


The following blog is designed to encourage you to think carefully as to how you set up your dbt Project when starting with dbt Cloud. There is a tendency with excitement to get stuck in and learn a new tool to click through multiple setup screens without considering the downstream impact of setup. This blog explores version control configuration options for dbt projects, recommending GitHub/GitLab to leverage dbt Cloud's integrations while maintaining visibility and control over your remote repository.
The blog then discusses when multiple repositories make sense for a business and when they do not. The mono-repo v. multi-repo discussion.
The final part of the blog raises awareness of the custom branch option in Deployment > Environments to really elevate version control in dbt Cloud. It is a feature I intend to return to in a later blog on deployment.
For information on the version control options and what they are doing check out the companion blog to this one here.
When setting up a dbt Cloud instance, you are prompted to make your first project, you give it a name and specify if the project is to be held in a subdirectory of a given project, you establish your database connection, and then are confronted with the first key version control choice:
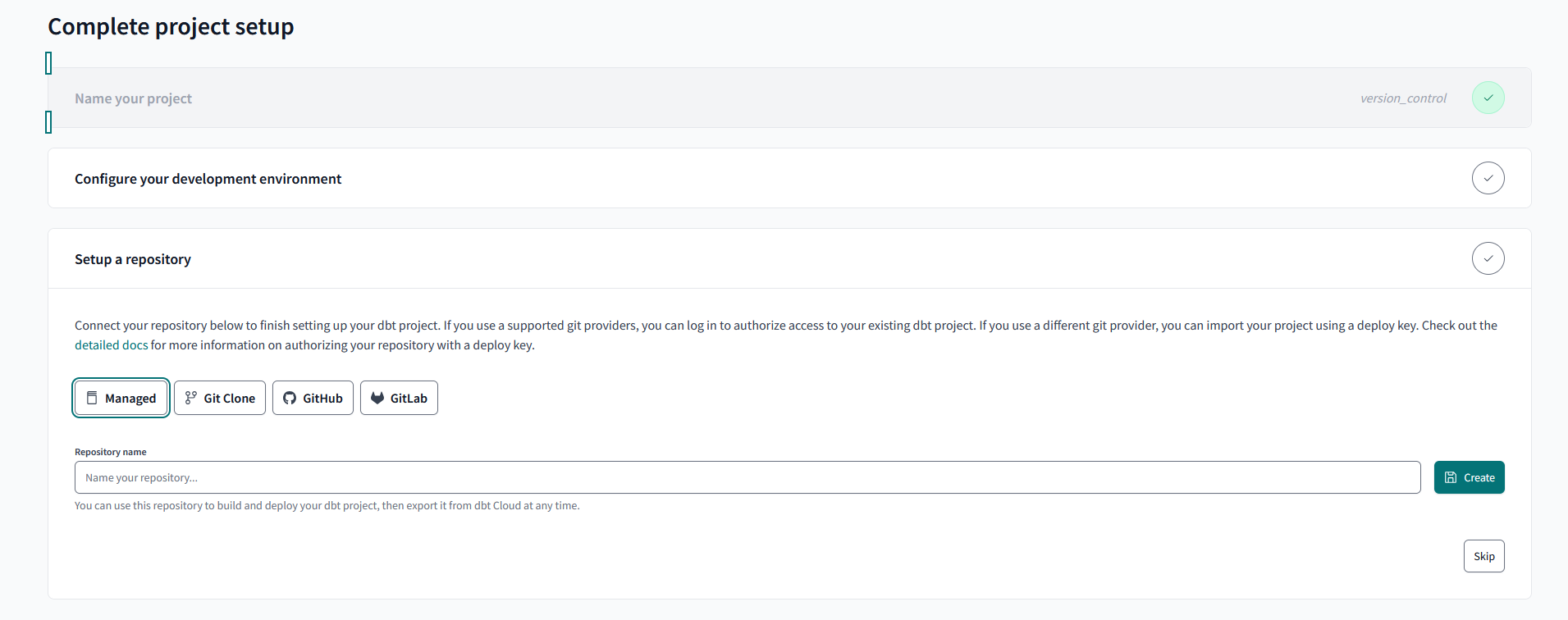
Which option are you going to use to support your version control system?
I'll break down some of the strengths and weaknesses I see with the options and then explain the set-up that I would opt for.
Managed Repository
The managed repository offers a convenient and easy-to-use setup experience. dbt Cloud handles and manages the remote version of your repo and configures it upon initialization with rules that are designed to protect you from.
It is worth prefacing this section with the qualifier that dbt Labs do not recommend the use of a managed repo in a production environment so it is more intended for experimentation and training on the system.
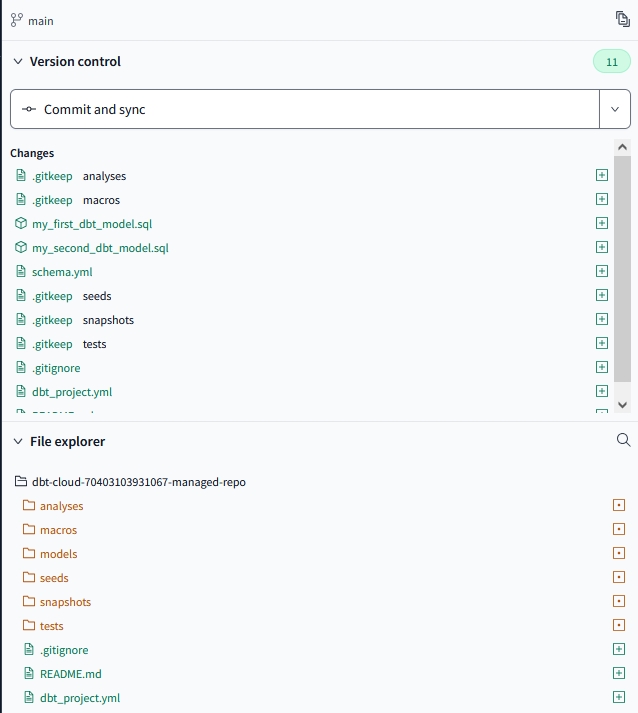
I can tell when I am using a managed repository in my dbt project as the directory will start dbt-cloud followed by some numbers to identify it and finally the repo name:

Upon initialization (pressing the button to initialize the project), cloud allows us to make an initial commit to the main branch:
Once I make the initial commit note how the branch now has a padlock by it:
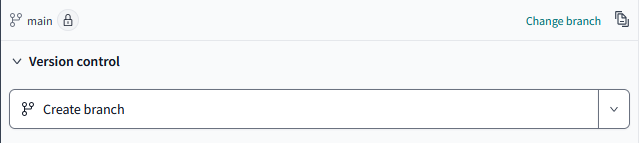
dbt Cloud has added protections to the main branch so that we can no longer modify it directly, we are now nudged when making a change to create a branch, or if you set off coding without doing so when you try and push to the remote managed repo you are again prompted to make the branch in order to apply the change:
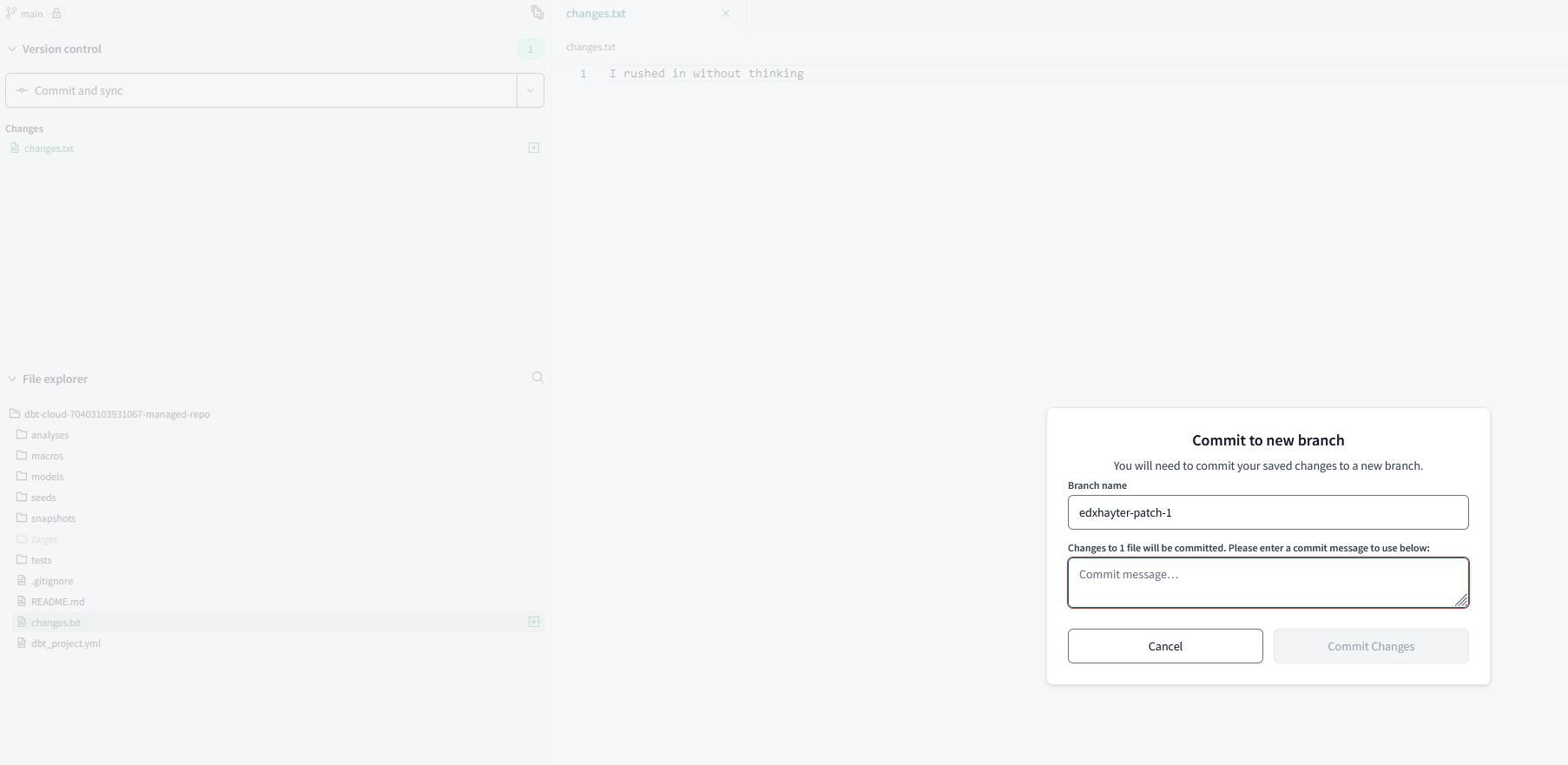
From here, we are effectively set-up dbt Cloud has an effective version control system in that it frames actions in a way to help guide the user, making it an excellent gateway tool for learning the basics of version control, the dropdown version control menu offers contextually relevant commands based on the situation.

In terms of ways I think the managed repository could be improved in order to make it more viable for production use:
- More branch management options, at present branches can be created but branches cannot be closed after a merge for example.
- This would open up options for the branches to be pruned locally and keep the version control options well managed.
- Merge requests, currently there is no infrastructure in place to raise a request to merge - at the moment a developer can merge code without approval rules in place.
- Rollback/reversion options, because the managed repo is a bit of a black box, if you mess something up there is currently little that can be done to address mistakes, often requiring manual fixes and commits. This is good in the sense it ensures a full version history (something rollbacks would disrupt) but more reversion functionality where reversions are commited back to the project would be good.
Git Clone
The Git Clone option allows you to connect to any git URL, you'll be looking for a URL that meets SSH protocol so git@... or ssh:... this opens up the possibility to use your preferred git provider (perhaps BitBucket) but bear in mind these might not have built in dbt Cloud integration meaning custom solutions will be required for CI jobs and integrating the software. It is worth noting that Azure DevOps has dbt Cloud integration and can have automated CI jobs despite it not having a dedicated option. Consequently, I recommend a stack that capitalizes on the current integration options which leads to GitHub/GitLab.
Git Provider Repo (GitHub/GitLab)
For the purposes of this blog I am demonstrating the functionality with a GitHub remote repository integrated into my dbt project.
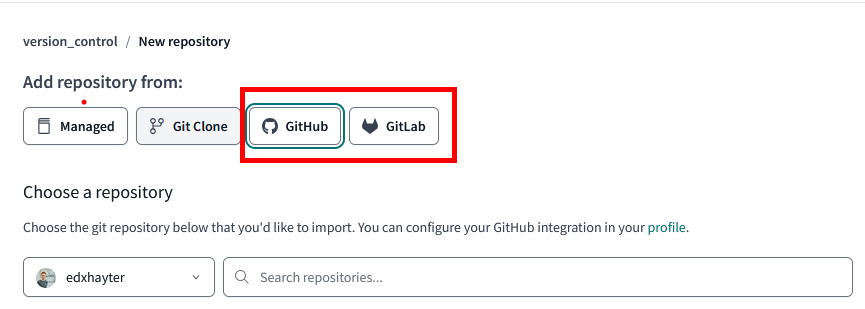
These options require a bit more legwork to set up. Primarily you'll need to create a blank repository in GitHub then point dbt Cloud at that blank repository (including a default readme.md for example will break the process so ensure its blank).
If your repository is going to have documentation that sits above the dbt project level - in the project configuration you would want to enter the name of the subdirectory where you intend to put the dbt project within.
The benefits of this set-up is the remote repository is less of a black-box where you have limited control. In a production set-up you'll be paying for enterprise set-ups on one of GitHub/GitLab but you can control your remote repository - use their functionality for pull requests, CI jobs, or cloning the repository and having a locked down prod repository separate from the UAT repository which can be more agile to development.
What work merits it's own Repository?
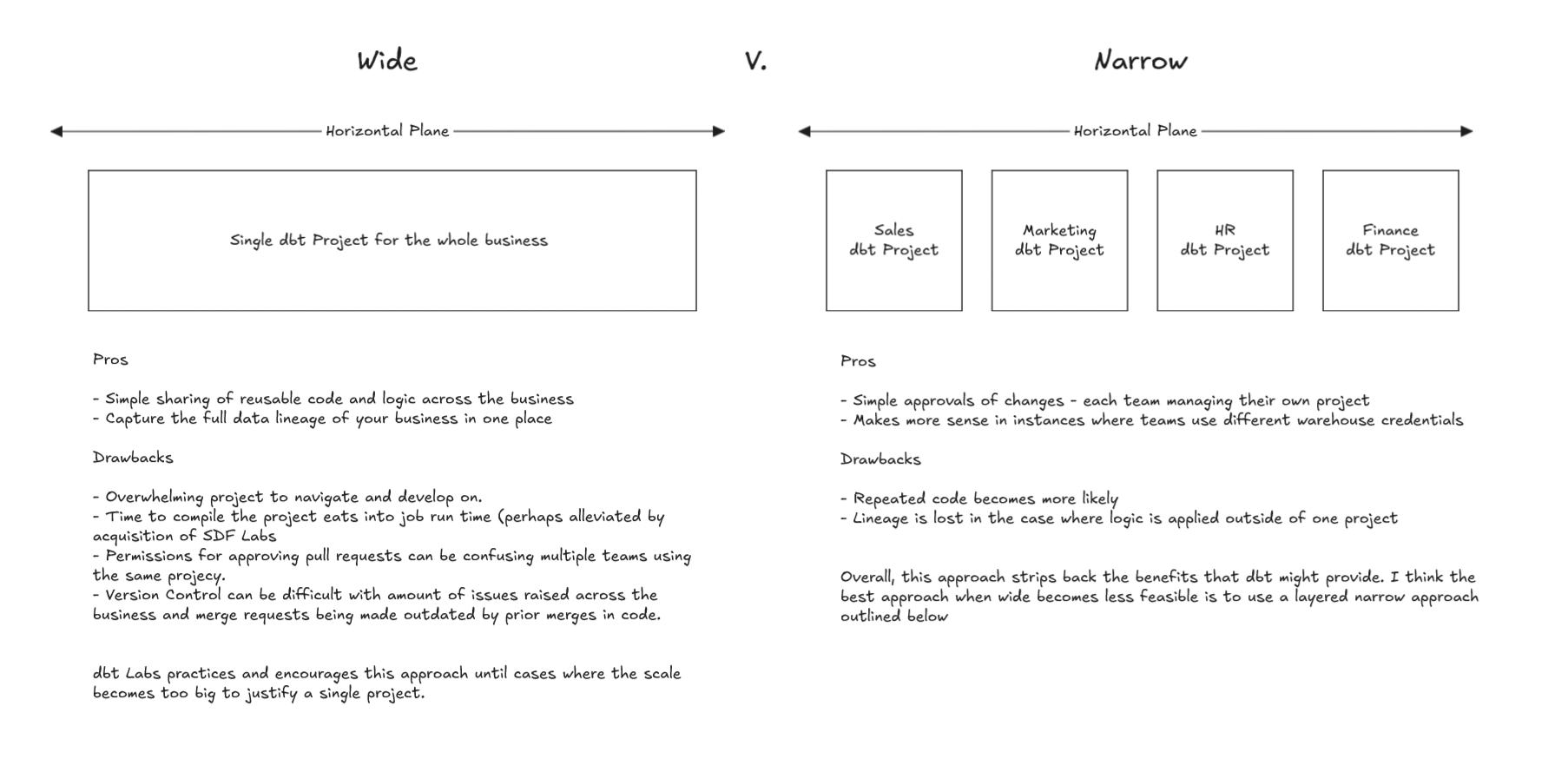
When discussing dbt project set-up within a business, I like to discuss the horizontal setup (business-wide how many repos do we use, do we work in one or split it by department etc.). Below I discuss 3 approaches which I have named myself:
- The wide approach of a single project covering the breadth of the business
- The simplest approach that avoids repeated code and captures as much lineage as possible.
- It has its limits however as a business grows and the amount of models increases compilation and the complexity of the versioning going on (issues, merge requests, governing who owns what and who is permitted to approve what) warrants a splitting of a project
- The narrow approach with multiple projects within the business.
- The likelihood of repeated code and lost lineage is increased in exchange for control and governance with regard to who owns what across the business.
- The 'layered narrow approach' multiple child dbt projects that rely on a shared repo as a package that contains reusable code and models.
- Tries to bridge the gap between wide and narrow offering control whilst retaining a central location for reusable logic.
- This setup comes with greater complexity, it looks great but implementing it might require a more analytically mature business.
Ultimately going as far as possible with the wide approach until it is no longer feasible and hopefully being experienced enough at that point to set up a layered narrow approach seems to be the most logical approach to this challenge. dbt Mesh, an inbound feature for dbt Cloud is going to make the layered narrow and narrow approaches more viable with greater capacity for cross-dbt project management.

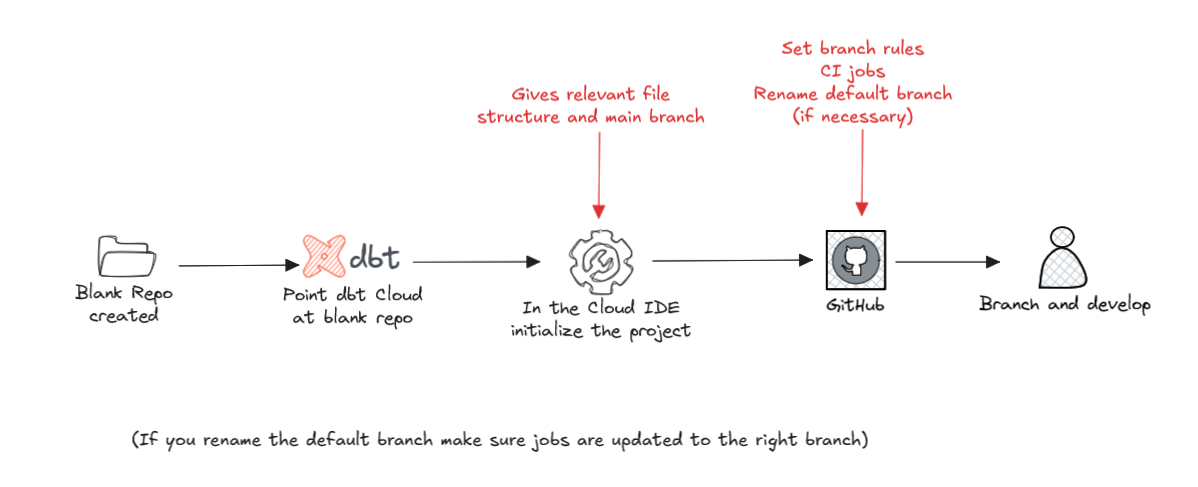
Custom Branches - Elevate Version Control
The topic of this blog is not deployment so I will refrain from discussing custom branches impact on deployment but it is particularly powerful for configuring the ideal DEV, TEST, Prod deployment setup.
When you initialize the dbt Project, ordinarily main will be the created branch and then in the development environment (used within the IDE) it is set as the default branch where branches are created from and merged to. This would make sense if you have a DEV-PROD development process but might get muddled if you have a DEV-TEST-PROD process, particularly as TEST would be expected to be ahead of PROD in the versioning history.
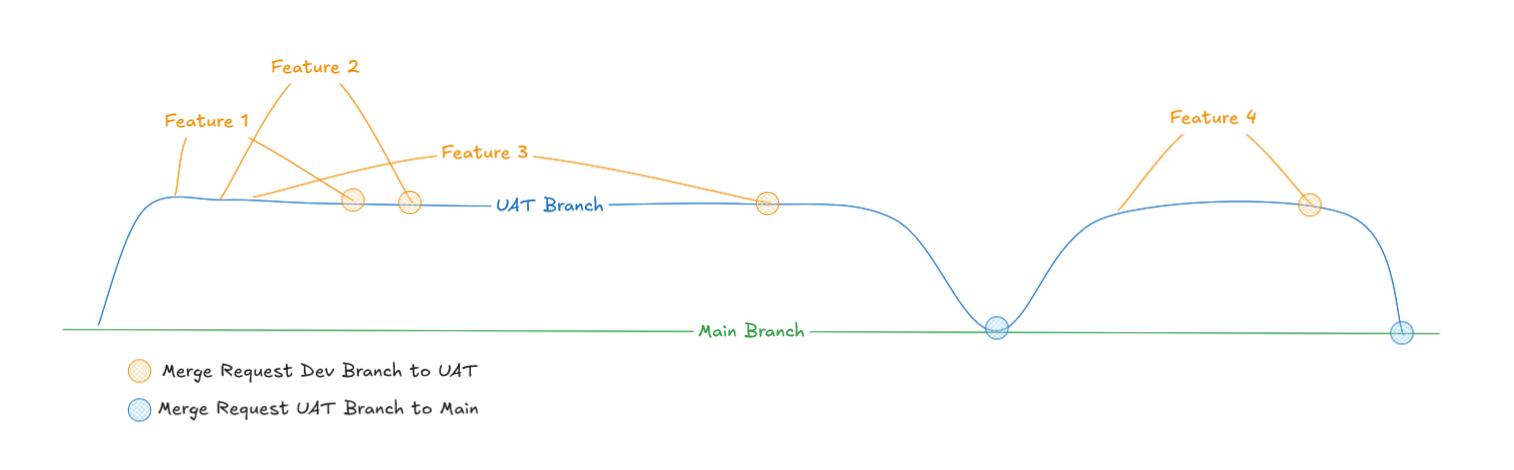
In this case, a developer would not want to branch off main because that is outdated compared to UAT and they will want to merge back to UAT rather than main because the developer will want to test their branch before merging to main.
The problem above can be resolved using Custom Branches within the environment along with Branch rulesets on GitHub/GitLab. First, within the code repository provider, protections should be added to both the UAT and Main branches. This will stop developers on dbt Cloud making changes to Main in the dbt Cloud IDE directly (when we switch the Development Environment to Branch, main will no longer show as locked within dbt Cloud but we can still protect it.
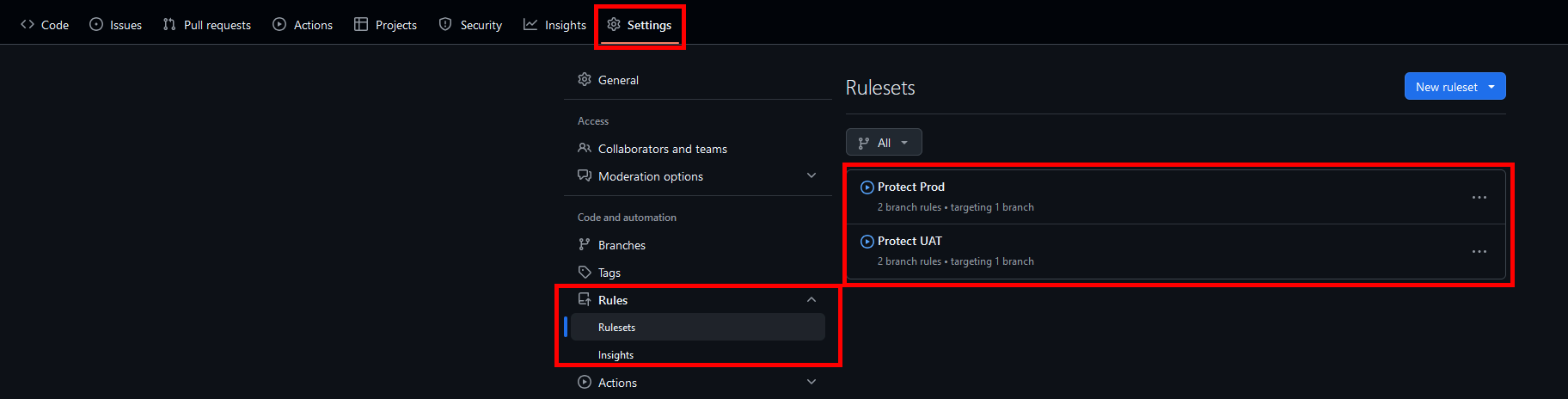
Here I have updated the development environment branch to UAT and created environments for UAT and Production with the appropriate branches selected.
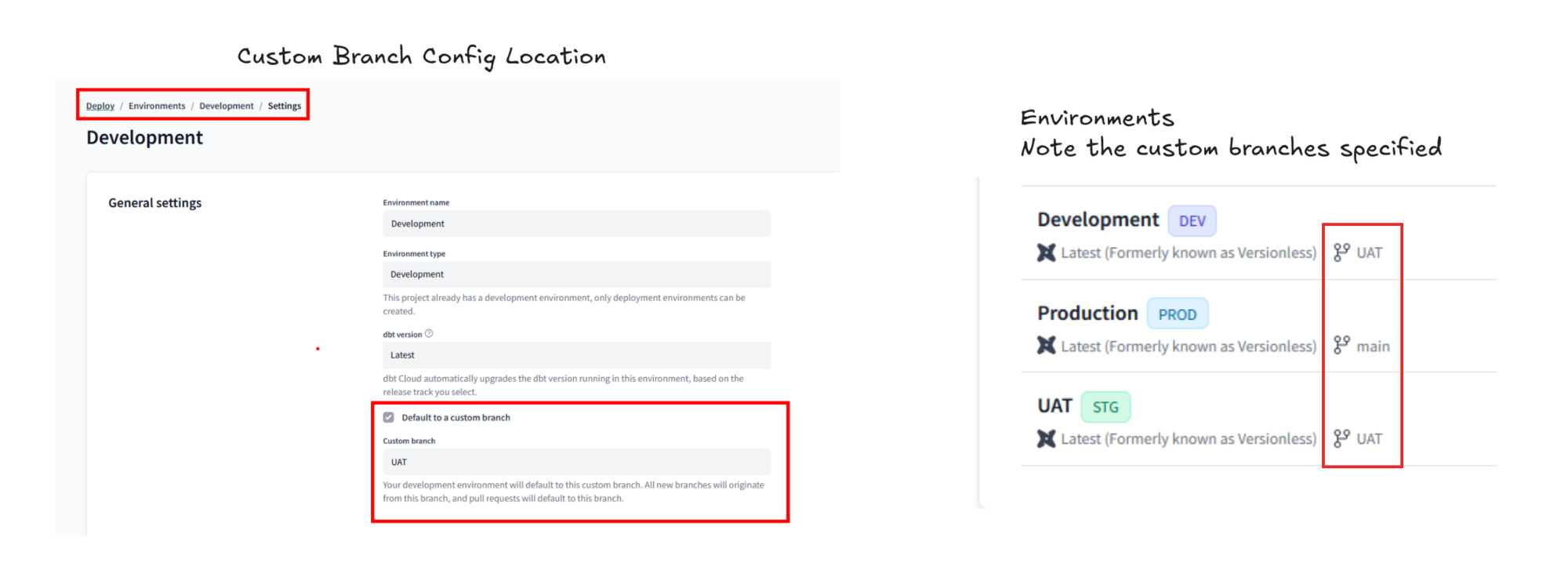
Now in the IDE the main branch lacks the lock, but the GitHub rulesets stop commits and pushes to the branch:
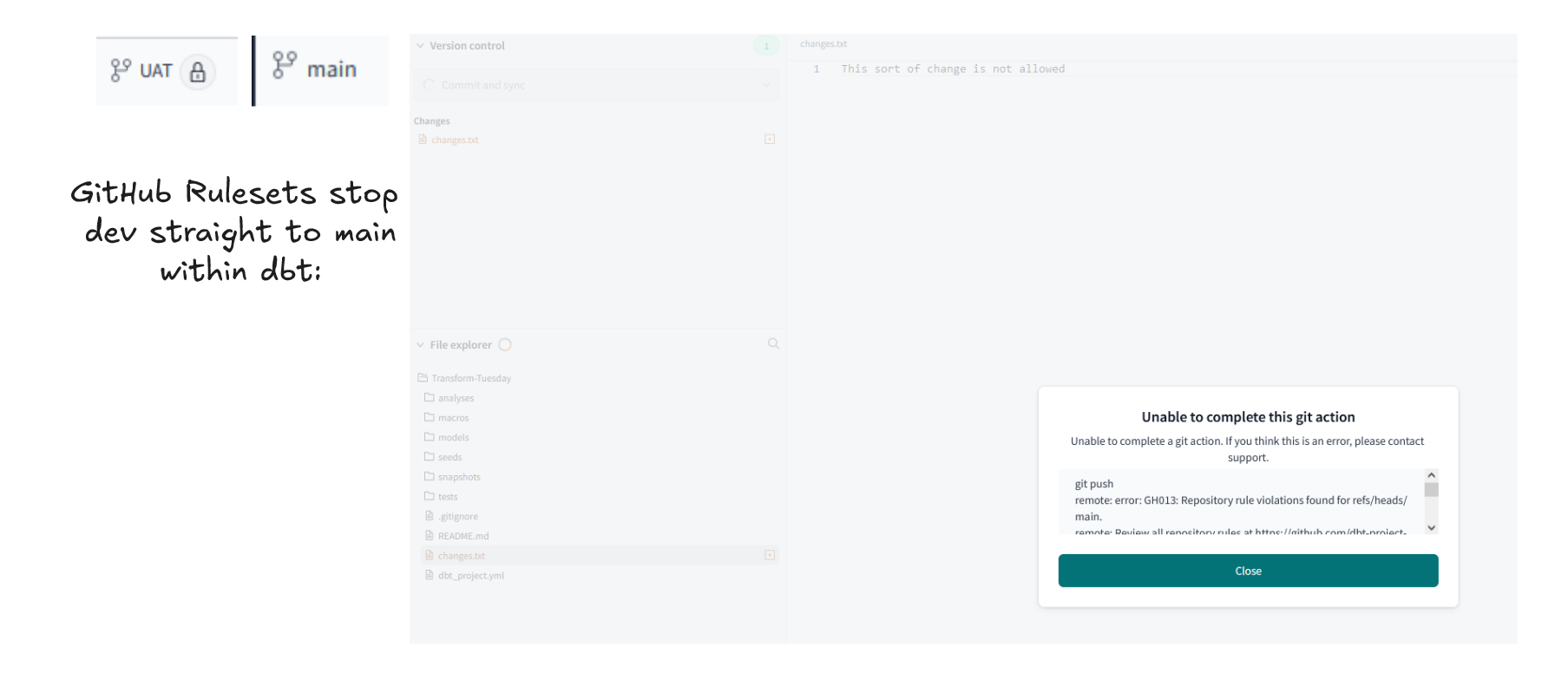
Now we can branch UAT and make dev changes merge back to UAT and have UAT jobs running and writing to a UAT area with the environment configuration. We can have the Production Environment set to run on the main branch within our dbt Project.
When it is time to promote UAT changes to Production we can raise a merge request to do this in GitHub - updating main by merging the UAT into main. Now our jobs set to run in the Production environment will be using the updated code.
These workflows can be enhanced with CI jobs that test code on a merge, potentially supplemented by dry runs, ensuring no data is processed in the CI job but making sure the project compiles and theoretically executes properly.
Hopefully this section has illustrated the power of the Custom Branch configuration in environments and how it can ensure that developer versioning can be kept in dbt Cloud as much as possible (save for merging UAT to Prod). If you are looking for a means to merge UAT to Prod within dbt you could explore having another separate dbt Project pointed at the same repo with main as the default branch but I do not think the benefit is worth the added administration of having a UAT/Prod project when the use of environments can satisfy this requirement when configured effectively.
Conclusion
I hope this blog has proven useful and encouraged you not to rush in skipping the configuration for a dbt Project and thinking carefully about version control setup, project configuration both across the business and thinking ahead to deploying a dbt Project.
Reflecting on writing this blog, for me I was impressed at the integrations and capabilities that dbt Cloud offers to simplify the application of versioning. Nevertheless, I think it still holds true that configuration in a professional setting requires a strong grasp of the software, a willingness to experiment and test things whilst trying to apply a fundamental framework that protects certain non-negotiable rules that you want your project to follow.