


This week we have learned how to webscrape a website using Excel / Sheets and then moved on to doing it again in Alteryx. I will show you how to do both.
To start with, we were shown how to pull tables from a website in Sheets. To do that, we need to take the URL that you're trying to webscrape and import it into sheets. We need to use this function '=IMPORTHTML("URL","table",1)' where the number is the table you're trying to pull from the website. Most of the time, it ends up being trial and error with pulling a table as trying to figure out which number is the one you want is just counting or checking. Instead of pulling a table, we can also pull a list from a website. For that, we just need to replace the word 'table' with 'list'.
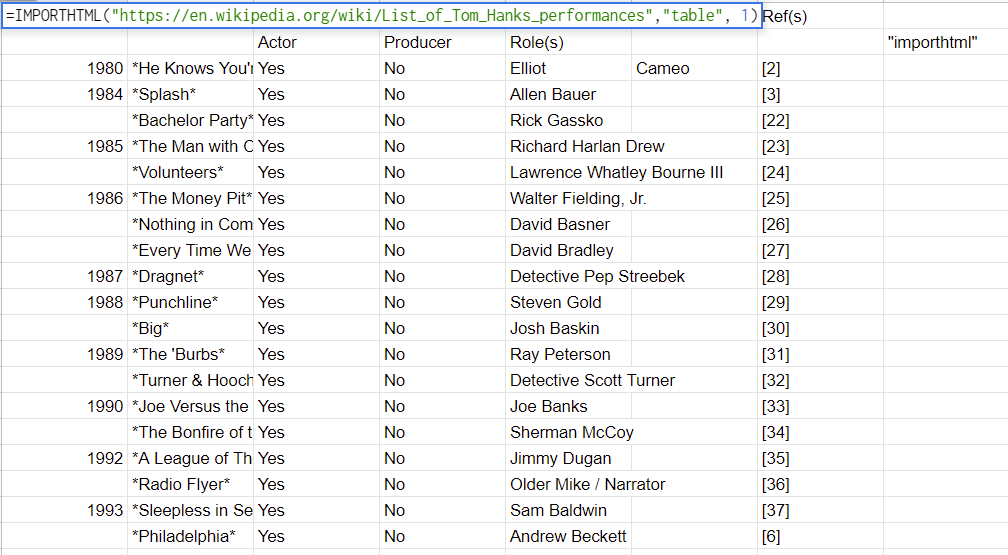
As an example, we pulled a table of Tom Hanks' performances. This is how the table ended up looking like:
Now moving on to Alteryx, we were webscrapping a website called Books to Scrape. At first, we made a list of the things we wanted to pull from the website. We picked the Book Title, Price, the UPC, an image of the book, the number of books left in stock and the star rating.
The workflow looked like this:
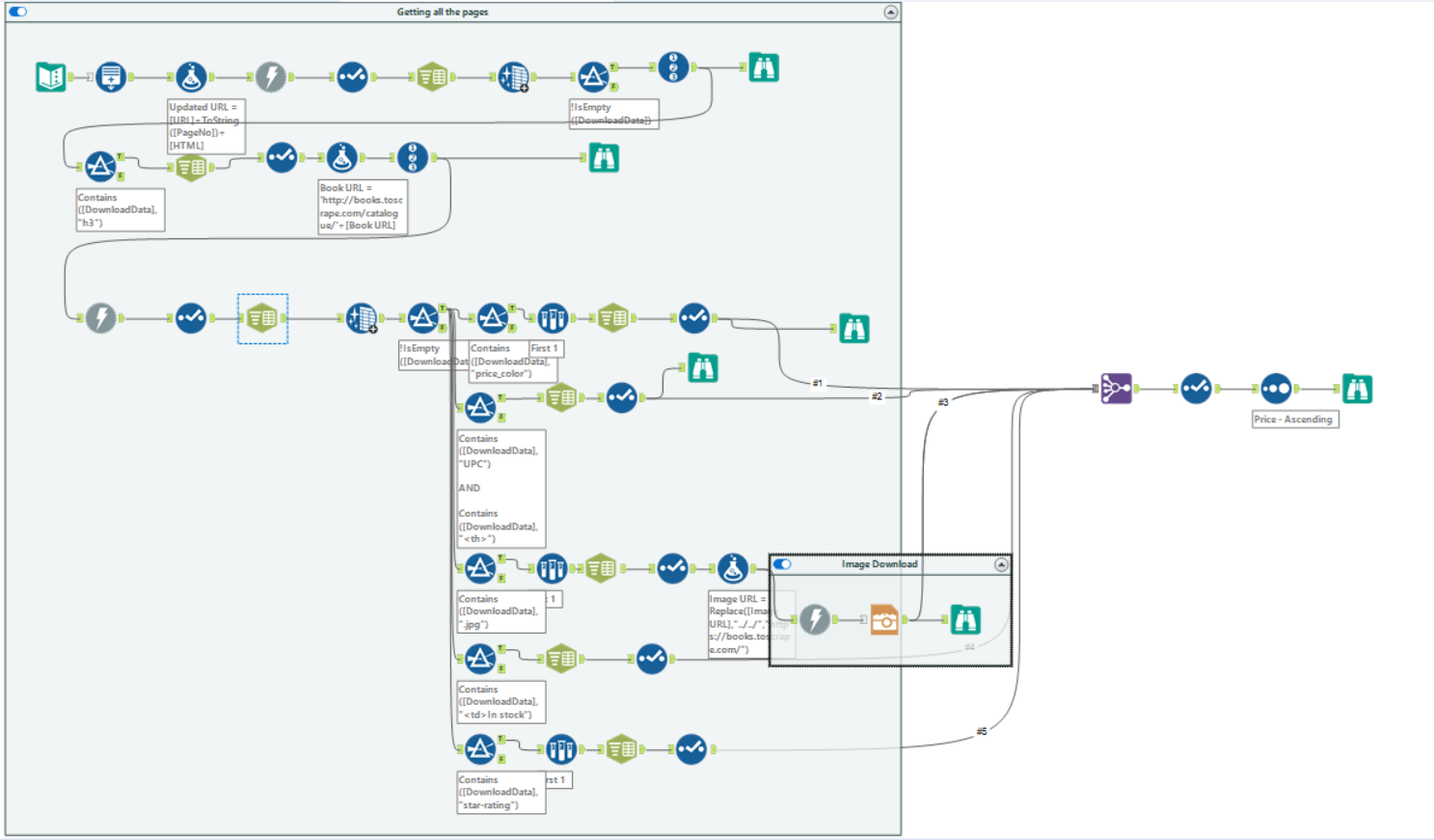
This can be simplified with Regex but in this example, we have used Text to Columns tool and other preparation tools to see how each step is done.
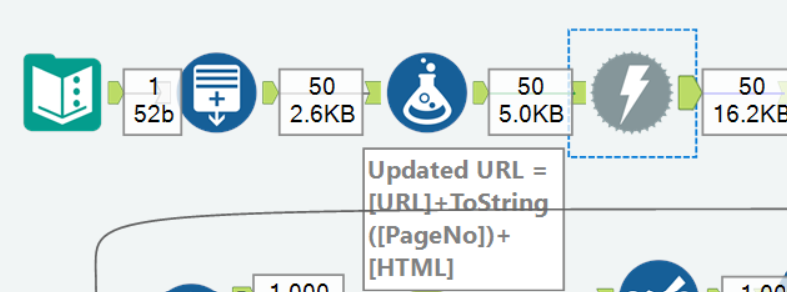
So at first, we have generated the same URL with different page numbers to make sure we get all of the books on the website, which in this case, is 1000 and then we downloaded the data using the download tool. This is how the workflow and the results looked like so far:

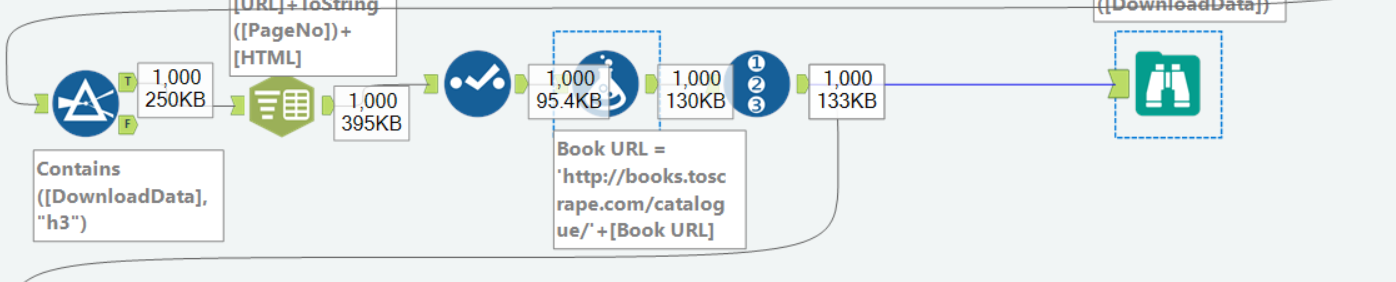
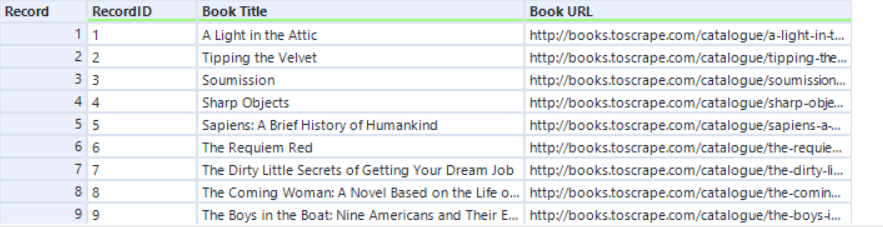
Then after that, we picked only the fields that we needed, cleaned them up and filtered them to get what we want - which in this case was the Book Title and the corresponding URL for each of the books. The workflow and the results looked like this:
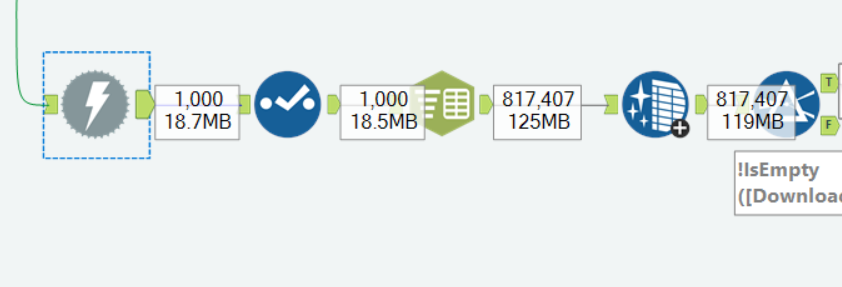
Then we redownloaded the data, this time from each of the book URLs and did the same thing - cleaned it up and filtered out empty records. This is how this looked like:
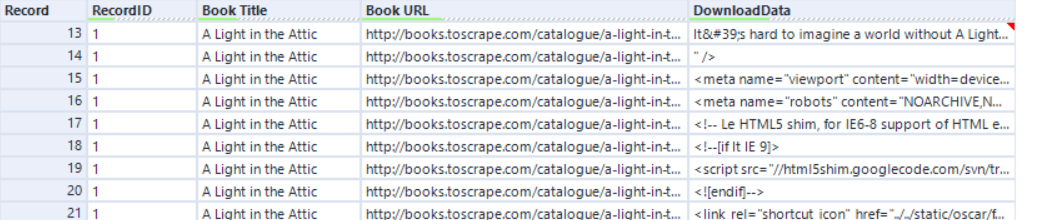
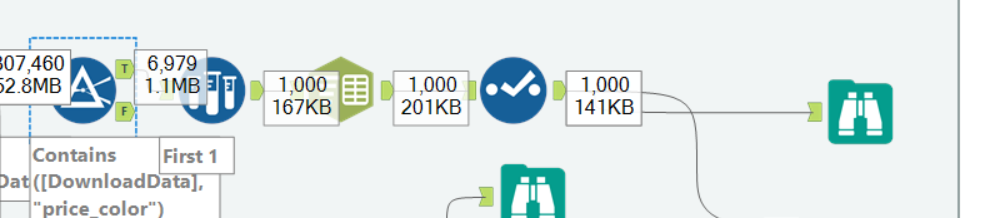
After this, we can do different things to the same data, which in our case was getting the image, the price, the star rating and the stock information. It is essentially the same process for each of those steps, it just depends what you would like to get out of it. As an example, this is how it looks like when you try to get out price out of it:

However, like I have mentioned before, you can definitely make this process faster by using Regex.
Hope this was informative about how to webscrape something using basic steps.