


Despite once collecting scientific data for a living, I had no idea where that data could go, or how it could be used in a wider context. I didn't expect to be studying modern data architecture on my second day, but it gave so much context to both my previous job and what we'll be learning in the next 4 months. We were asked to take a basic Data Pipeline: ...
- Raw data collection
- Ingestion into a central storage system
- Data preparation
- Data visualization
... and to apply it to any field or industry. I chose to look at clinical trials.
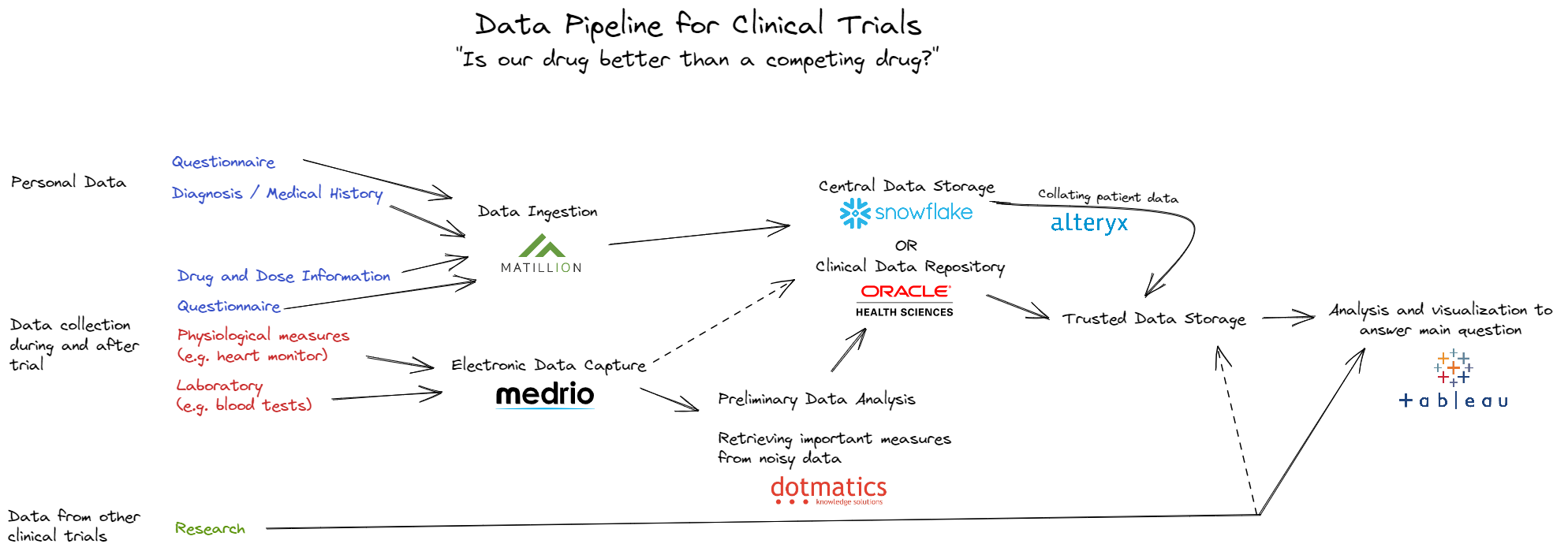
There are some important factors to consider in clinical trial data management. First off, lots of the data collected in a clinical trial needs extensive analysis before you get the measures you want. Consider a trial for a drug for treating heart conditions. The heart function of patients may be monitored using an electrocardiogram, but storing a full ECG in a patients final dataset is bulky and hard to interpret. Instead, it is analyzed using specialist software to extract useful measures, maybe heart rate. These useful measures are included in the final dataset.

This is true for a lot of data collected in a clinical trial, and is a big reason for another important part of clinical trial data management - automated data systems. Software has been developed to automate the data collection, preliminary analysis, ingestion and storage pipeline for multiple medical and laboratory devices. Multiple companies, including Oracle, have tried their hands at creating all-in-one clinical trial data management systems - from data ingestion to final analysis.
Although Alteryx and Tableau are not common in scientific data management and analysis, the overall data pipeline shares the same structure as that of standard data management. Giving this some thought on day 2 brought new context to a familiar topic for me, and kept me excited for what's to come.