


What is Unit Testing
Unit testing is rooted in software development and is aimed at maintaining quality code as a project develops and grows over time. As code grows over time, the idea is to isolate individual code modules and test that they perform as expected and at an acceptably performant level.
There are a few principles behind the concept of unit testing:
- Isolation
- Tests focus on a single unit of code like a function or method.
- External dependencies should be mocked or stubbed to ensure isolation. Practically this means fixing the incoming information the code requires so that the test is conducted on the code itself rather than other bits of code.
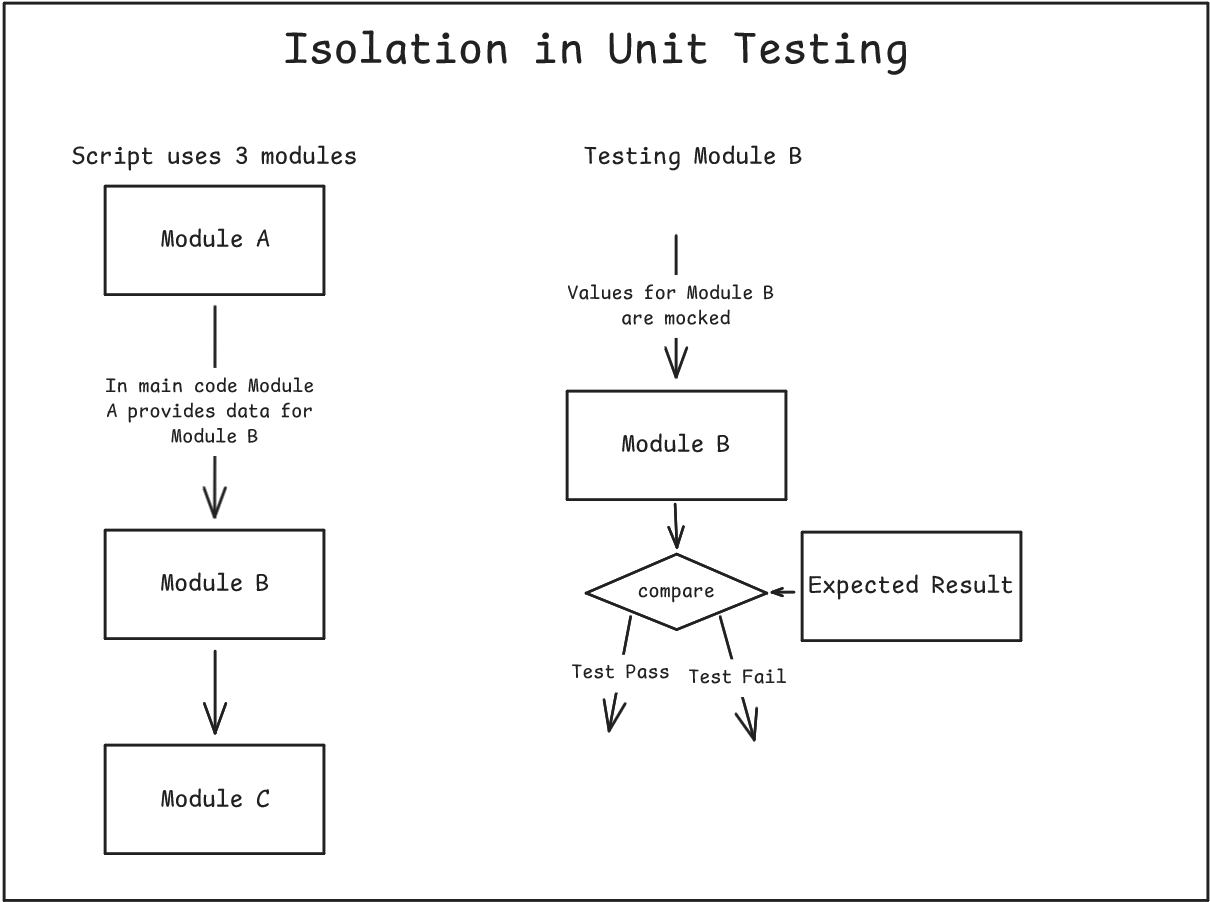
-
Automation
- Tests should be run frequently and automatically, often this entails using a CI/CD platform to run tests on actions like a pull request or merge etc.
-
Repeatability
- It goes without saying but a test should produce repeatable results. A test that sometimes passes and sometimes fails (perhaps due to timeout error happening periodically) should be addressed.
-
Self-Checking
- Tests should have clear pass/fail criteria built in to avoid the need for manual oversight on the test result.
Applying Unit Testing to Data
Unit testing principles, though rooted in traditional software development, are incredibly valuable in the data engineering world. While the core concepts remain the same, their application can vary depending on the tools and technologies at hand.
Take the principle of isolation, for instance. In a data context, this might look different from its original software development conception, but it's no less important. We can apply this principle across various tools, though the degree of adherence may vary.
For example, when working with Python, we might test a transformation function in a way that closely mirrors traditional unit testing. We'd provide mock values, run them through the function, and check if the outcome matches our expectations. This approach is a pretty faithful adaptation of unit testing principles to data work.
SQL queries can also be subject to similar testing methods. We can feed mock values into a query and compare the results against expected outcomes. However, the ability to perform these tests often depends on the available software. Tools like utPLSQL for Oracle, for instance, can be useful for facilitating SQL-based unit testing.
In a data context, we need to consider additional testing scenarios that might not arise in traditional software development. For instance, we might want to test data outputs or changes in the state of a table. Are new rows appearing as expected? Are existing rows updating correctly? These are considerations that might mean the need to expand the scope of unit testing in the data context.
Here are some ideas for unit testing in the data world:
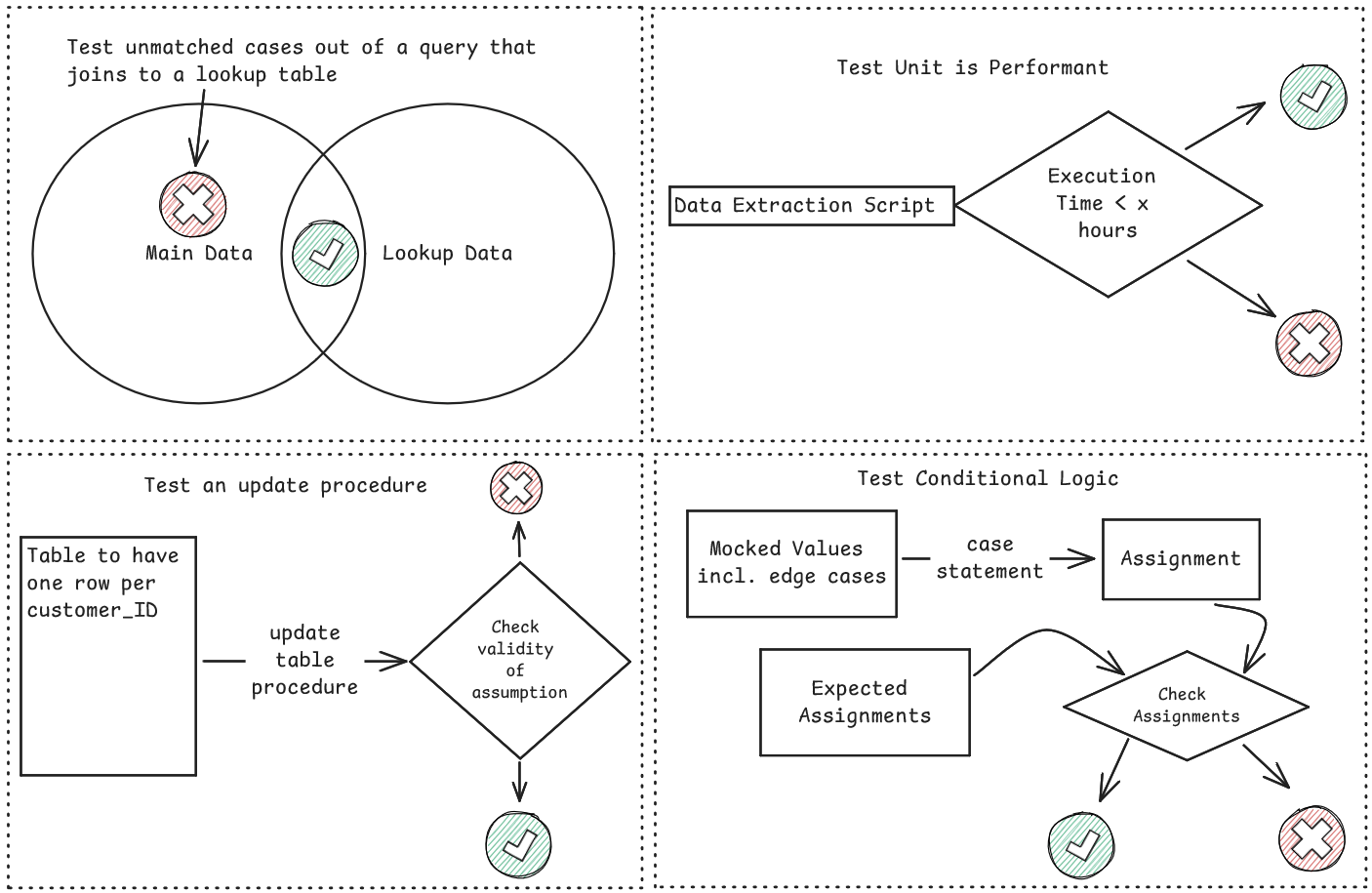
dbt's New Unit Testing Functionality
In the past, dbt's testing suite was designed around 'data' tests in the sense that they could only be executed after a model had been built in the dbt process - in DAG terms it meant that the model was built and then the test was run on the model and then if the test failed the build was terminated at the test failure point.
dbt Core v1.8 and versionless dbt Cloud environments now have access to unit testing functionality. This allows models to be tested on static inputs before the model is materialized. This is a simple but impactful update that this blog is excited to discuss further.
At the moment unit tests can only be set up on SQL models, the models cannot be materialized as views or include recursive SQL. These unit tests are defined in a YML file in the models/ directory.
Worked Example
What follows is a basic example that hopefully demonstrates the utility of unit tests:
We have been asked to build a model off an existing customer_spend model that classifies employees based on their total spend in order for the business to ensure a certain quality of service for high value customers.
To build out this feature the developer notices two things early on that make this well suited to unit testing:
- the model is going to be of high criticality and business facing
- the classification process is going to require a case statement which introduces edge cases that a unit test can help flag.
In the interest of test driven development the developer writes a unit test out with the edge cases he can think might possibly enter the model to ensure the code handles these edge cases.
Unit tests are specified in a YML file as noted above. The test code in this instance looks like so:
unit_tests:
- name: test_is_spend_classification_valid
description: "Check that the spend classification logic captures all considered edge cases and classifies them accordingly"
model: customer_classification
given:
- input: ref('stg_customers')
rows:
- {total_spend: 50}
- {total_spend: 0}
- {total_spend: -11}
- {total_spend: 2.1}
- {total_spend: 20}
- {total_spend: NULL}
expect:
rows:
- {total_spend: 50, customer_segment: High Value}
- {total_spend: 0, customer_segment: No Spend}
- {total_spend: -11, customer_segment: Negative Spend}
- {total_spend: 2.1, customer_segment:Low Value}
- {total_spend: 20, customer_segment: Medium Value}
- {total_spend: NULL, customer_segment: No Spend}
The developer writes the above unit test and then is pulled onto another task and another developer writes the script for the model with limited context on what was agreed with the business. He arrives at the following - unaware of the possibility of a negative spend after refunds are considered.
SELECT
customer_id,
total_spend,
CASE
WHEN total_spend >= 50 THEN 'High Value'
WHEN total_spend > 20 THEN 'Medium Value'
WHEN total_spend > 0 THEN 'Low Value'
ELSE 'No Spend'
END AS customer_segment
FROM {{ ref('customer_spend') }}
In the command line the developer runs the following code (this assumes the parent model customer_spend exists in the warehouse:
dbt test --select "customer_classification,test_type:unit"
A dbt build command would build models in lineage order and run tests as appopriate so would run the unit tests before building the customer_classification model and this would ensure customer_spend exists in the warehouse.
Alternatively you could dbt run selecting a particular model with the empty tag to build an empty version of the model in the warehouse to allow for unit testing the child model. In this example it would look like so:
dbt run --select "customer_spend" --empty
The result of running the unit test can be seen below:
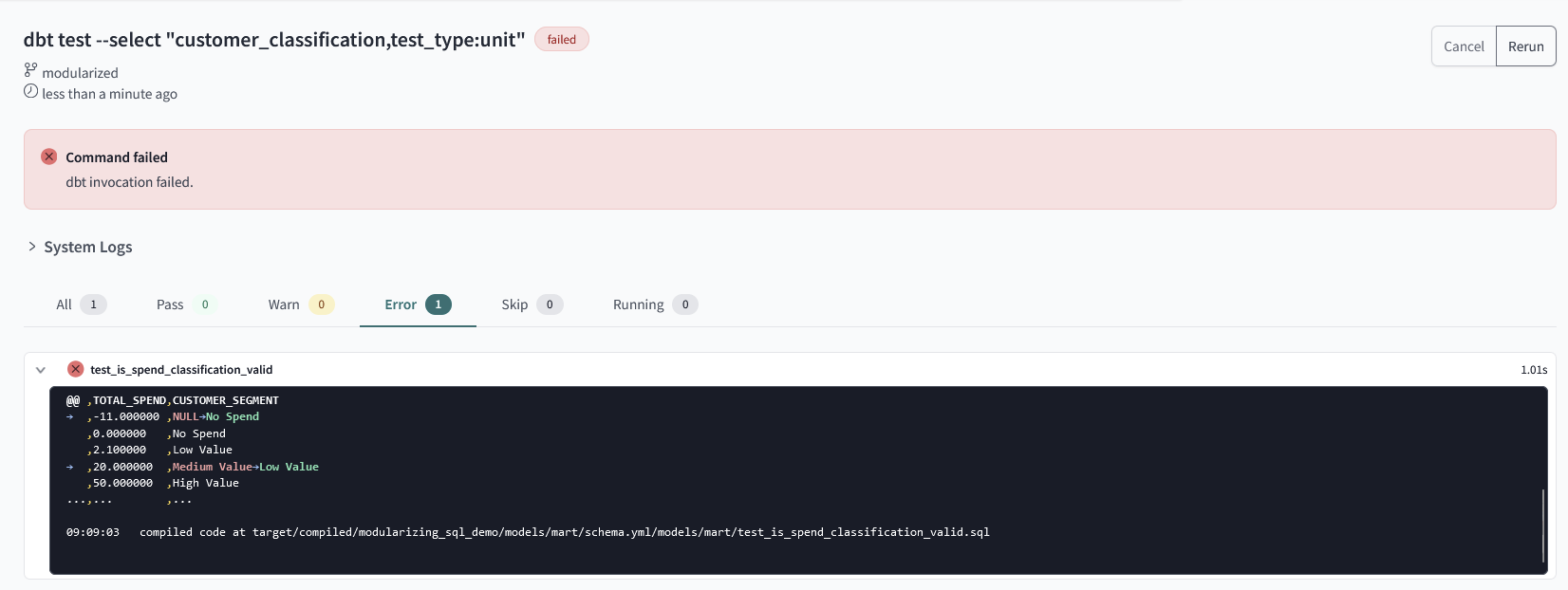
This screen is found in the system logs - the test failed (as we expected) and we also get a useful breakdown of the differences between actual and expected. This immediately flags that in the instance of the negative spend the 2nd developer needs to add logic to accommodate that logic. Furthermore, the unit test flags a typo that might be common when starting to write longer case statements - 20 total_spend has been assigned incorrectly with the current model logic, and returning to the model reveals that an equal sign was missed out in the Medium Value condition.
Unit tests help install rules that ensure edge cases are handled correctly and ensure that code is free of errors that impact logic.
The updated model after looking at the test results is like so:
SELECT
customer_id,
total_spend,
CASE
WHEN total_spend >= 50 THEN 'High Value'
WHEN total_spend >= 20 THEN 'Medium Value'
WHEN total_spend > 0 THEN 'Low Value'
WHEN total_spend < 0 THEN 'Negative Spend'
ELSE 'No Spend'
END AS customer_segment
FROM {{ ref('customer_spend') }}
Line 6 has turned from total_spend > 20 to total_spend >= 20. Line 8 is an inserted line to add a condition for negative spend edge cases.
This model logic passes the test:
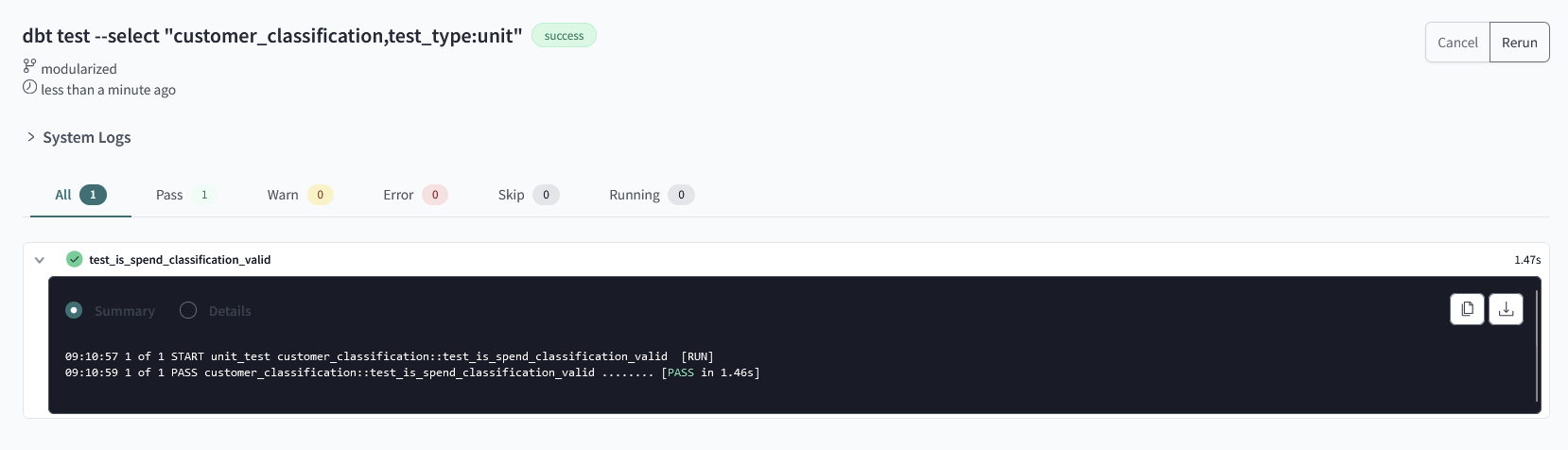
The final point to note is that I have not actually performed a dbt run or build. Instead, I used the select functionality and specified to run unit tests only. As a result, the customer_classification model is not materialized in my warehouse.
This blog has introduced the concept of unit testing and related it to data engineering work demonstrating how it can provide value in development. Finally, I hope it has encouraged you to check out dbt's new feature which I think has been implemented pretty seamlessly.