


The following blog introduces the principles of modularization in software engineering more generally before focusing on how these principles can be applied to SQL with the help of dbt.
Origins of Modularity When Thinking about Code
Modularity is a key principle in programming that involves compartmentalizing different parts of a software application. The goal is to break code into smaller, more manageable chunks. For example, consider developing an app to track tasks. From a project management perspective, modularizing the app clarifies the overall structure even before examining the code for each feature.
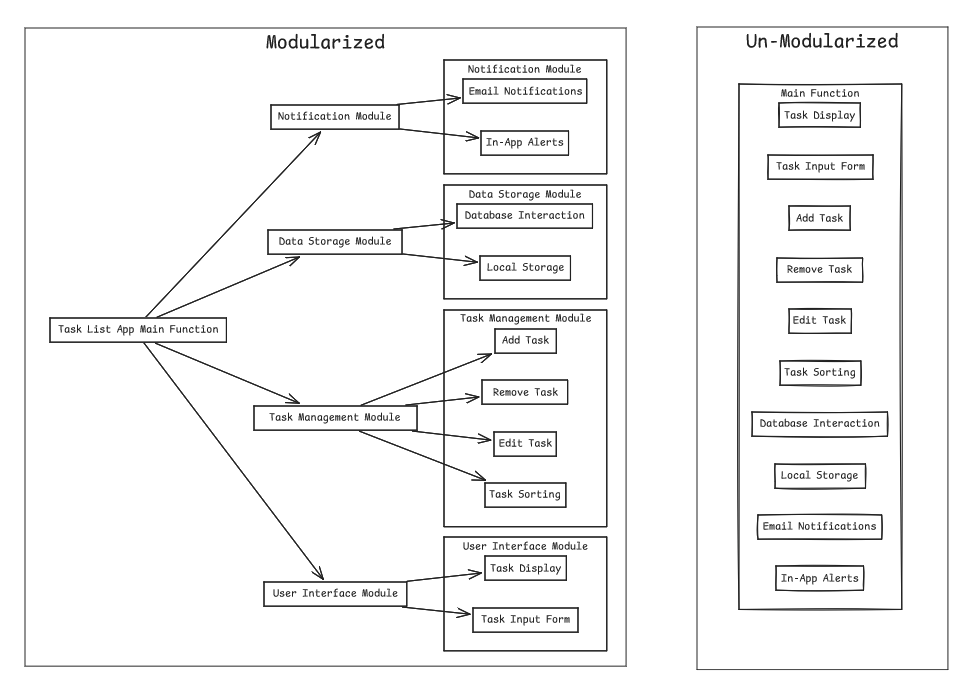
Benefits of Modularity
Modularity offers a range of benefits:
-
Improved Code Readability: Breaking code into smaller, manageable chunks makes it easier for developers to read and understand. Instead of grappling with a single long script, developers can focus on specific features, such as email notification functionality, without the distraction of unrelated code.
-
Enhanced Code Reusability: Modules can be designed to be parameterized, allowing them to be deployed in various scenarios. For example, logic related to task treatment can be separated into a module and reused across different task modules, reducing redundant code.
-
Easier Debugging and Issue Isolation: When issues arise, modular code allows developers to isolate and address problems within specific modules without impacting the entire system. This isolation simplifies the debugging process.
-
Efficient Feature Development: Modular design enables developers to work on different modules simultaneously, facilitating parallel development. It also makes it easier to add new features or expand the project without rewriting the entire system.
-
Simplified Testing: Testing individual modules is generally easier than testing a monolithic system. Each module can be tested independently, which simplifies the identification of problem areas and helps ensure the reliability of the overall system.
Applying these principles to SQL
The above section outlines the inspiration behind trying to modularize SQL code, this section delves into the application of these principles.
Legacy SQL
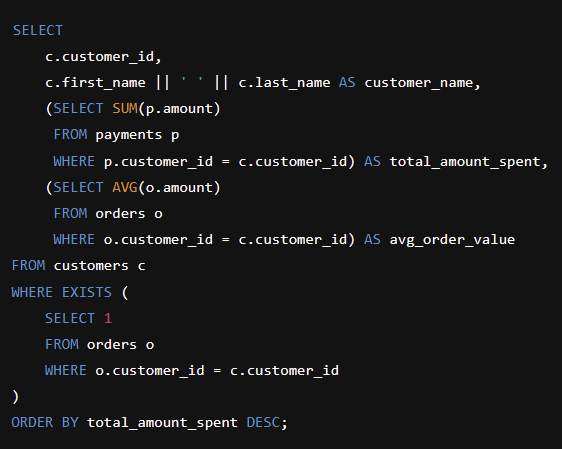
-
Repeated Logic Across Queries
Businesses often have a range of queries across the business to generate tables for different reports. This approach can lead to repeated logic across queries, as each one is tailored for specific reporting needs, but might contain some shared logic creating redundency. -
Scattered Table References
Scripts used to produce these reports frequently pull data from different tables. The references to these tables can be spread throughout the script, making it harder to trace which tables are being used and how they are interconnected. -
Challenges in Error Identification
Due to the complexity introduced by multiple table references, subqueries, and CTEs, it becomes difficult to identify where errors occur. Debugging such issues requires carefully tracing through the entire query to understand how different parts contribute to the problem.
Modularized SQL (In Principle)
- Avoid Redundancy
Breaking up a query into smaller chunks where the output of each module is something that has value across the business allows a piece of code to be run once but for its output to be drawn upon by a range of other modules that produce reporting tables.
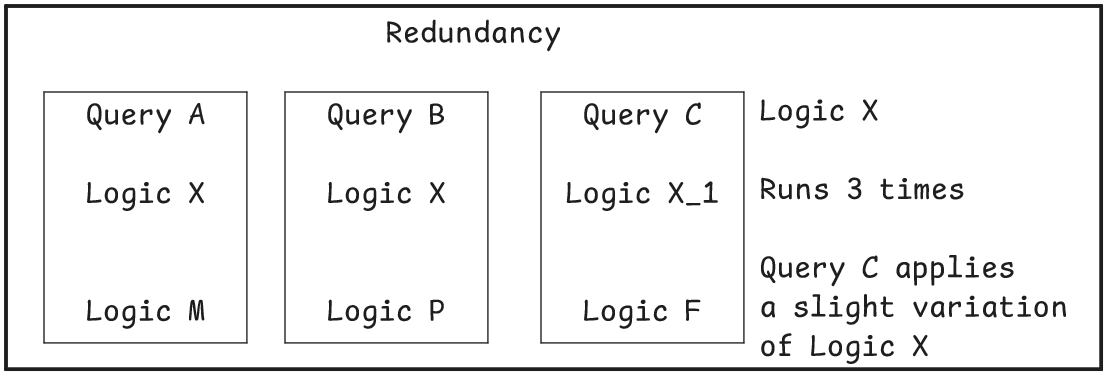
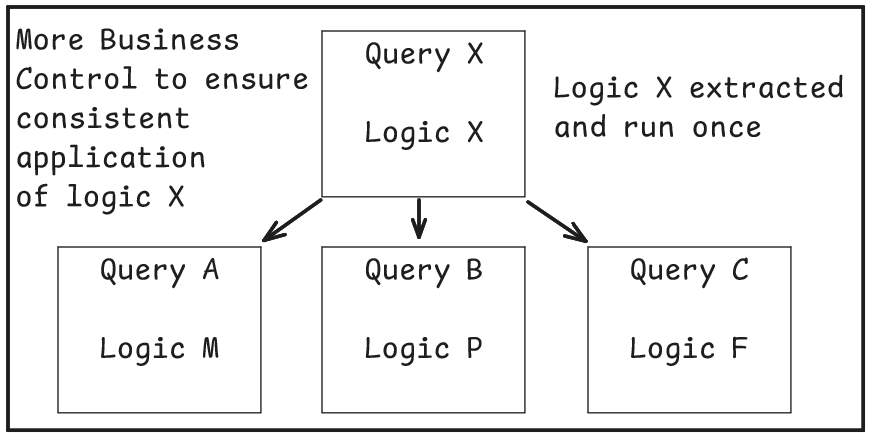
- Clearly declare imports
Modularized SQL can simplify scripts by clearly indicating where data for a query is coming from. Similar to how Python uses import statements to bring in packages, modularized SQL scripts can use Common Table Expressions (CTEs) at the top of the script to import the necessary data in one place.

- Error Identification
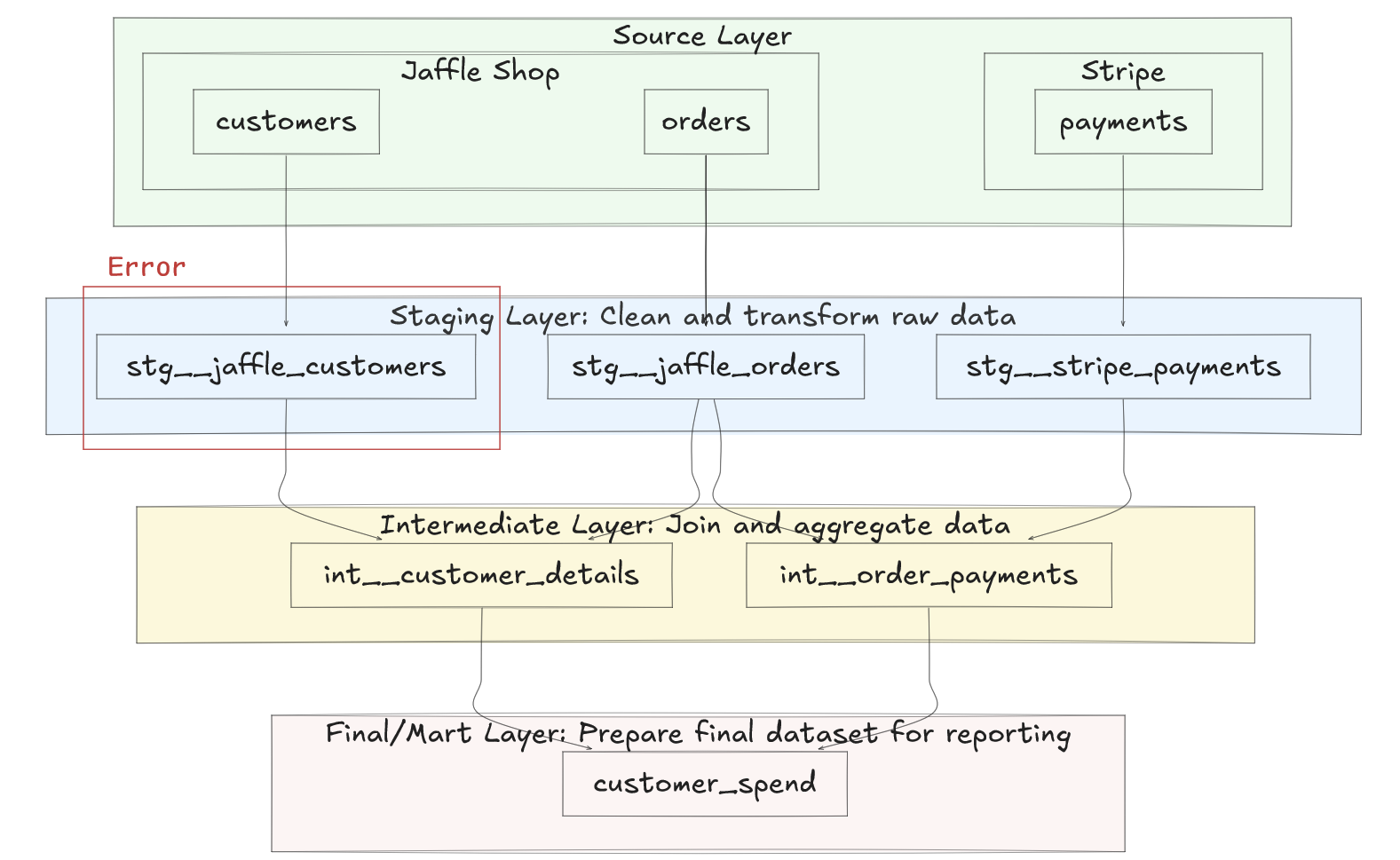
Modularizing SQL code allows for easier identification of where errors occur. When a specific module fails, such as a staging model, it immediately narrows down the problem area. This precision streamlines the debugging process, making it easier to identify issues like changes in source data that may have broken a particular module.
How can dbt Facilitate Modularization?
We've covered the roots of modularization and discussed how it can be applied in principle to SQL code. Now it's worth exploring how toolsets like dbt can help turn the theory into practice.
Models as Modules
dbt is designed with a shift from longer scripts to individual modules which they call models that handle certain business logic or transformations.
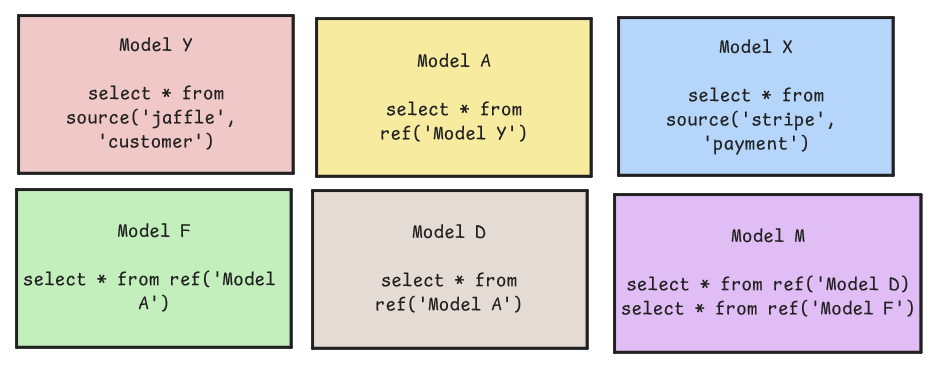
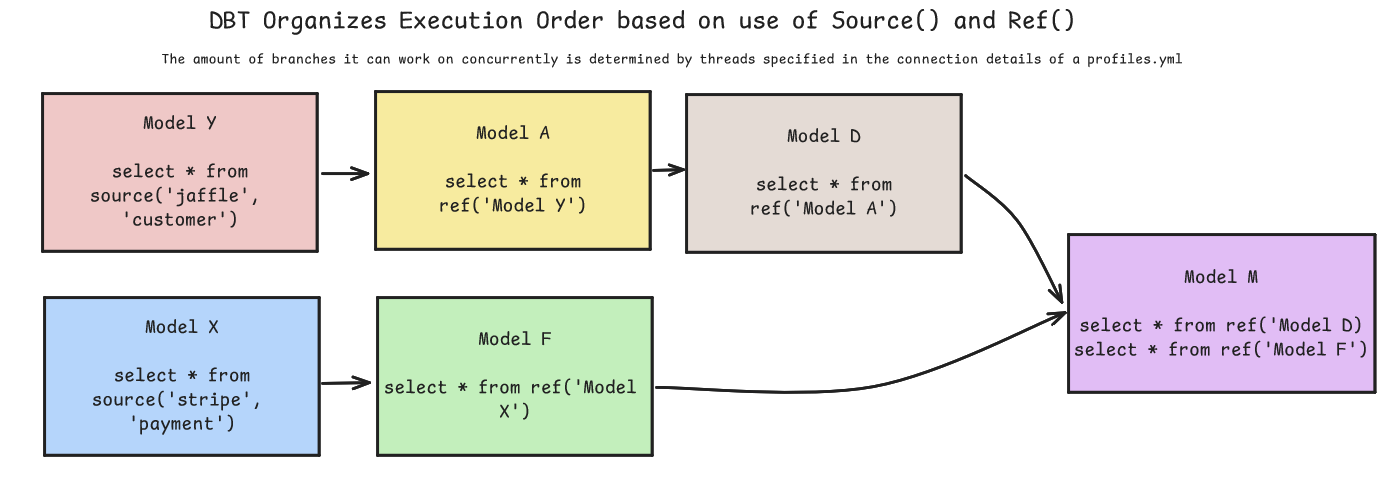
dbt streamlines the modularization process with the availability of source() and ref() macros. These allow dbt models to refer to certain source tables or other dbt models from a model. The Directed Acyclic Graph (DAG) that shows the flow of data from source to destination is automatically generated off the use of these built-in macros. Furthermore dbt sends the models to the warehouse for execution in the logical order derived from how sources and refs are set up.
Reusable Code (Macros and Packages)
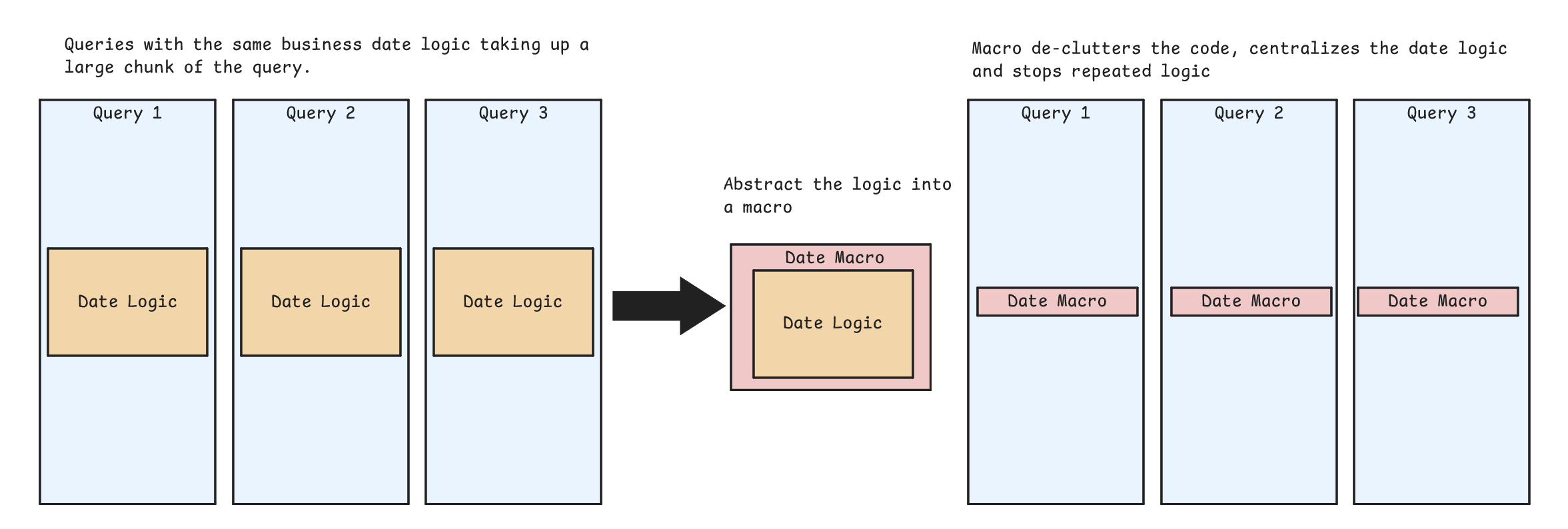
dbt macros function as reusable SQL snippets, allowing you to write repeatable logic without cluttering your models with full code. A practical example could be a macro for a business with a unique financial calendar. Instead of using traditional Q1, Q2 classifications, you could create a macro that, using Jinja templating language and a date table, returns quarters as defined by the business.
Packages in dbt are collections of pre-built models, macros, or tests that can be easily integrated into your project. This approach prevents reinventing the wheel by leveraging existing code. A simple but effective package is dbt_utils, which offers quality-of-life improvements like simplified SQL pivoting and shortcuts for listing column names. Another valuable package is audit_helper, particularly useful when refactoring code. Its compare_queries macro efficiently verifies that your refactored code's output matches the original, ensuring accuracy in your transformations.
I tried my own hand at creating a dbt macro to replicate the functionality of one of my favorite Alteryx tools: the Dynamic Rename which can rename columns by taking names from the rows of another input. It has other functionality but that was what I wanted to replicate. You can check out the project here.
Testing for Model Behaviour and Data Quality (Singular and Generic Tests)
With code broken up into smaller easier to understand chunks, dbt also facilitates the testing of models and source data to ensure it meets certain assumptions or performs as expected. Singular tests can be written in the form of a sql query referencing a model that will fail if any records are returned.
Generic tests are sql queries that are parameterized so they can be applied to multiple models/columns (depending on the test script). These kinds of tests are applied in YAML files.
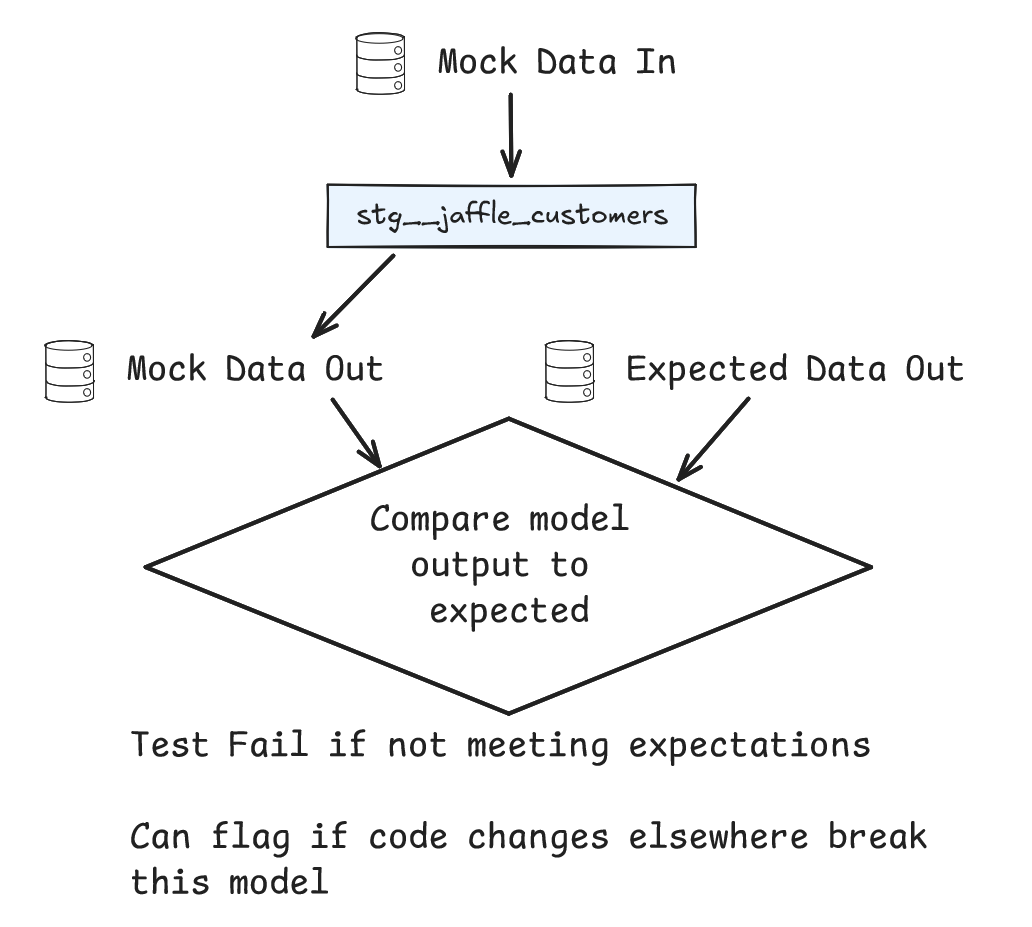
Jinja can also be used to mock values. Mocking is when code has external dependencies these dependencies are replaced by values that simulate the dependencies in order to verify that the individual model is what causes the issue rather than a dependency.
Hopefully the above has given a good introduction to the principle of modularization, how it can be applied to sql code and how dbt helps facilitate its implementation. If you are interested in a simple example of refactoring be sure to check out this repository that contains an annotated example of refactored code.