


For this week's Friday project (week 9 of DS training), Coach Carl tasked us with using SQL to complete Preppin' Data challenges! So in this post, I will be documenting the steps I take to solve (or not solve) these challenges!
2021 W1
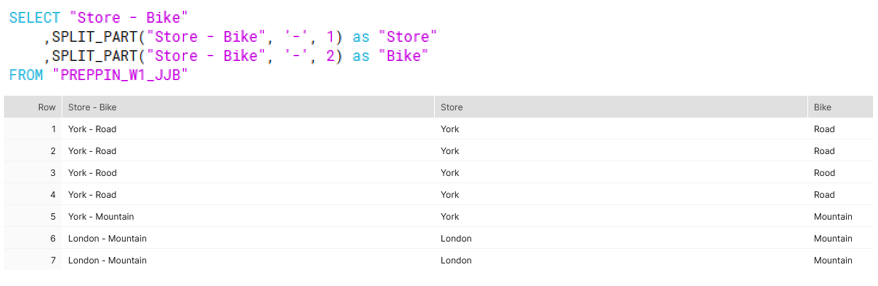
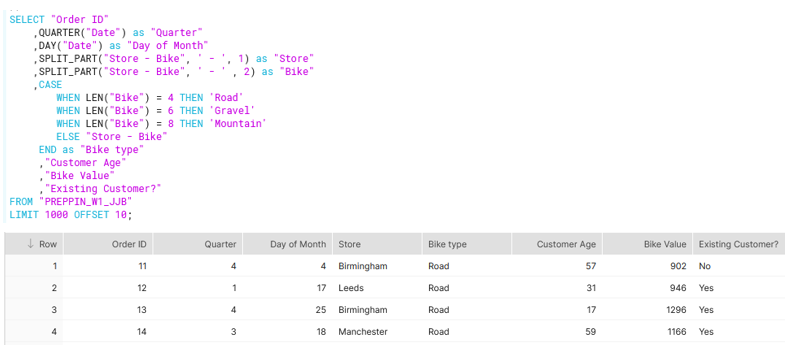
1st requirement: Split the 'Store-Bike' field into 'Store' and 'Bike'
I managed to do this using the SPLIT_PART(<string>, <delimiter>, <partNumber>)
- string: the text to be split
- delimiter: the delimiter to split by
- partNumber: which part of the split to return
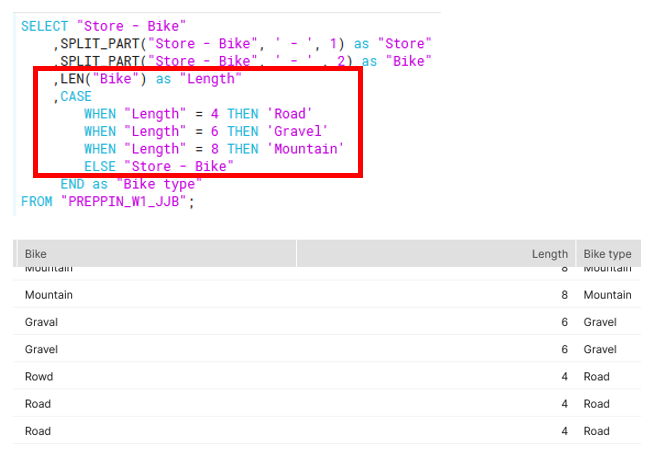
2nd requirement: Clean up the 'Bike' field to leave just three values in the 'Bike' field (Mountain, Gravel, Road)
I solved this using LEN() and CASE. Luckily the bike types, no matter how badly they were spelt, had the same length of characters.
- Mountain : 8 characters
- Gravel: 6 characters
- Road: 4 characters
From there, I used the CASE statement to create a new column with the correct spellings (figure c).
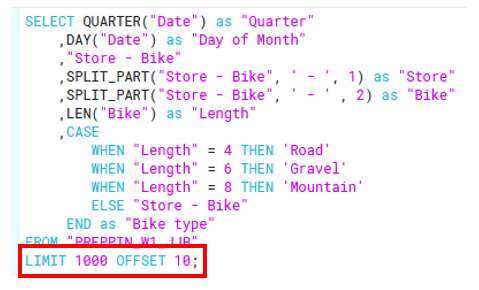
3rd requirement: Create two different cuts of the date field: 'quarter' and 'day of month'
I solved this using the QUARTER and DAY functions (figure d).

4th and last requirement: Remove the first 10 orders as they are test values
I solved this using LIMIT and OFFSET. LIMIT decides the max number of rows to return and OFFSET decides where to start outputting the rows, i.e. skip the first 10 rows (figure e).
Final SQL Query and output
2021 W2
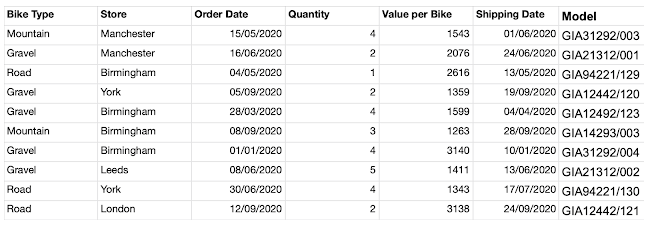
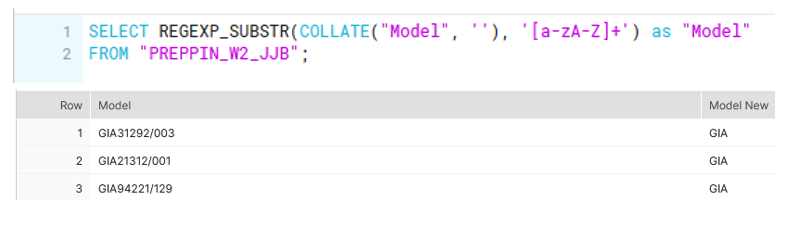
1st requirement: Clean up the Model field to leave only the letters to represent the Brand of the bike
This was solved using the COLLATE AND REGEXP_SUBSTR functions. When outputting the table from Tableau Prep Builder into Snowflake, there seems to be some collation happening particularly in the Model column, which prevented REGEXP_SUBSTR from working. By using COLLATE("Model", ''), Snowflake uses the default collation for this column – which compares strings based on their UTF-8 character representations.
After this, I used REGEXP_SUBSTR and the pattern '[a-zA-Z]+' to only return letters (figure g)
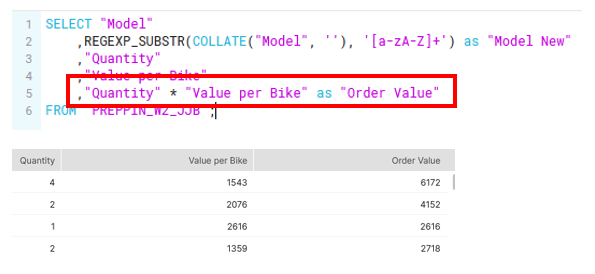
2nd requirement: Workout the Order Value using Value per Bike and Quantity.
This was done using the multiply operator (*) in SQL (figure h).
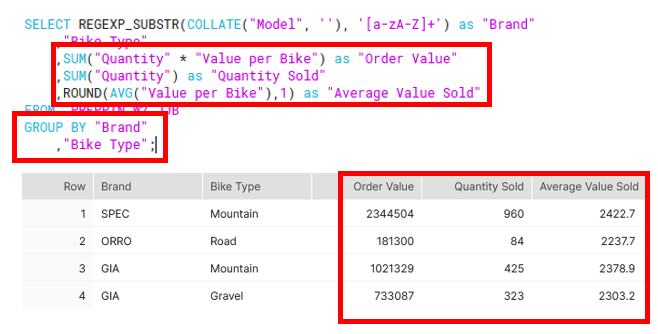
3rd requirement
Aggregate Value per Bike, Order Value and Quantity by Brand and Bike Type to form:
- Quantity sold
- Order Value
- Average Value Sold per Brand, Type
This was solved using aggregate functions SUM and AVG and then GROUP BY both Brand and Bike Type
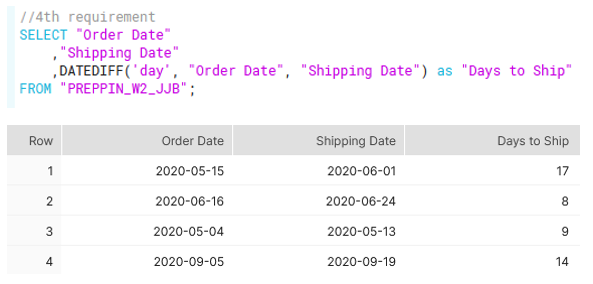
4th requirement: Calculate Days to ship by measuring the difference between when an order was placed and when it was shipped as 'Days to Ship'
This was solved using the DATEDIFF function on the Order Date and Shipping Date, as well as using 'day' as the date part (figure j).
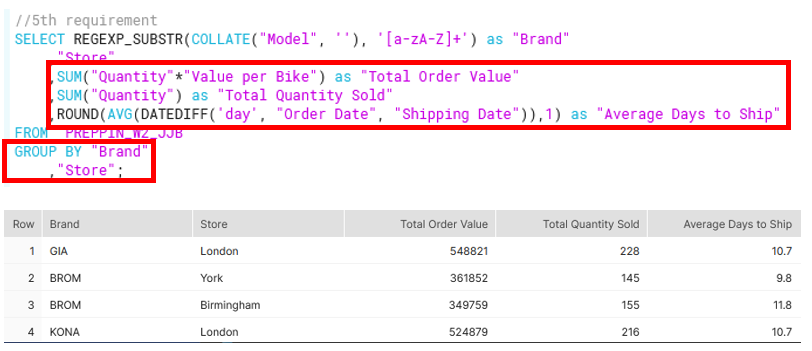
5th requirement: Aggregate Order Value, Quantity and Days to Ship by Brand and Store to form:
- Total Quantity Sold
- Total Order Value
- Average Days to Ship
Similar to the 3rd requirement, this was solved using aggregate functions SUM and AVG and then GROUP BY both Brand and Store
2021 W3
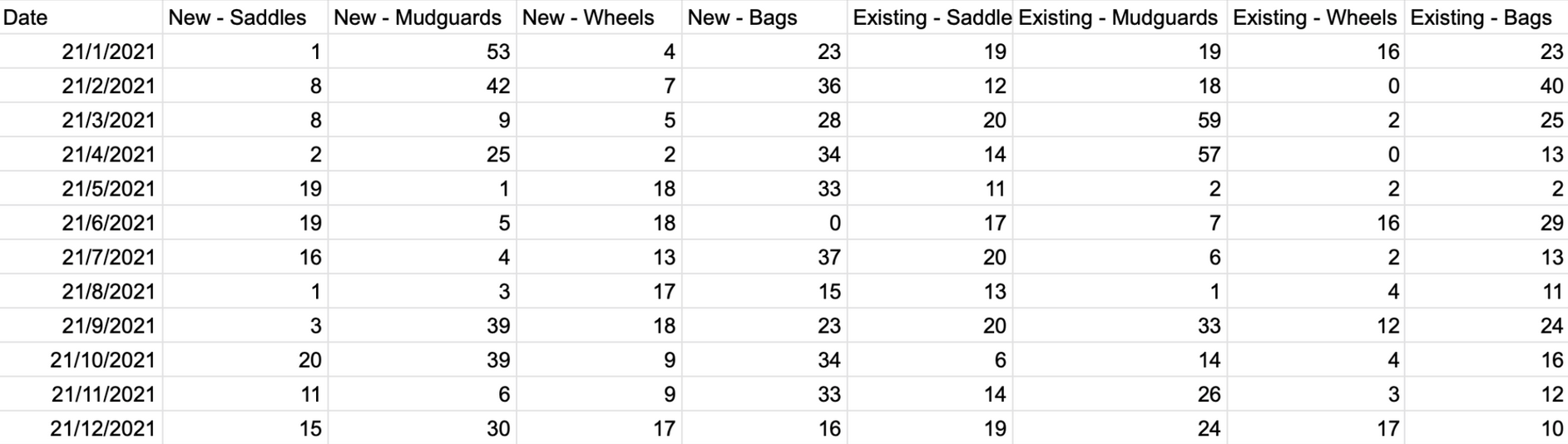
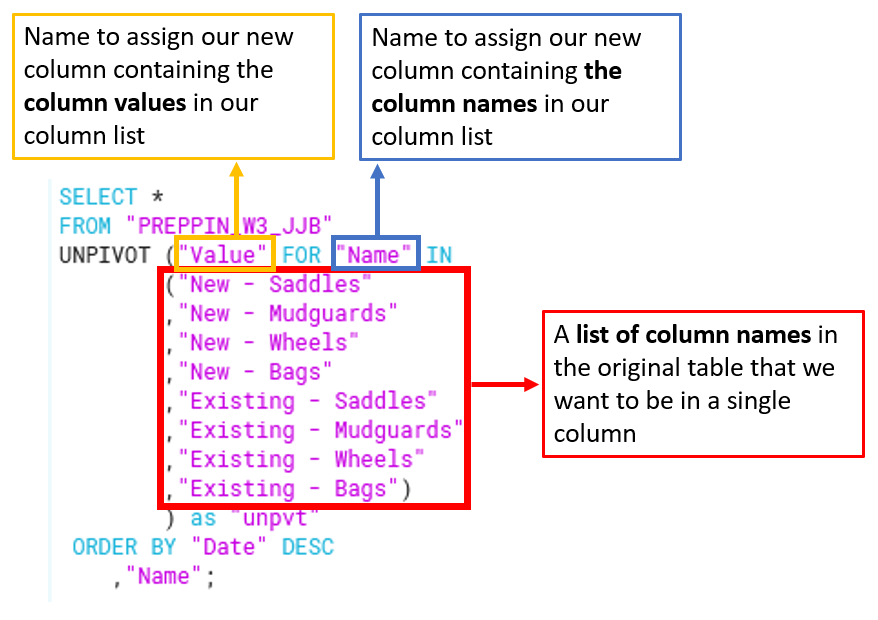
1st requirement: Pivot 'New' columns and 'Existing' columns
This was solved using the UNPIVOT function:
UNPIVOT (value_column FOR name_column IN (column_list)), where:
- value_column: the name assigned to our new column containing column values
- name_column: the name assigned to our new column containing column names
- column_list: a list of column names that we want to be unpivoted (or tranposed)

2nd requirement: Split the former column headers to form:
- Customer Type
- Product
Similar to the 1st requirement of 2021 W1, I used the SPLIT_PART function to achieve this (see below in figure o).

The rest of the requirements needed some renaming of column headers, removing unnecessary columns, turning the Date field into quarters (which was done using the QUARTER function). The final step was to aggregate the Products Sold by
- Product, Quarter
- Store, Customer Type, Product
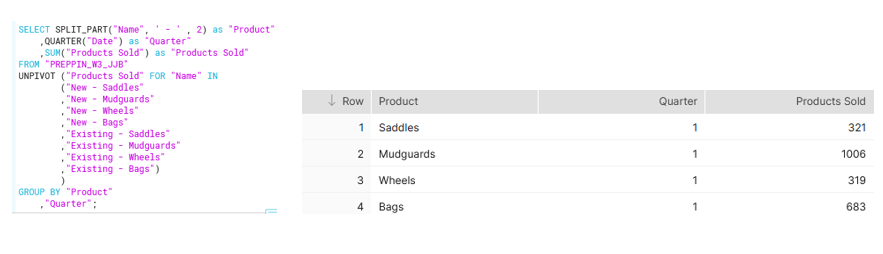
First output: Products sold by Product, Quarter
Second output: Products sold by Store, Customer Type, Product

2021 W3 (not cheating and doing the union in Snowflake)
Initially this challenge had 5 separate tables and I did the union of these in Tableau Prep Builder but I felt guilty after completing the challenge, so I came back to Snowflake and did the union over there.
We can union tables using the UNION function of SQL, the function combines the result of two or more SELECT statements.
- UNION: only returns distinct rows
- UNION ALL: will allow duplicate rows

Thumbnail from Aaron Burden on Unsplash.