We recently had a session on how to web-scrape in Alteryx and this blog is intended to outline the process of how to do it. Firstly, it is worth pointing out that web-scraping comes with two caveats; when web-scraping material we should make sure that we have the appropriate permission/right to do so and second that there is not an available API offering to access the information. The reason for going through an API rather than scraping a website is that a website is subject to change or development that might render your scraping pipeline redundant.
For the blog I am going to document my scraping of the 2019 UK General Election results from the BBC. This was a nested scrape in the sense that I had to scrape the links to the specific constituency pages before then scraping the election results info for each constituency.
In the section below I outline the scraping process for the second stage where I am actually grabbing the data but the same principles applied to the first stage of scraping except that the payload I was specifically after was links to the consituency specific pages that would populate my input for a second download tool that downloads the information for each page.
Step 1 is to use a Download Tool to grab the HTML of the page you are looking to scrape, I use a text input to add the URL, later on when we have multiple pages to scrape each URL can be a row in that text input and each will have its HTML downloaded.
Now the HTML needs to be analyzed and we need to identify the information we want and how we might extract it. A browse tool can serve this purpose but it is very hard to read - thus copying the code into Visual Studio Code can help so that we can control-F find specific terms and see the code structured and color coded, something like this:
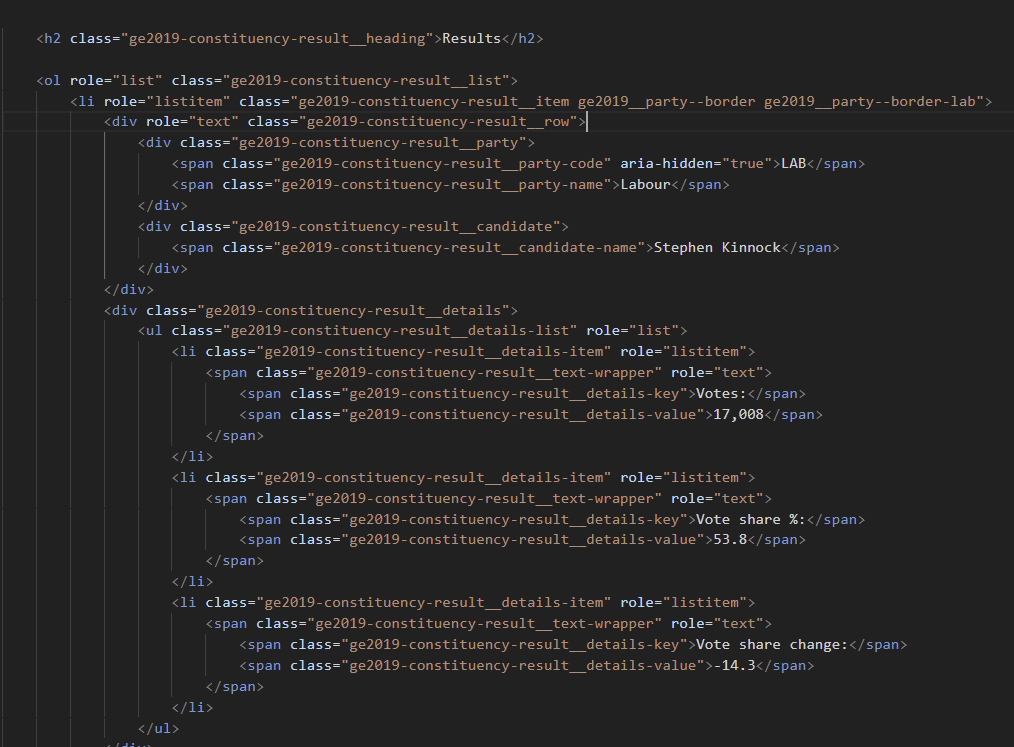
For the example in the photo we might want everything within <span ... </span>. Because the span payload is nested within different layers we might want to split them up into rows at a higher level first (in this case I went from div class = to /ul> i.e the chunk we see above as it was repeated for each candidate in a constituency). We use regex tokenize and split to to rows we can tell alteryx to create a seperate row for everything that falls within the tags. We want to ensure that our regex is not greedy and doesnt capture everything between the first <span and last </span> so we settle on an expression like this:
<span.*? </span>
The .* means 0 or more of any character and the ? instructs regex to be non-greedy.
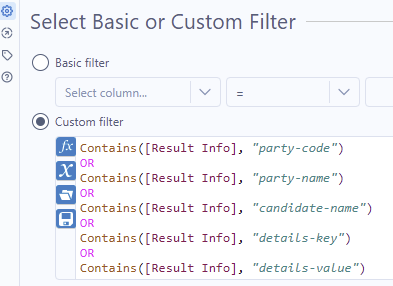
Often times these tokenization strategies return too many rows, there might be cases where the span payload does not include any useful information. Regex match filter tools are useful here for clearing out the rows without useful information - sometimes a simple contains filter will do the trick:
Once we have these as individual rows we can use a regex parse to capture the specific information we want - in the above example we might want to capture everything that follows: "> as that includes either the measure name or the measure value.
(\S.*?)<
\S means as long as it is not just a blank space, capture everything between an > and <.
At this stage we would have a long and thin table with a number of rows for each candidate so we can use a recordID so we can pivot the data to have a row for each candidate in the general election. Effectively every 8 rows were a single candidate so I used multi-row formula to assign an increasing record ID everytime 8 rows occur. Then it was a case of cross-tabing for the required result.