


What is an Incremental Model?
An incremental materialization is one of the built-in materialization types that dbt offer (table, view, materialized view, ephemeral, incremental). The distinguishing feature of an incremental materialization is that rather than running sql on a full load of the data, only a portion of the data is processed and appended/merged to previous data.

The is_incremental() macro is doing the heavy lifting here determining what code is sent to the data warehouse to execute.
How do I know if my model will run incrementally? Check out the flow chart below:
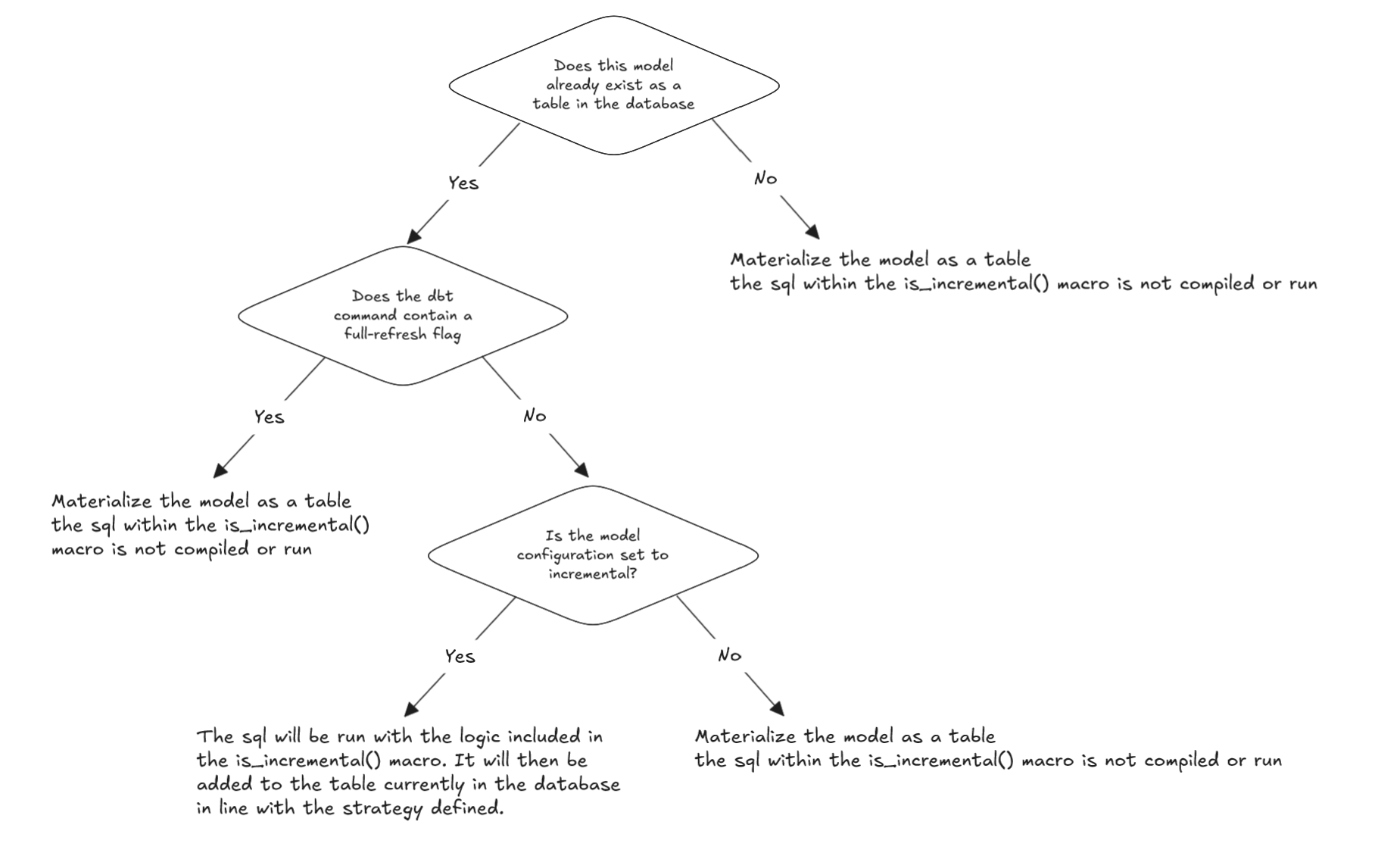
The flow chart is not indicative of check order - its effectively 3 checks and if any of the below checks are true then we would observe a full load of the data (missing the incremental block):
- The table does not exist in the warehouse = TRUE
- The dbt command contains a
--full-refreshflag = TRUE - The model does not have an incremental configuration set = TRUE
Then the code run in the above model would be:

Conversely assuming all the above are false we would get an incremental run where only a subset of the data is run and then added to the existing table in the warehouse depending on the strategy used:

Why use Incremental Models?
Incremental models are useful for reducing the run time of models that process large amounts of data, this can allow for more frequent data refreshes by reducing the amount of time and expense a refresh takes. Then full-refresh runs that process all the data can be scheduled less regularly at non-peak times allowing data to be as current as possible despite size.
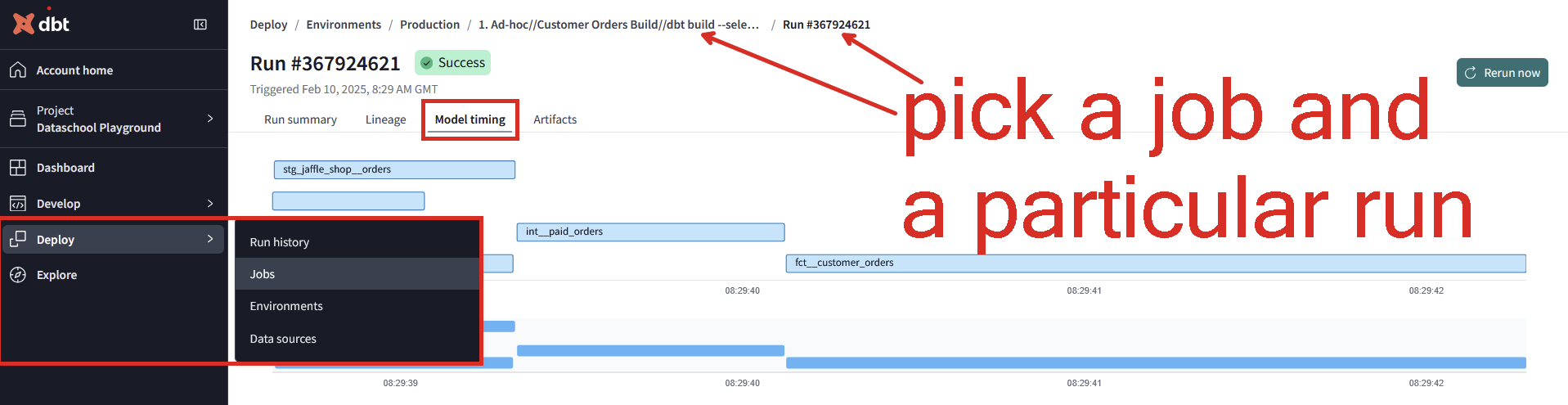
You can observe the benefits of an incremental run using dbt Cloud's explorer. Looking at the model timing tab for a particular job can help you identify bottleneck models that could be improved with incremental logic and also observe the time savings upon making the switch.
How do I setup an Incremental Model?
As with most things in dbt configurations can be specified in different places, across a dbt project for all models or specific models in the dbt_project.yml, configurations can be set in a .yml file in a model directory or a config block. I personally opt for the second of the three as a means to group and organize configurations but the other options are valid.
With that said I often opt for a configuration block to set the materialization as incremental in the model itself so that it is abundantly clear the model is incremental, as that configuration is more specific (in a particular model), it takes precedence so assures the model is materialized if there is a conflict with the .yml (You'll want to resolve this if this is the case to avoid confusion in your project) .

We will unpack the configurations below.
Understanding key incremental configurations
YML configurations
Below is an example configuration for an incremental model. The basic configurations are the priority to understand here - specifying that the model is to be run as incremental, the unique key to use when determining if data is new or needs updating and the incremental strategy.
Breaking down some of these configurations a piece at a time:
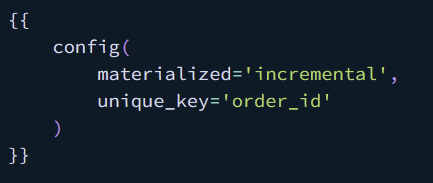
The materialized config shouldn't be too new, as it's used to change whether a model is materialized as a view, table, materialized view etc.
The unique key is a very important configuration as it tells dbt that data can be updated/replaced rather than simply appended on. So without the configuration you could only add rows to a table but with it you can update existing records and add new ones making the materialization type more applicable to different scenarios.
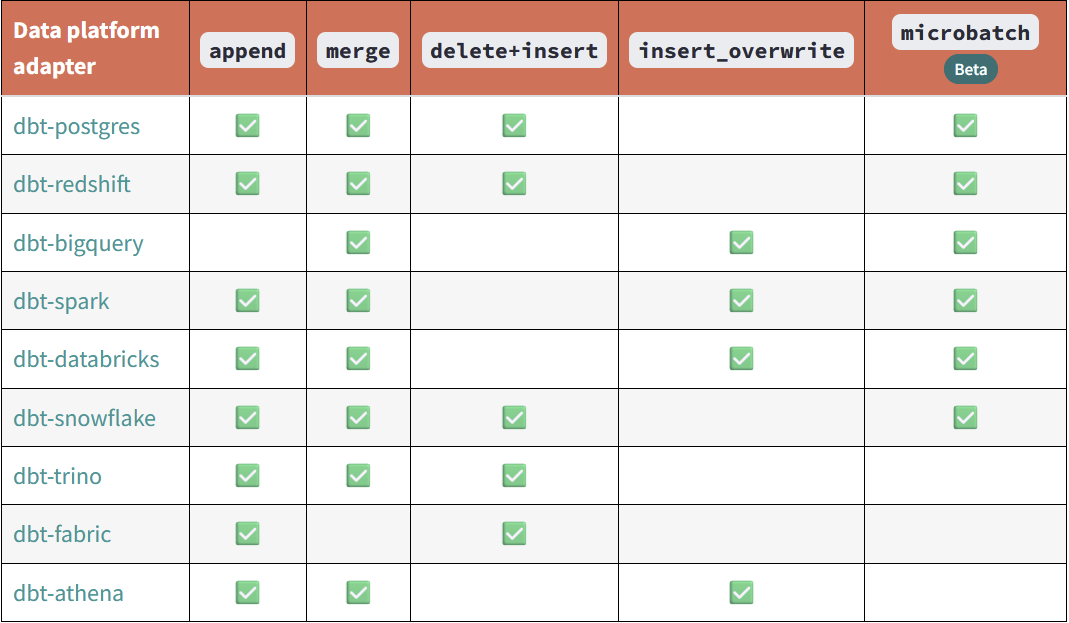
Strategies vary by the platform dbt is connected to. It's best to consult the documentation for compatibility. The link in the below image will take you to the strategy documentation.
Note with an append strategy, no unique key is required as the data will be appended to the table regardless.
on_schema_change is the first of the advanced configurations listed here but one to be aware of - this impacts how source table changes are handled, given that the incremental model adds new data to previous data an obvious problem is when a schema changes
Options to handle the schema change include:
ignore: A new column added to the source schema will not be pulled through to the incremental model. Conversely, if a column is in the incremental model but not the source schema it will failfail: Any misalignment between source and incremental model column missing or added and the job will fail.append_new_columns: Append new columns to the existing table. Note that this setting does not remove columns from the existing table that are not present in the new data.sync_all_columns: Adds any new columns to the existing table, and removes any columns that are now missing. Note that this is inclusive of data type changes. On BigQuery, changing column types requires a full table scan; this is important if you have concerns about running
Documented .yml configuration:
```
model:
- name: my_incremental_model
config:
# Basic Configs
materialized: incremental
unique_key: id
incremental_strategy: merge
# Advanced Configurations
on_schema_change: "sync_all_columns"
# the cluster by will affect how the data is stored on disk, and indexed to limit scans
cluster_by: ['session_start']
# incremental predicates limits the scan of the existing table to the last 7 days of data
incremental_predicates: ["DBT_INTERNAL_DEST.session_start > dateadd(day, -7, current_date)"]
# `incremental_predicates` accepts a list of SQL statements.
# `DBT_INTERNAL_DEST` and `DBT_INTERNAL_SOURCE` are the standard aliases for the target table and temporary table,
# respectively, during an incremental run using the merge strategy.
```More advanced users may want to consider the possibility of creating their own custom incremental strategy that is optimized to their use-case for the most performant deployment. This blog highlights it as a possibility.
The final configurations worth noting are with performance and reducing compute cost in mind with clustering and incremental_predicates which can be used to avoid a full table scan when looking through the source data to apply the incremental filter.
Beyond timestamp logic
A lot of the training material for incremental modelling focuses in on data with timestamps for updating data. This is undoubtedly the preferred setup but in some cases it isn't possible, so I thought it worth talking through one potential approach in case it helps generate ideas for others in this situation.
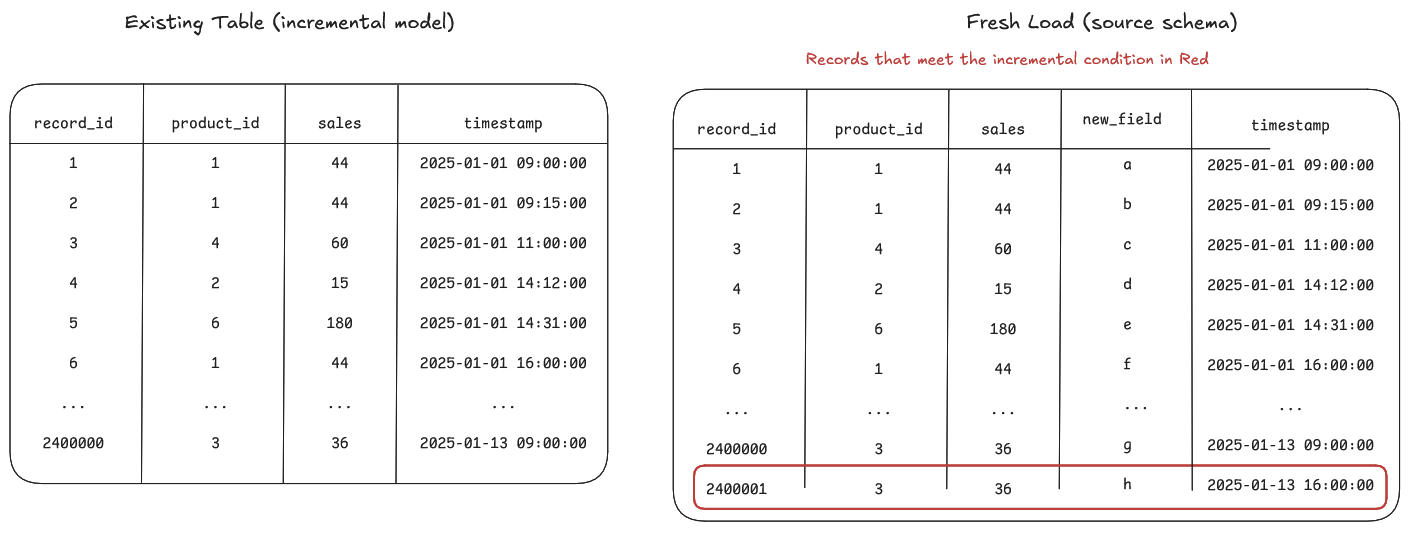
We can leverage the {{ this }} relation (as we do in the timestamp strategy in the where clause) but instead do a left outer join to isolate new (/fresh) data. Visually this would look like so:

Here, the idea would be that data not already in the warehouse is new data and data that matches we could use some hashing to determine if the columns of interest have been updated since the last run and therefore if the data needs to be updated or not.
This is not the preferred set up as it does not scale particularly well to big data but its something to be aware of if the data is lacking timestamp fields.
Concluding remarks
Hopefully the blog has given you a strong foundation in how incremental models work and how they can be used to improve performance in a dbt Project whilst accepting the risk that over time 'drift' from true source may occur. The blog demonstrates how the conditional logic is intended to operate along with breaking down the configurations available for incremental models.
In terms of implementation, dbt Labs to suggest building slow models incrementally throughout the work week for performance and prompt data delivery, then running --full-refresh jobs at the weekend to 'reset' the table back to its true source data where the concern for delivering updated data swiftly is a lower priority to reduce the amount of data drift that naturally might occur in incremental models.