


One benefit of using dbt as the tool of choice for transforming data in your data pipelines is the in-built documentation functionality. Using .yaml /.yml (YAML Ain't Markup Language), a syntax intended to be human readable compared to things like XML or HTML, we can give context to our dbt work. It allows us to configure aspects of our dbt project and importantly for this blog provide material to be used in the automatically generated documentation.
Documentation is important for giving context to the data (both incoming and outgoing) and explaining transformations - making processes easier to debug when they go wrong and ensuring that the data is not misunderstood and misused.
The following blog will cover two key areas of documentation, the meta-data for data governance purposes, applying Don't Repeat Yourself (DRY) principles to documentation and a brief section offering thoughts on structuring and documenting SQL for handover to a fellow developer.
Data Governance through dbt Docs
dbt allows for docs generate and docs serve commands to generate and return a documentation site that includes all sorts of descriptions and metadata information for your dbt project. Moreover, you can enhance the governance and cataloguing of data with integrations to software like Atlan rather than relying on the auto-generated dbt docs (the auto-generated material will suffice for smaller projects or those starting out but at an enterprise level it might make more sense to 'buy' a solution and simply integrate with it).
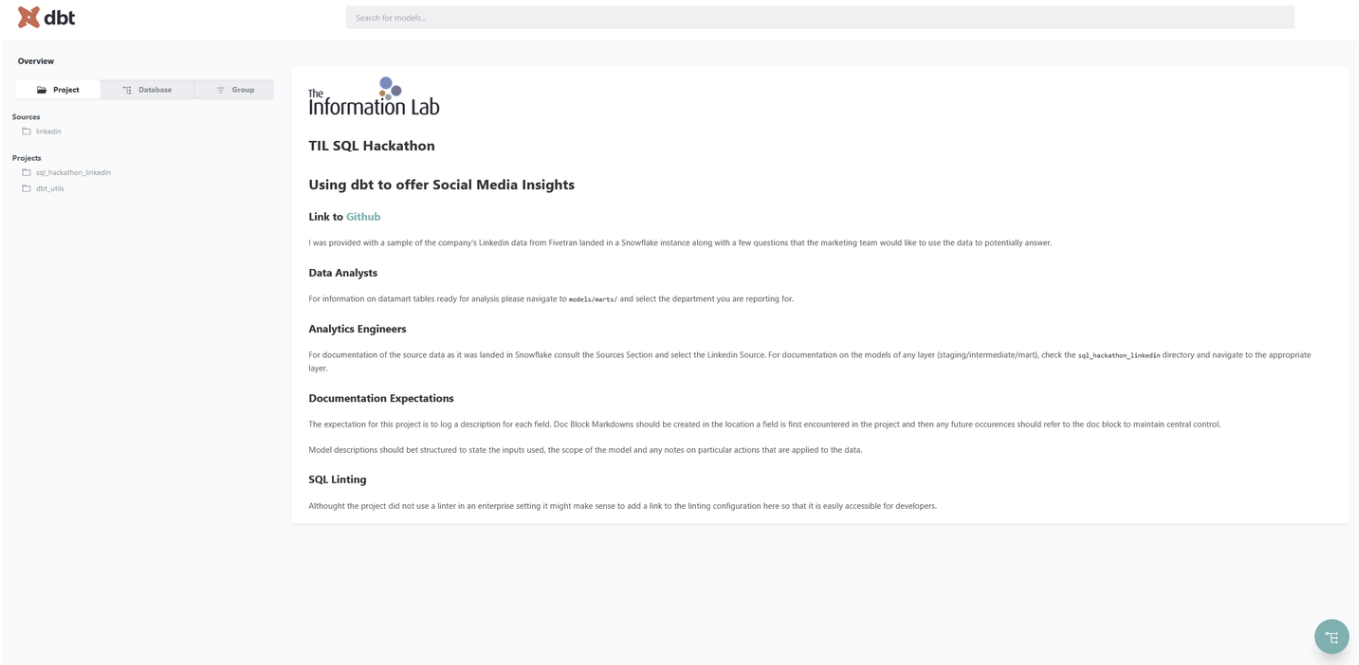
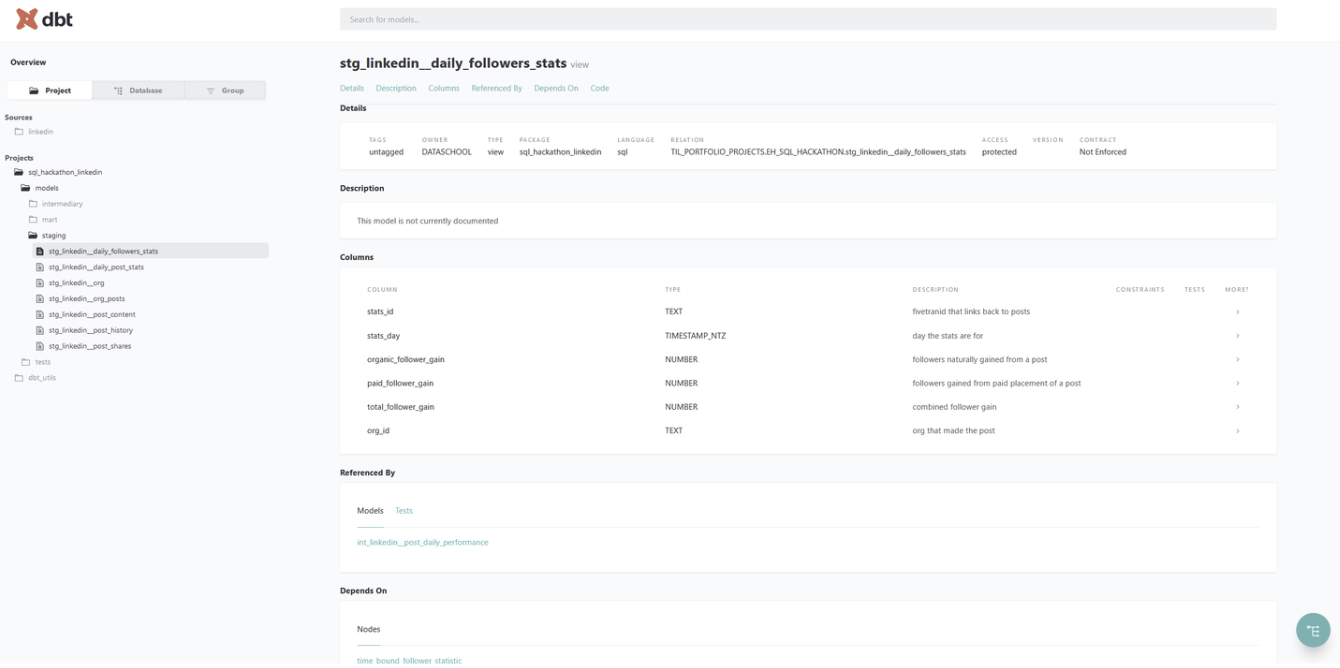
Here is a screenshot sample of a native documentation site (homepage | model specific view):
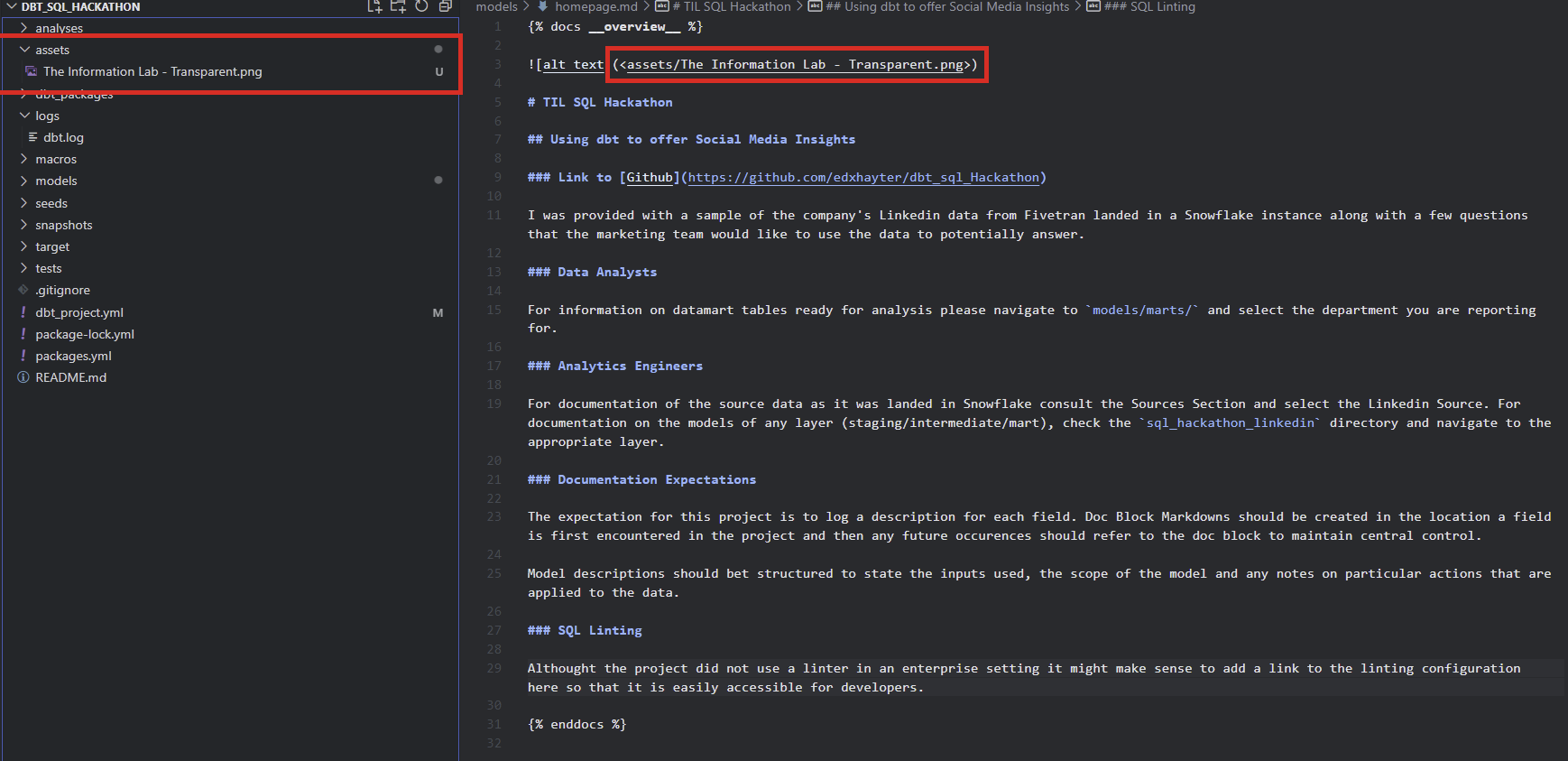
💼 If you want to add some corporate flair to your site's homepage. You can add your company logo to a directory named assets in your dbt project and then in the markdown for your homepage (homepage.md) add the image. I used VS Code and shift-dragged the image into the doc. Check the code below:
How do we populate these sites?
These sites are populated by information stored in YAML files. The staging model above for daily follower stats might look something like this within the project:
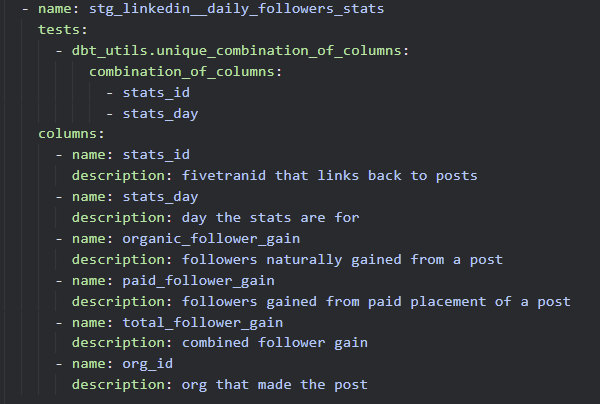
DRY Documentation with Doc Blocks
As a dbt project grows, you might find that documentation for the same column begins to be repeated across models. This can be problematic for a couple of reasons.
- Repeating the same metadata information can be tedious and not the best use of developer time.
- From a governance perspective having the same information in a breadth of places without centralized control is asking for information to lag behind and not be kept up to date leading to discrepancies and worse misrepresentation of data.

The solution to this problem is to leverage doc blocks and an appropriate strategy for the deployment of said doc blocks. Doc Blocks are documentation in markdown files that can be referenced in YAML schemas. A simple example would be in a markdown file adding a doc block with the following JINJA:
{% docs customer_id %}
Unique identifier for a customer recorded in our system
{% enddocs %}Here we use JINJA in markdown to configure a doc block (with the { docs <doc_block_name>}), add our documentation and then close the block. This block can then be referred to in a YAML file like so:
models:
- name: dim_customers
columns:
- name: customer_id
description: "{{ doc('customer_id') }}"
Note that this reference to a doc block is similar in form to how we reference a model in dbt but rather than using the ref macro we are relying on the doc macro.
We have covered the basics of adding a doc block - but you should also consider the best strategy of deploying these blocks. My preferred is to include a markdown file in the sub-directory where any 'new' fields are introduced and then any repeats just get a reference to the existing doc block. Consider a project:
my_dbt_project/
│
├── dbt_project.yml
│
├── models/
│ ├── marts/
│ │ ├── core/
│ │ └── reporting/
│ │
│ ├── staging/
│ │ ├── source_a/
│ │ │ └── source_a.md
│ │ └── source_b/
│ │ └── source_b.md
│ │
│ └── intermediate/
│ ├── my_intermediate_model.sql
│ └── my_intermediate_model.md
│
├── snapshots/
│
├── seeds/
│
├── macros/
│
├── tests/
│
├── analysis/
│
└── data/ The majority of meta-data documentation is going to occur in the staging sub-directory given that reflects where the source data is first processed in a dbt project. The intermediary model can then refer back to those existing doc blocks but it also has its own markdown for new fields that it derives from the source data (whether that be some sort of row-level calculation or a new aggregated measure).
Documenting SQL for Handover
Thus far, the majority of documentation has been angled at a governance and end-user perspective. You can use the above options to also document for fellow developers using model descriptions that outline the inputs used, the scope of the model, and the individual steps taken within the model. Nevertheless, for a developer there is also an opportunity to standardize SQL structure and annotate the queries directly to further enhance the speed at which work can be transferred.
dbt Labs encourages SQL queries to be constructed following a particular structure with 'import CTEs' at the start of the query effectively listing out where data is coming from in the model. Transformations are then done in CTEs with documented notes explaining what steps were taken with each one. They encourage that queries should end with select * from final with final being the last CTE with all transformations applied.
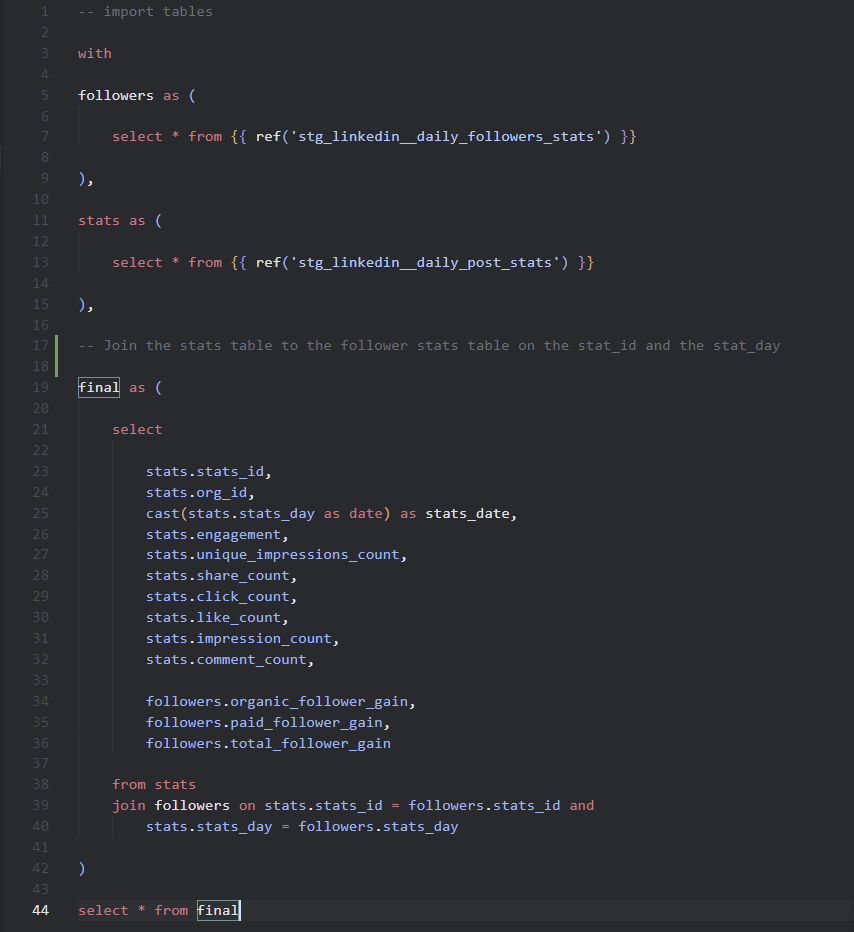
I decided to write this section because I think there are serious benefits to writing standardized SQL at an enterprise level - that is not to say that the dbt Labs method is the only way but I think the idea of making developers code in similar fashion is a key approach to minimizing downtime spent interpreting someone else's code. Ultimately, this section was added to encourage teams or enterprises to consider standard code practices and explore something like SQLFluff to automatically standardize SQL.
For those who want to add the documentation site to a GitHub Project
A final note for those working on personal projects who want to demonstrate their commitment to documentation with the auto-generated site. It can be added to your GitHub using GitHub Pages.
First take your project and make a new Git branch called gh-pages , on this branch you will want to track fields in the target directory. The target directory is usually ignored by default so use the -f flag to force that directory to track. All the git commands that were run are seen below:
# check what branch you are currently using
git branch
# start on main branch
git checkout main
# create a new branch with no commit history to bring through new files
git checkout --orphan gh-pages
# assuming you have already run 'dbt docs generate'
# force add the targets directory to the branch
git add -f target
# commit changes to the branch
git commit -m 'adding documentation site info to github' target
# Only push the target files to remote
git subtree push --prefix target origin gh-pages
# switch back to main
git checkout mainOn your repository navigate to the settings and select the pages pane. You want to deploy from the created gh-pages branch and select the root directory:
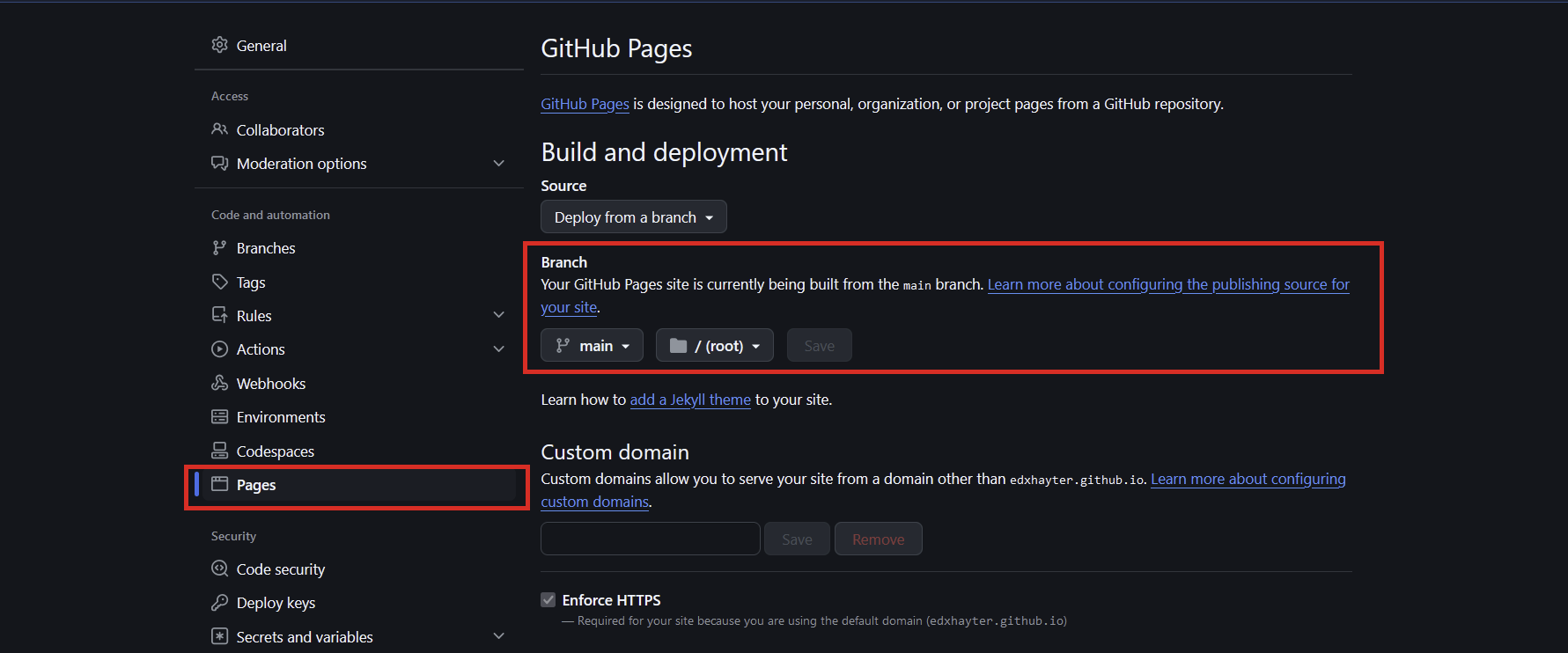
In the code pane select the settings in the About section highlighted in red below:

The link should take you to your documentation site!