The underlying logic of how iteration for iterative macro works in Alteryx was fuzzy to me at first. Yesterday we got the chance to revisit the topic in our Alteryx refresher training and did some more exercises. To solidify my understanding of how to create an iterative macro, I did an additional experiment with one of the exercises we did in class and discovered some important points that I had initially overlooked.
In this blog, I'll highlight some key points that I think are important in iterative macros.
Point 1: The iteration will be terminated under one of two conditions:
1. When all data has been processed (no more rows in the iterative output)
2. When the number of iterations reaches the maximum.
Point 2: The data flowing to the "iteration output" is reiterated via the "iteration input"
Every row in your data passes through the logic of your workflow, and all data associated with your "iterative" output is fed back into your workflow until there is no row left or the number of iterations has reached the maximum setting.
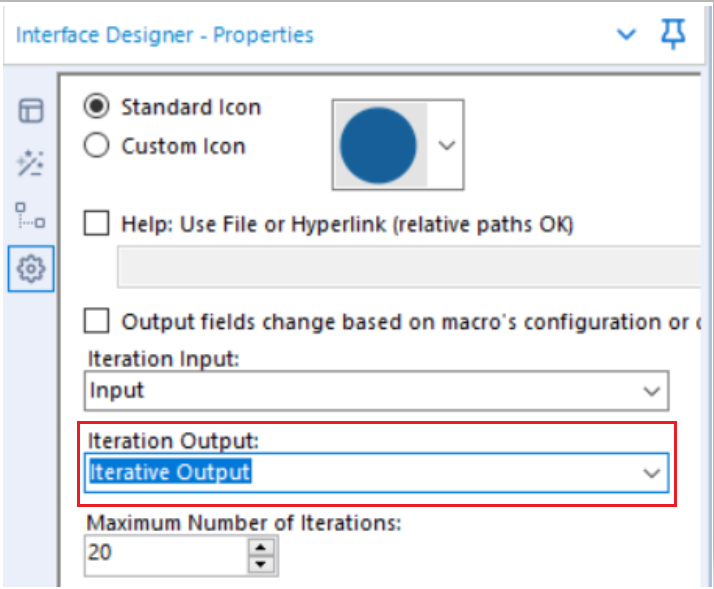
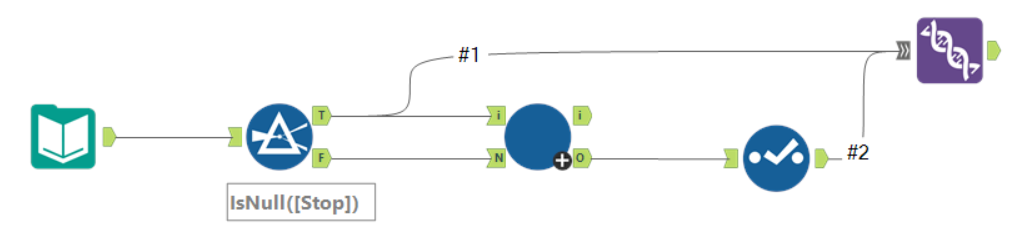
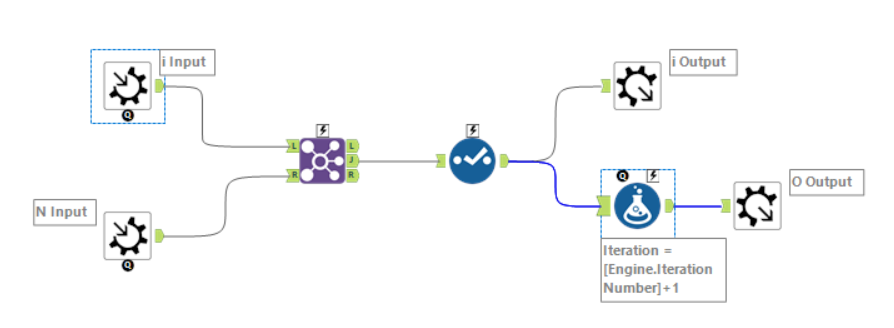
What do I meant by iterative output? It is the macro output in our workflow that we select for the iterative output in the interface designer configuration window. In this case I named the macro output as "Iterative Output". So when we connect a line from the output of our workflow to a macro output that is selected as the "iterative output" as shown in the picture above, these are the data that get recycled back to your iterative input. Hence the schema of the iterative output should match with the iterative input, which lead us to the second point below.
Point 3: The data structure (with same field names) of your iterative output and iterative input (labelled as "input" in the picture above) should be the same, else you will get the following error:

Point 4: We will need at least two macro outputs: one is for iteration; one is to see the outcome.
Technically we just need one macro input and one macro output to setup the macro workflow as shown in Figure 1. But the final outcome can only be seen with a "normal" macro output (labelled as o in the gif below)
Point 5: In the normal macro output, there is an implicit union action after each iteration. In each iteration, the data flowing through the "normal" macro output is merged with the results of the previous iteration.
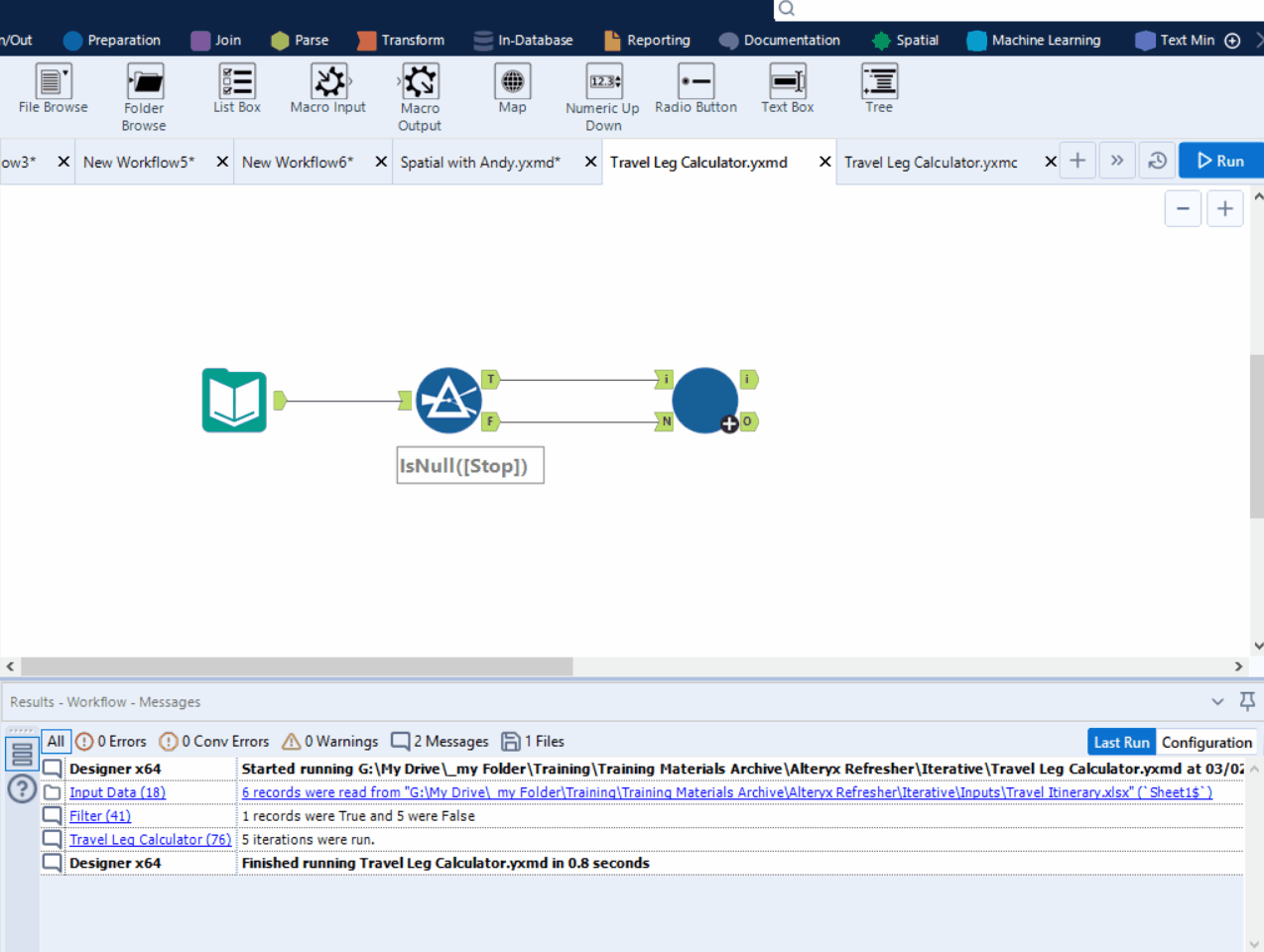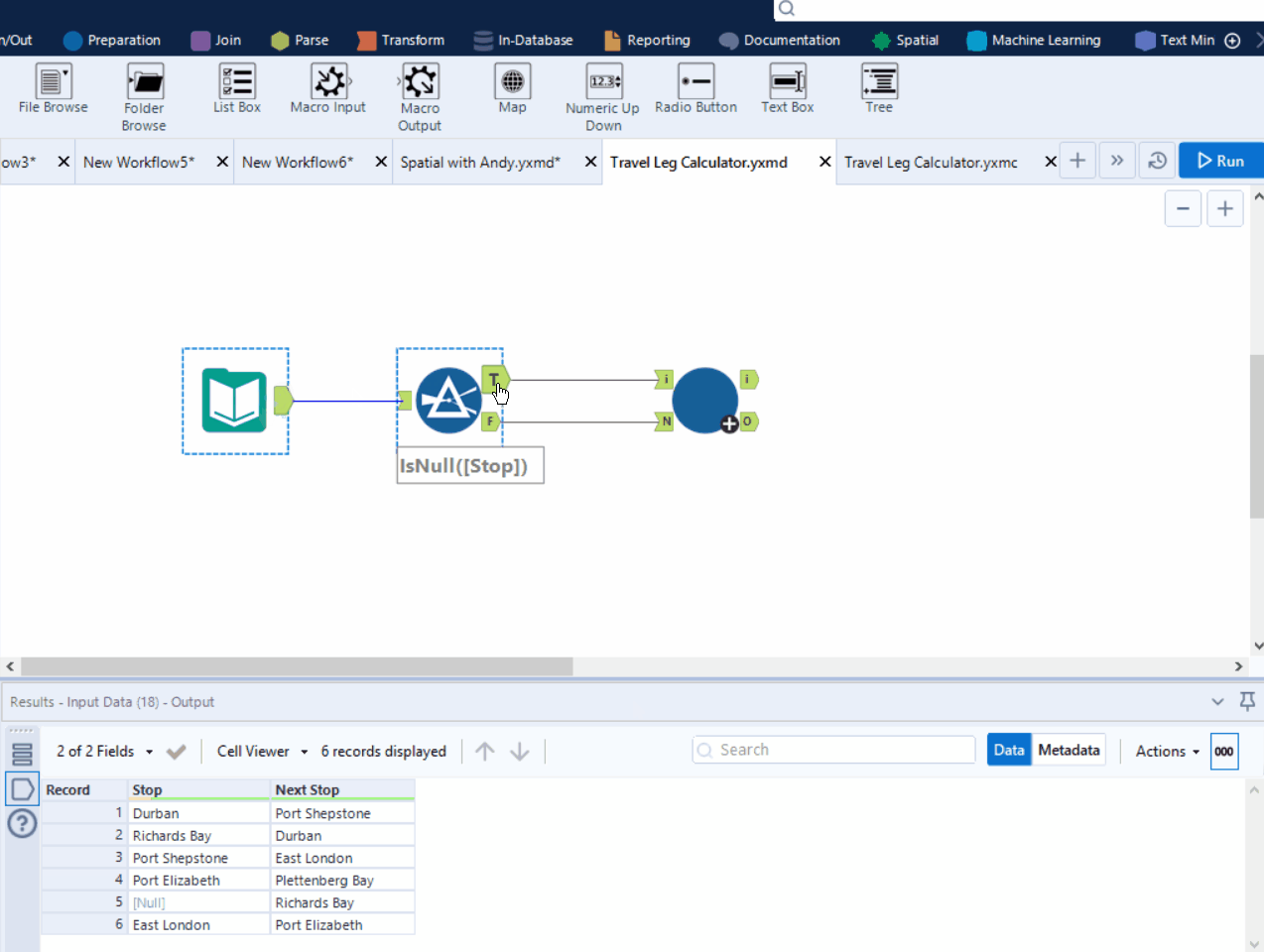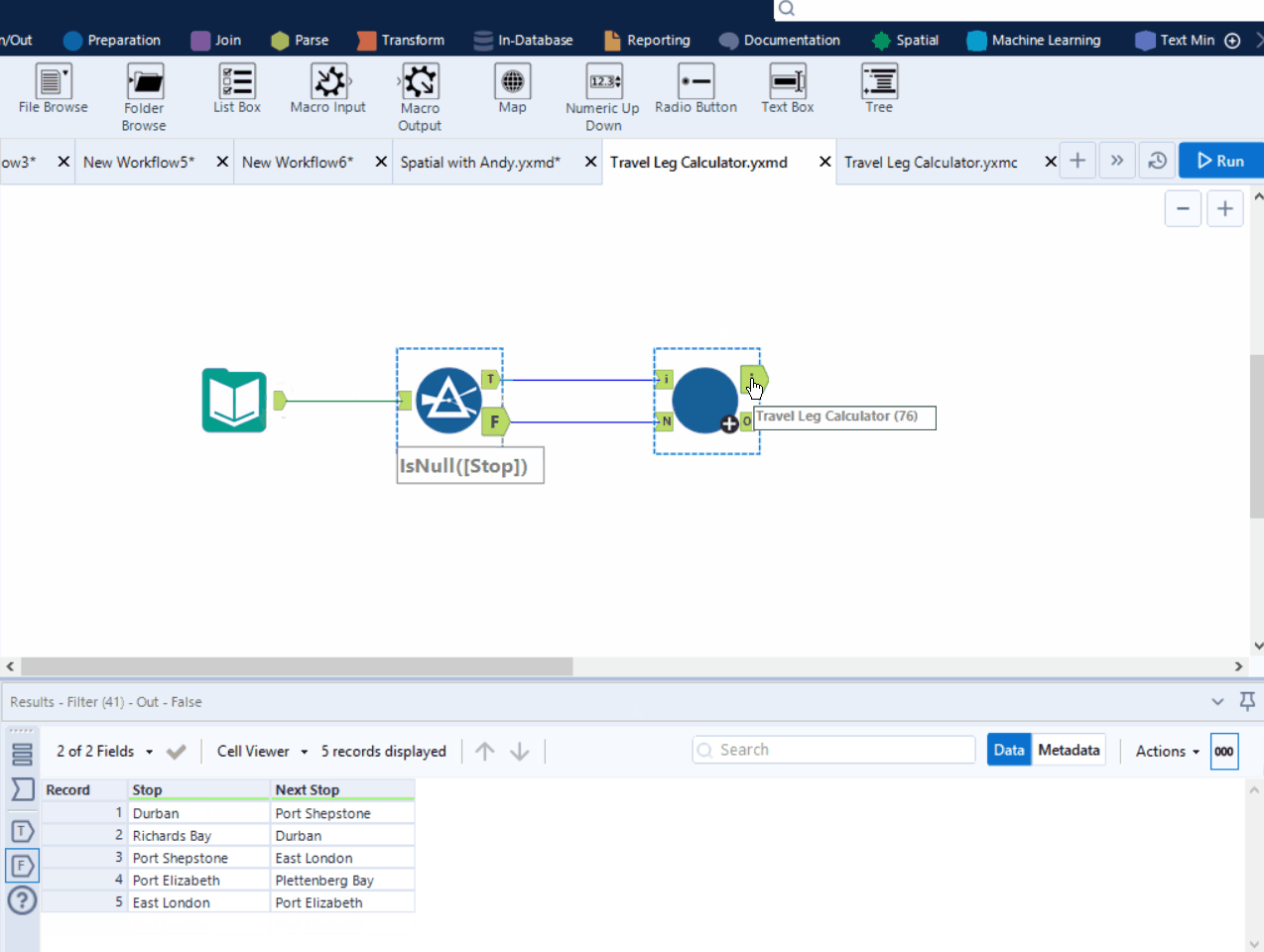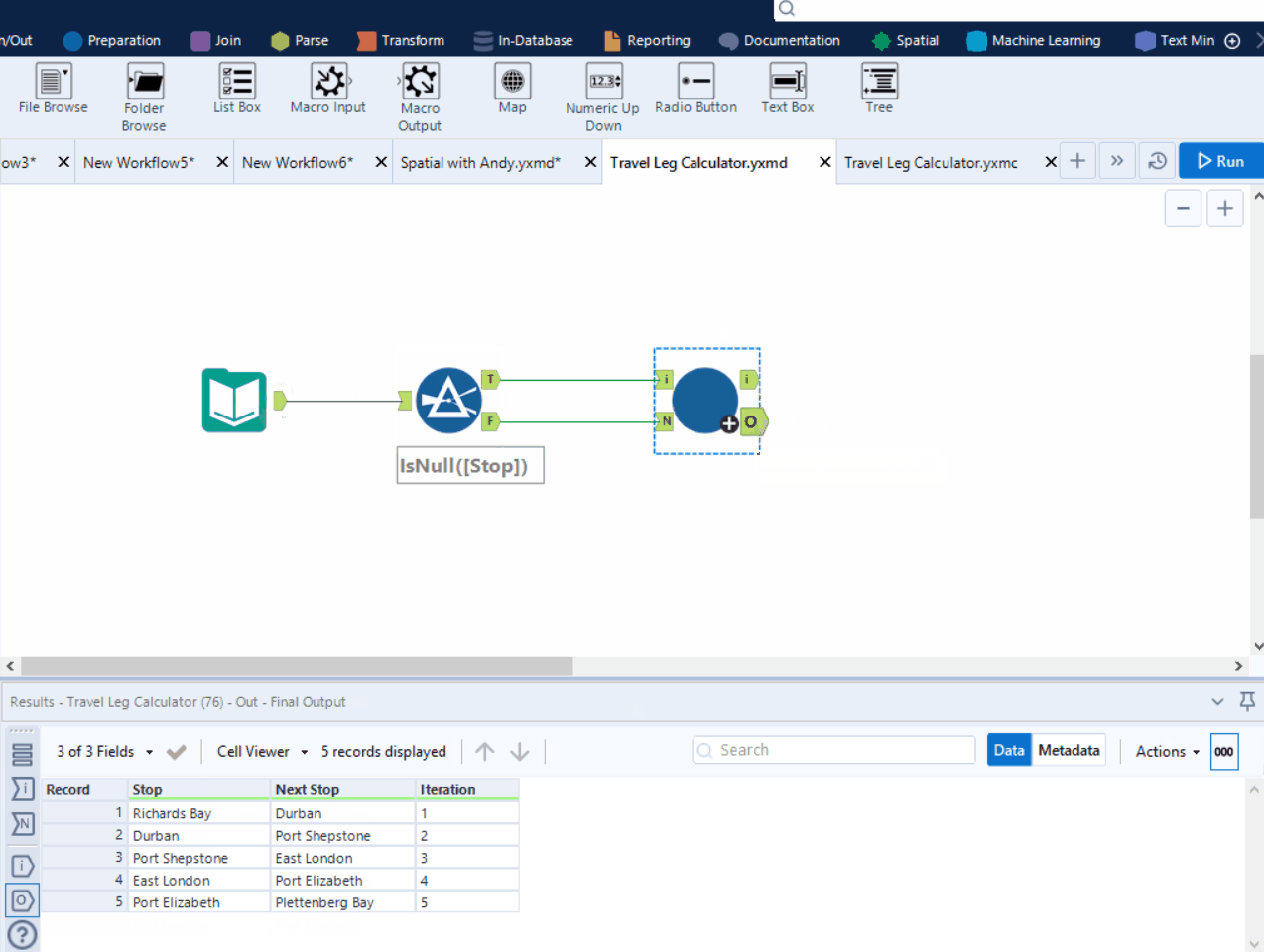
Example:
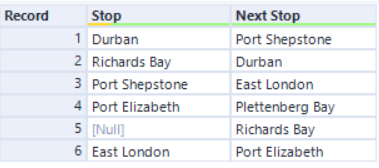
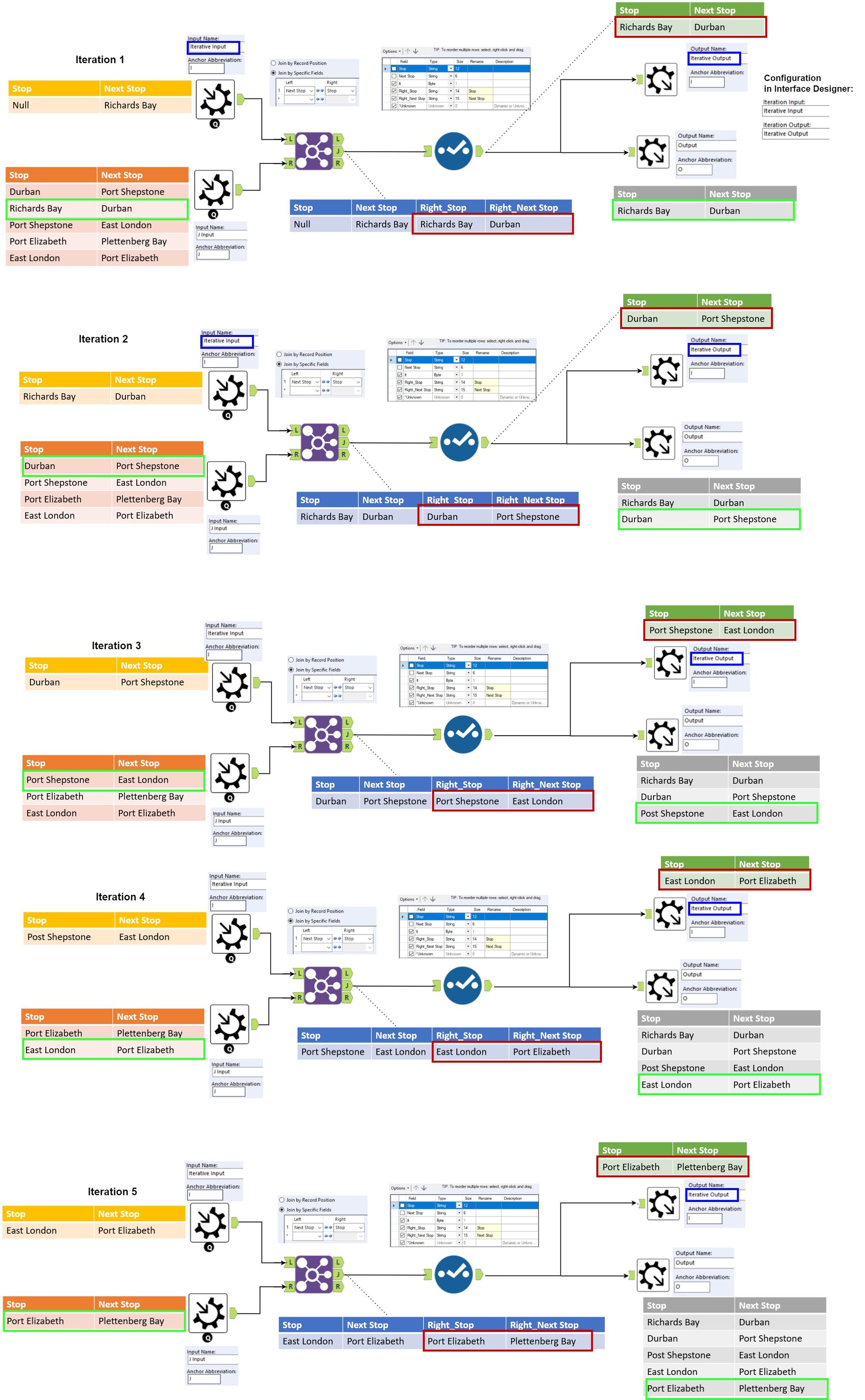
In the following example, each row represents a bus trip, and we want to sort the rows in order, where the next stop in the current row should match the stop in the next row.
The dataset:
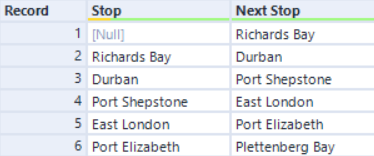
Expected Outcome:
If we solve it by ourselves, we will apply the following steps:
1. Identify the first trip/the departure (the one where stop = null), set the rest of the rows aside as search stack
2. Loop through the search stack and search for a row where the stop value matches the next stop value in the previous row
3. When a match is found, it is joined to the previously found rows, remove the row from the search stack
4. Repeat Step 2 and 3 until no more rows left
The Solution using iterative macro:
Essentially, we perform the matching between stop and next stop using the join tool. Then we need a select tool to deselect unwanted columns and rename the matching results so that we can
1. recycle the result back so that it can be used to look for next row
2. to be union-ed with the previous result
This is a crucial step that we use to ensure that the data structure and schema match the iterative input. If we don't rename the field as the iterative input even if we have the same schema, it won't work and we will get the following error. The schema and field name of the iterative output should match 100% with the schema and field name of the iterative input.

This is how each iteration looks like in this example:
NOTE: When the data flow through the iterative output, it will be removed from the AKA the search stack (in orange) in next iteration
The complete workflow:
We just need to union the final output from the iterative macro to the first row (the departure) to get the expected output.