


Arrays and structs are essential for understanding data organization in BigQuery. This blog will clarify what each of these structures is, how to identify them in BigQuery, and when to use them in table structures.
Arrays
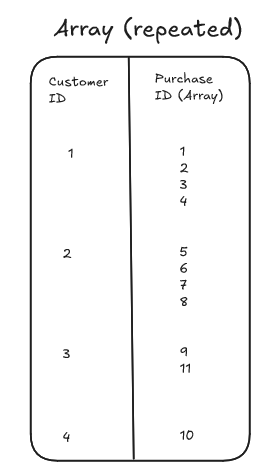
Arrays appear in other languages and softwares than BigQuery and fortunately they refer to the same thing in BigQuery that they refer to in other languages - a list of values of the same datatype.
E.G. Outfit Colors: [green, tan, brown]You should be able to identify an array in a table schema by looking at the mode; if it is REPEATED then it is an array. The REPEATED refers to multiple entries of the same type which circles back to the original definition of an array.
Structs
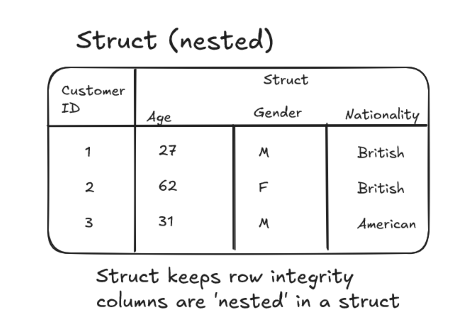
Struct is a data type that contains key:value pairs. Each pair might be referred to as an attribute.
E.g. Outfit Colors: {
"top":"green",
"bottoms":"tan",
"shoes":"brown"
}You can identify a struct in a tables schema as the data type will be RECORD.
Working with both arrays and structs.
With an understanding of arrays and structs, we can explore how they are used separately or together. An array of structs allows us to store a list of structured records within a single field, such as a list of people with their details inside a record for a city.
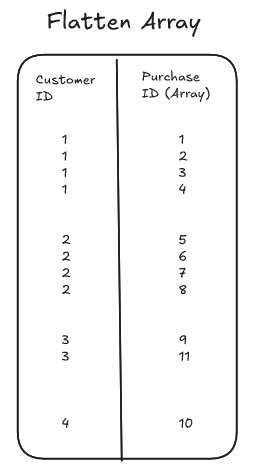
We can think of an array of structs as a list of records nested within a main record, representing a single row in the table. It is worth noting this as when flattening an array or array of structs you should be aware that this is expanding the row count of a table.
Conversely, unpacking a struct should not alter the grain of the table as it is simply attributes (think additional columns) collapsed into a single structure for storage in BigQuery.
A particular attribute within a struct can be queried with an additional dot. Think table.column.attribute.
A common approach to using both arrays and structs in conjunction is to use an array of structs. This structure can be explained with some imagery:
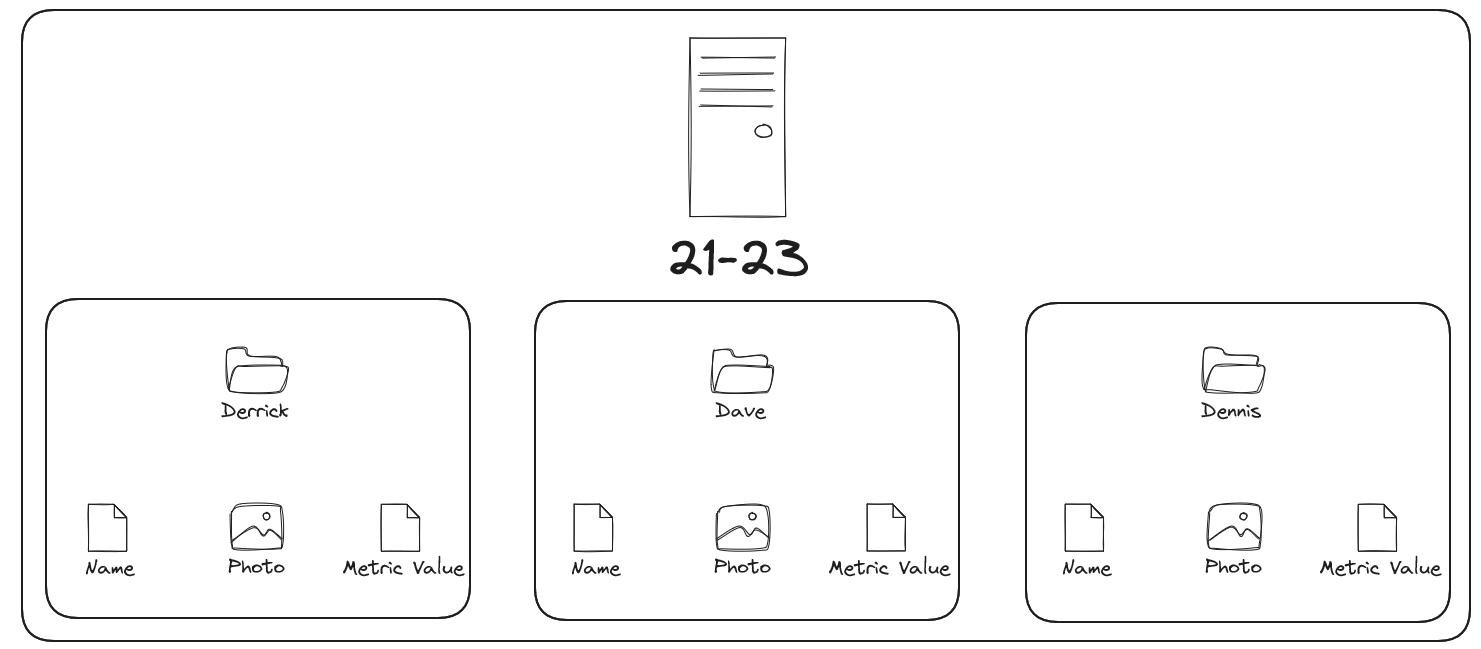
Imagine each row in a table as a filing cabinet representing a group, like an age category. Inside, we have folders (an array) for each person in that group, with each folder containing pages (a struct) for details about that person. Flattening this array would display each folder individually, and opening each folder gives us specific information for each individual..
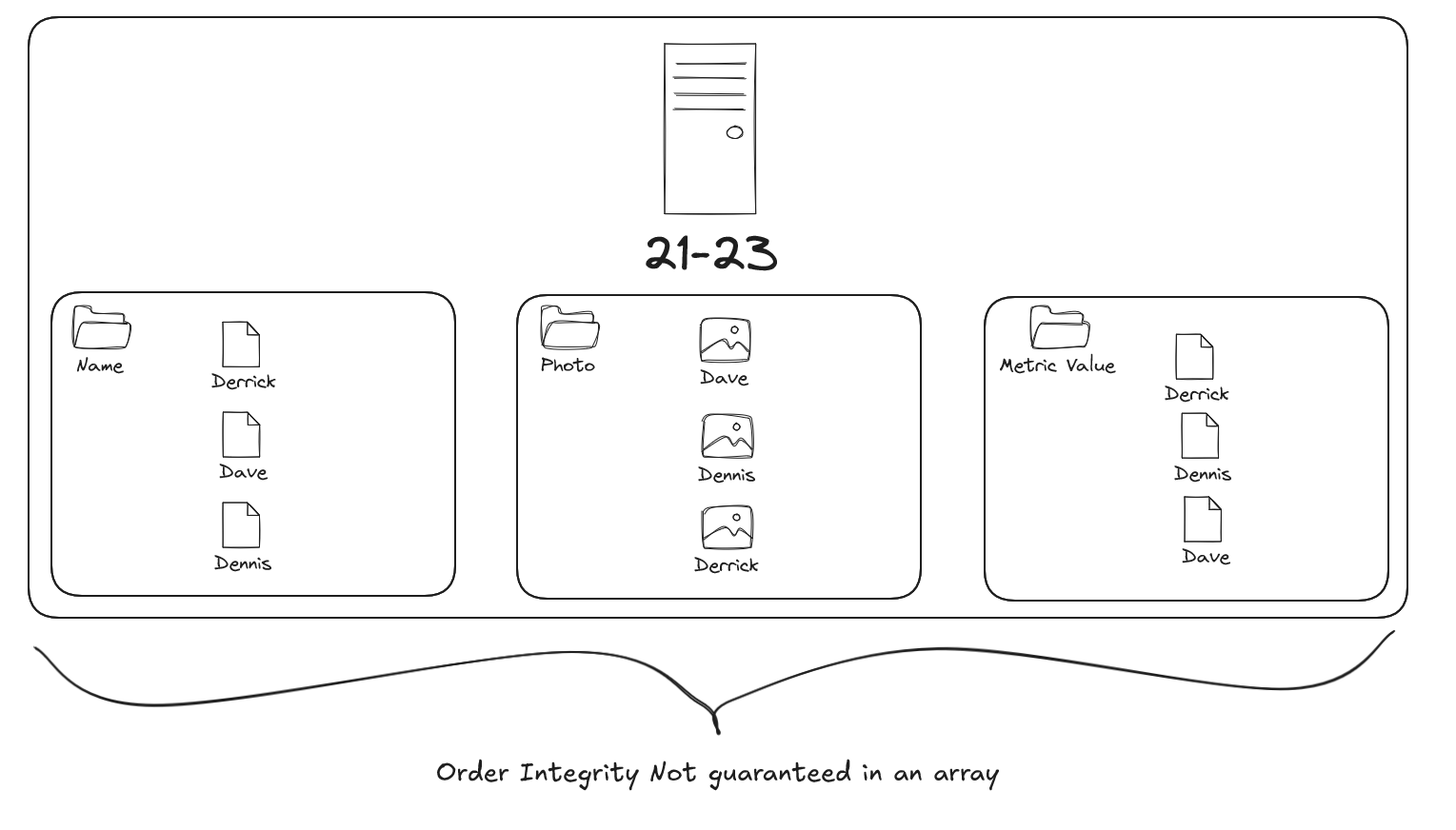
In a struct of arrays, each folder (struct) contains only one type of information—like a folder of names, another for photos, and another for business metrics. Since arrays don’t guarantee order alignment, matching names with photos becomes difficult, making it challenging to reconstruct complete records for each individual.
In Scenario 1 (array of structs), we can easily locate an individual’s complete record by flattening the array and unnesting the struct. In Scenario 2 (struct of arrays), finding complete information requires piecing together pages from separate folders (arrays), losing context and creating more work.