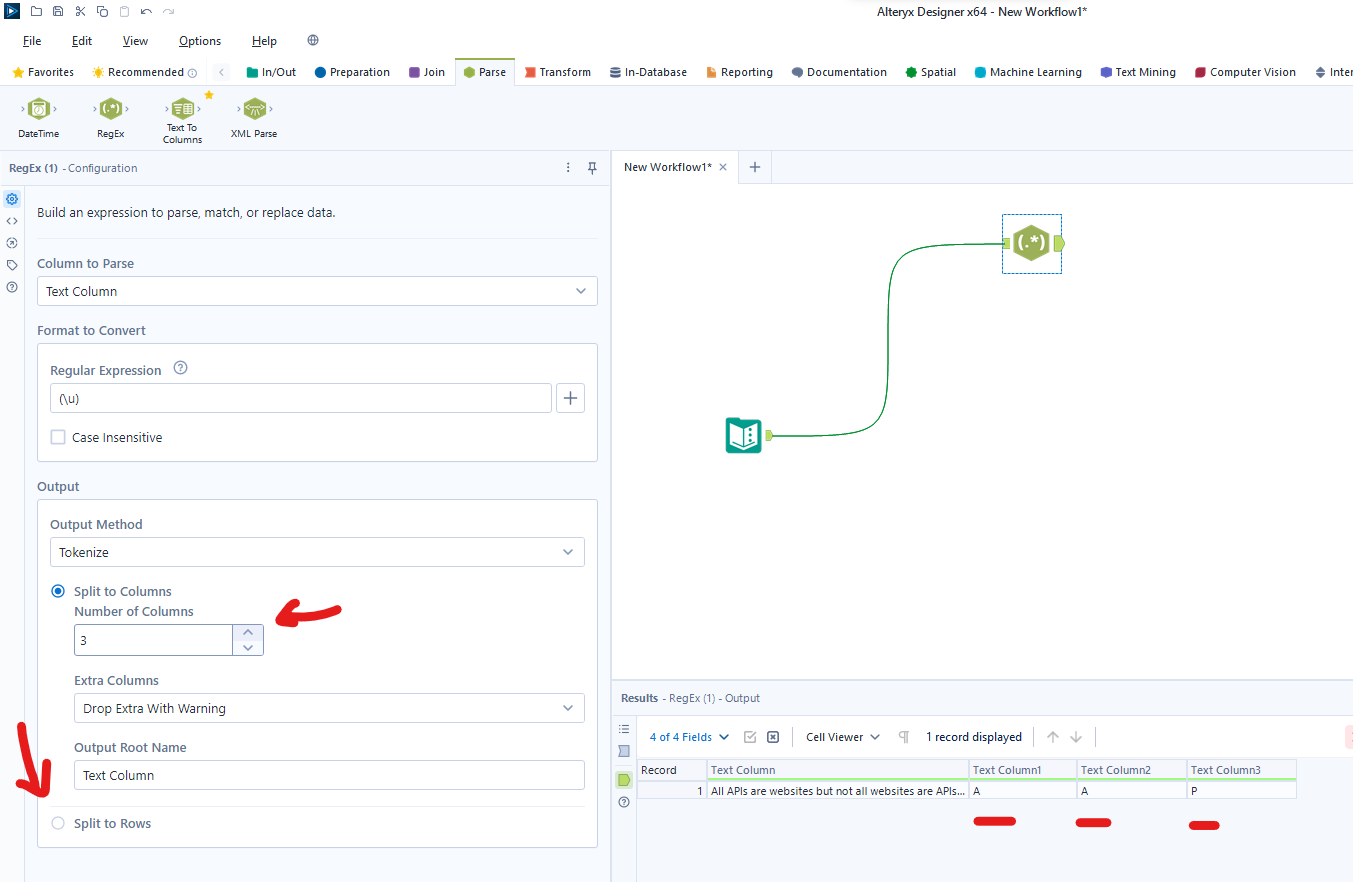
Tokenize: Find the specific RegEx pattern and specify how many columns you would want to parse that pattern into. In this case, I've chosen to output 3 columns of one uppercase alphanumeric character, which resulted in "A", "A", and "P". Important to note, is that the output section of the configuration pane will allow you to choose and output root name for you new columns, as well as the option to split into rows instead of columns.
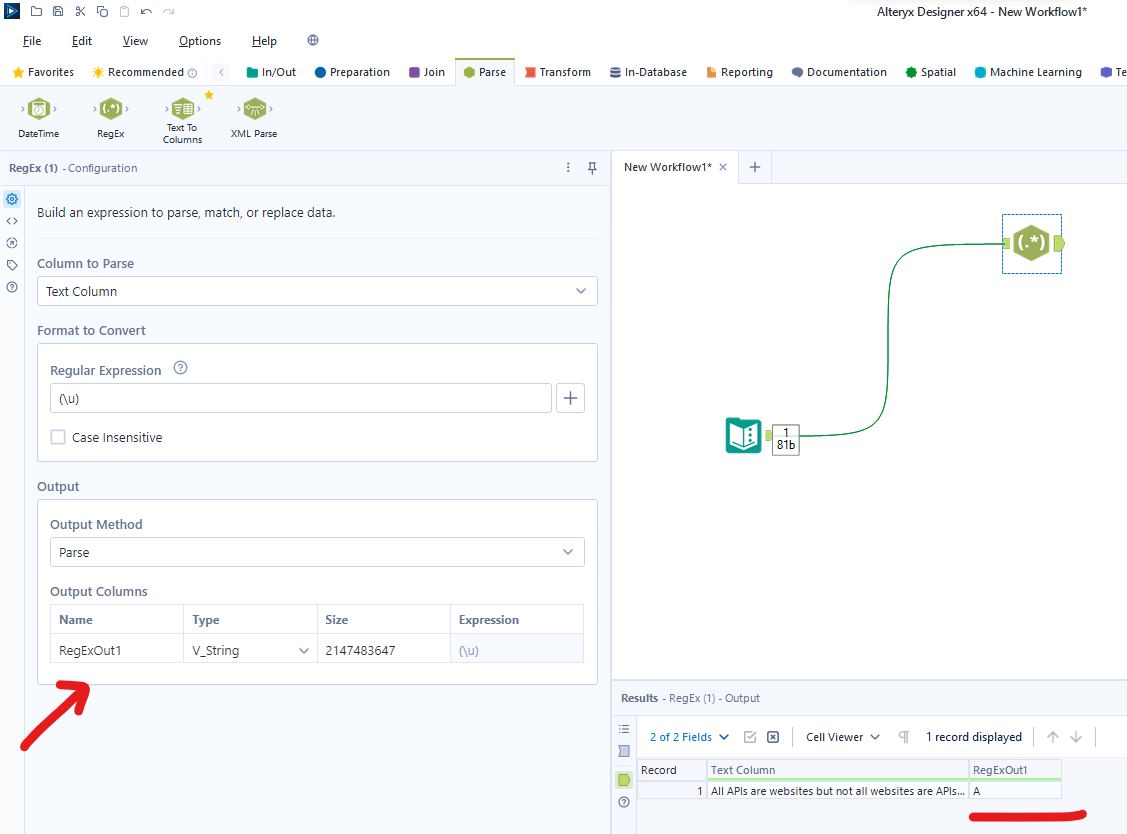
Parse: Find the RegEx pattern and split it into however many groups/columns, this will be determined by the number of characters you have encased within the ( ) symbols. In my case, I've only encased one pattern and the output for my parse was "A". The output pane will allow you to change both the name and the data type of the values in your new column.
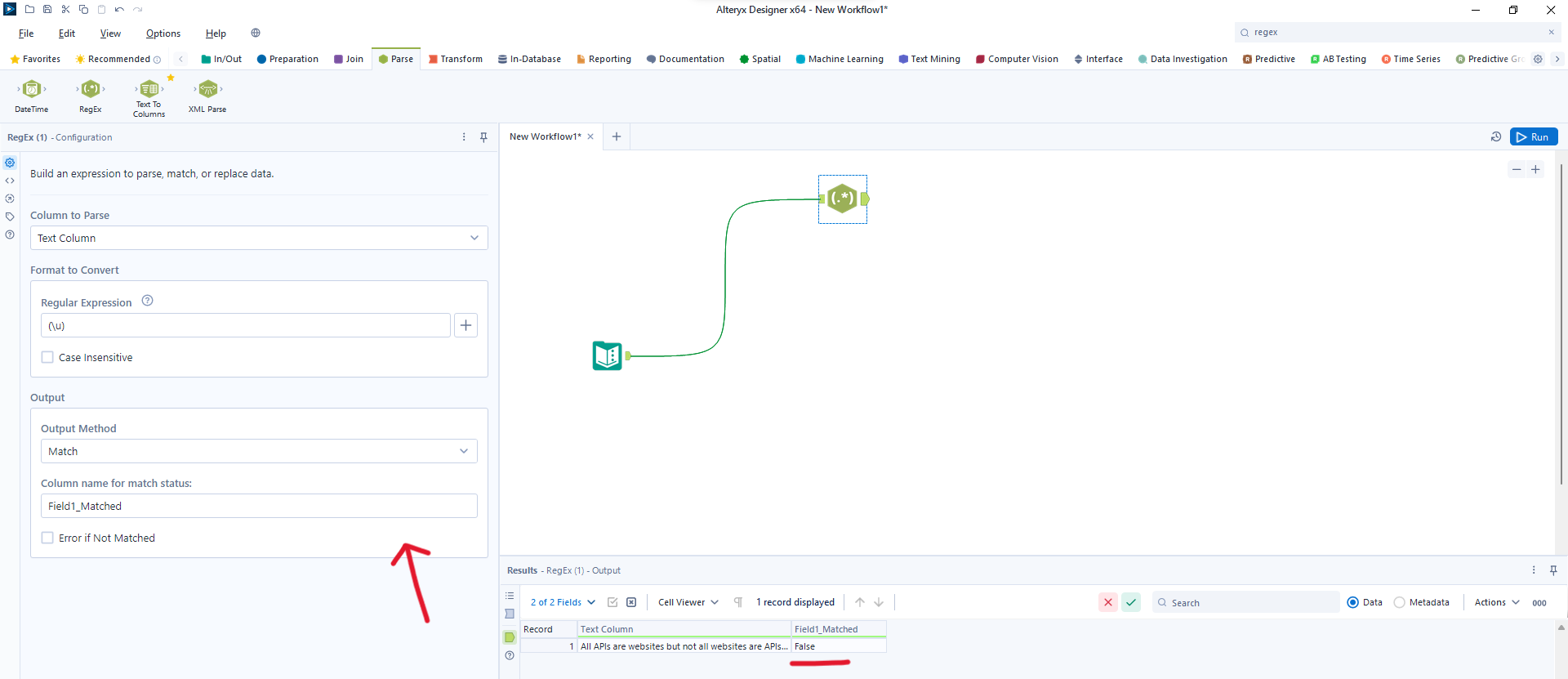
Match: Find the RegEx pattern and output a column that flags whether that row matches or not. In this case the flag output was false. Note that the Output pane will allow you to change the name of your newly created column.
Now go forth and do not fear the RegEx tool. I wish you a happy data manipulating.