


The following blog explains what dbt sources are, how they are configured including an exhaustive list of properties options with added notes on how they function and ending on why dbt sources are important and can provide value to a business.
What is a dbt Source
A dbt source is a central reference to raw data in your warehouse. A source is centrally defined in a .yml file and then can be called across multiple models using the {{ source() }} function. It makes sense here to distinguish between a dbt Source and the source function - as you'd expect they are closely linked but they are not the same. The source function is the means of using your dbt source in a dbt model.
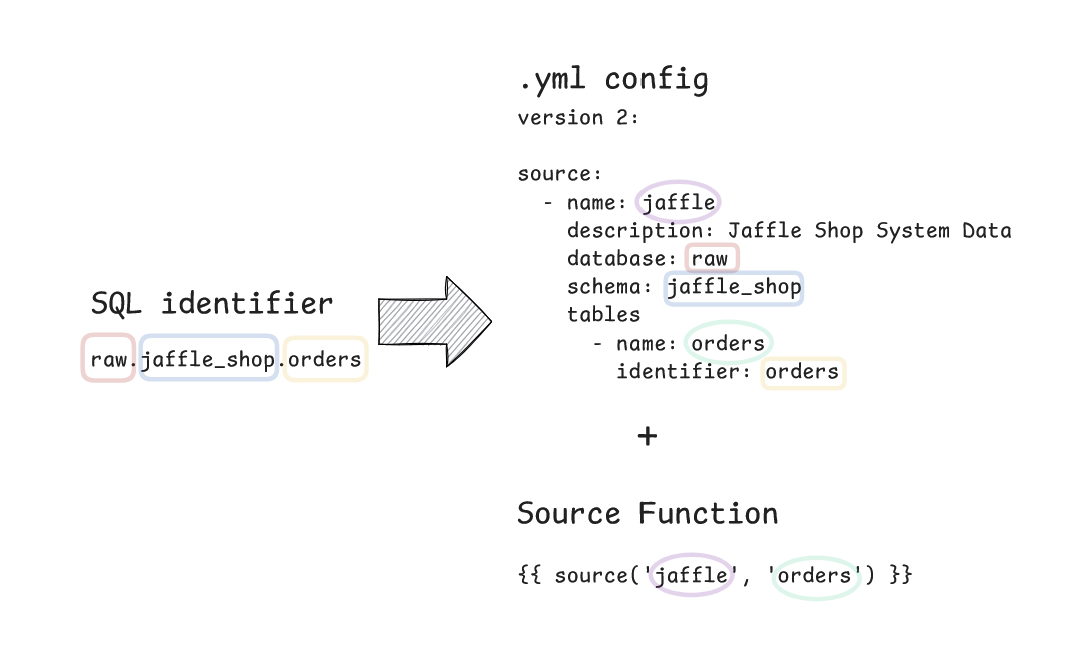
In turn this helps define the lineage of a dbt project where we would expect sources to be at the root of our DAG at the highest point upstream.
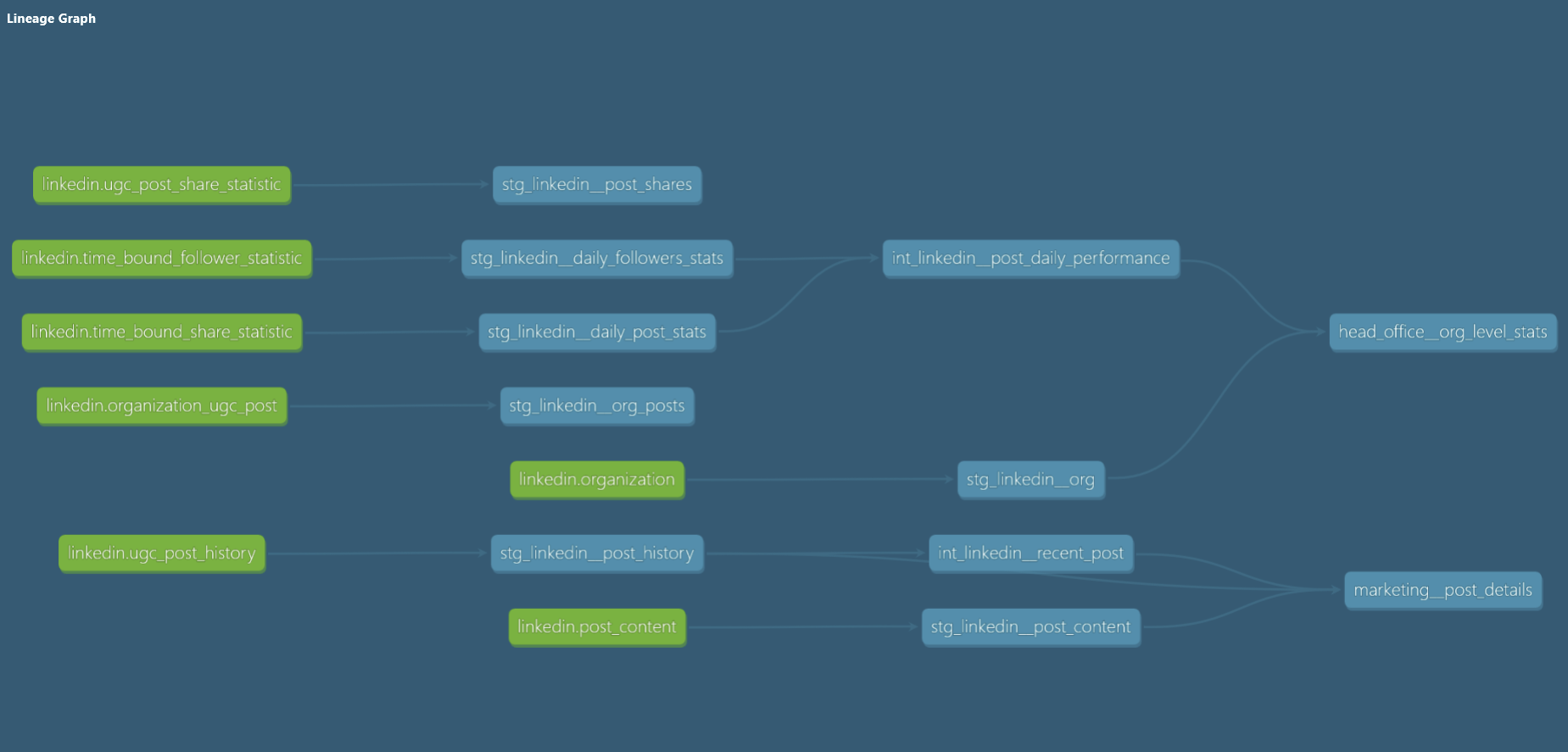
A dbt source differs from a dbt model, appearing in the above DAG in green, these are just the connections to the data that the dbt project will be built upon so that you can see what the dbt Project is using to build its models, the sources are not built or rebuilt in the database each run like a model is. Nevertheless, you might structure your project to have source or staging models that will use the source function to bring that data in. When the dbt Project compiles and determines order of execution it knows to start with models with a source function first before then running models in order of their dependencies as specified within ref functions.
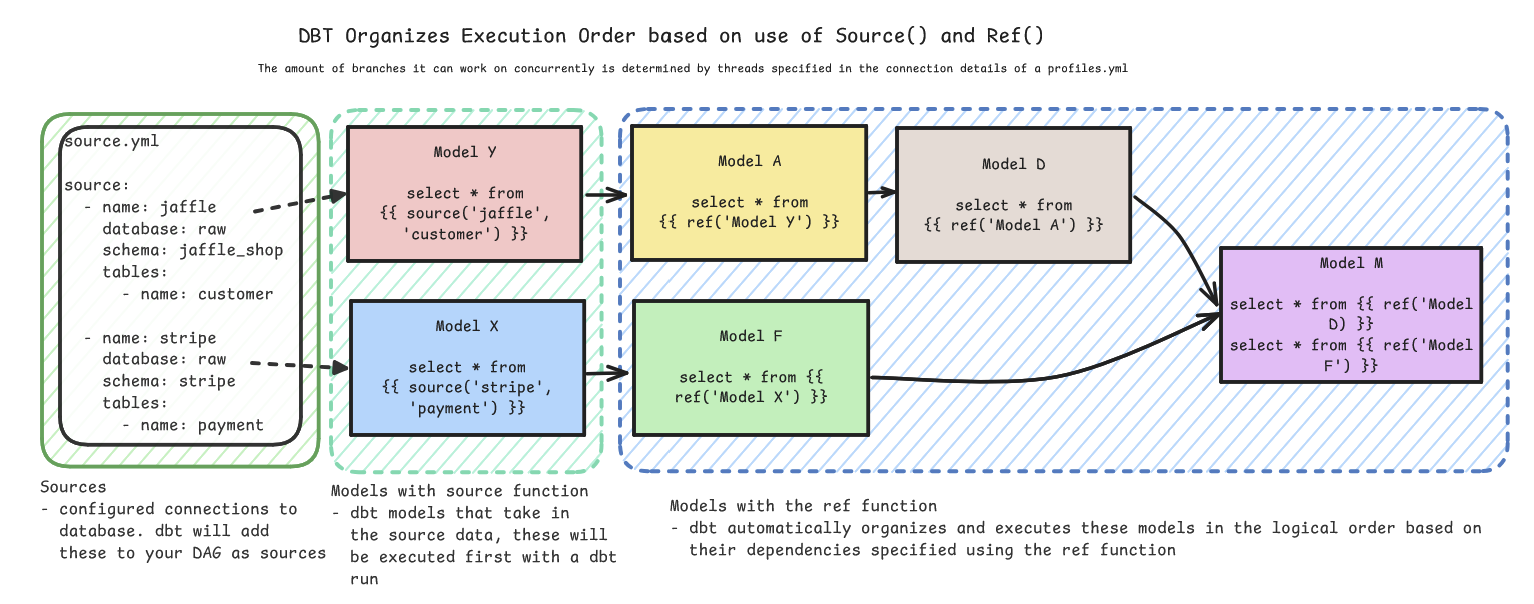
How do I use a dbt source?
Sources are configured in the dbt_project.yml or in a .yml file within the models/ directory and can be nested within however many subdirectories you would like.

Briefly discussing configuring sources in dbt_project.yml, I think configuring all sources here can make the project.yml convoluted and mixing source systems also can get messy. The only sources I would consider configuring here are sources that are imported as part of a package in line with dbt Labs recommendation.
dbt Labs recommends structuring a project with models split into intermediate, marts and staging. Within staging, they recommend a subdirectory for each system and then the staging takes place within these subdirectories. In this setup you would likely want a sources.yml file for each directory within each of those subdirectories.
There is no one correct way of structuring a project, I quite like the idea of having a specific subdirectory for sources and within that subdirectory having a subdirectory per system then I mirror the dbt Labs approach with a sources.yml for each source system but rather than staging models I like having a source model that brings the source data in with the {{ source() }} function.
Again there is no right or wrong approach and context will likely determine the correct approach. In any case the next questions with sources likely relate to what goes in the sources.yml file. Below is an example with all possible properties for a source specified as of the time of writing. Throughout the example I add commented notes following '#' and you can do the same in your dbt project if you intend to leave notes for a future developer.
I might call this file source_google_analytics.yml:
(.yml files use 2 spaces for indentation and list items are indented)
version: 2
sources:
- name: google_analytics
# names the source that appears {{ source(<here>, table) }}
description: >
I might add here the project and schema this sits in in big query,
perhaps some information on what websites this google_analytics
was tracking
# the '>' indicates multiline description above
database: raw
# if we think of a manual reference to a database object
# database.schema.table, the next 3 populate those variables.
schema: google_analytics
loader: Fivetran
# above serves as extra documentation to say how the data was loaded in
loaded_at_field: loaded_timestamp
# this could be specified at the system level if they are all being loaded
# the same way with the same field added for a load time or it can be
# specified table to table
meta:
# add any further meta data in key value pair form
owner: "ed"
# this will appear under the meta field in the docs rather than
# the top-level owner field of docs (this is taken from the database)
sunset_date: 2025-12-31
tags: sources
# these are hierarchical tags so all the source tables will have this tag,
# we could use the tag to run tests only on sources
# with `dbt test --select tag:sources`
config:
enabled: true
# if a source is sunsetted we might want to disable the source with
# false here
event_time: event_timestamp
# rather than a loaded at time this refers to the timestamp where the
# data event occurred, like the loaded at this can be set more
# specifically at the table level if it varies.
overrides: <string>
# specify a source in a package here you want to override, so that a
# package starts using this source instead
freshness:
# these blocks test the freshness of the source data with a dbt source
# freshness command, they are hierarchical so freshness blocks set at the
# table level below take priority over a freshness block setup configured
# at the source level
warn_after:
count: 12 # set the magnitude
period: hour # could also go with minute or day here
error_after:
# if you run dbt source freshness command as a step in a job this
# failing will stop subsequent steps from running. If you tick the
# checkbox when making a job this source freshness will error but not
# stop subsequent steps in the job.
count: <positive_integer>
period: minute | hour | day
filter: <where-condition>
# freshness checks do a full table scan, so for performance reasons you
# might consider a where clause here to restrict the data that is
# checked.
# The loaded_at field was specified higher up and will be used for
# this freshness check
quoting:
database: true | false
# Most adapters it is set to true by default except Snowflake
schema: true | false
# with quoting you can use reserved words and special characters
# (although this should be avoided generally) and makes the relation
# case sensitive.
identifier: true | false
tables:
# now we can set configurations and settings at the table level, note each
# new entry in the list starts with a '-' and then the key value pairs
# begin at the same level of indentation, note we can override the source
# defaults at the table level (these properties are hierarchical with the
# most specific taking priority.
- name: views
# if you introduce a table, a table name is a required property
description: video views as logged by Google Analytics
meta: {<dictionary>} # meta is a config that does not inherit
identifier: ga4_views
# use the identifer if the table name in database is different to what you want to call it in the source macro.
loaded_at_field: loaded_at_ts
# we can overwrite source defaults here and this will be used in
# the freshness test for this table
tests:
# note here that tests introduces a list of tests at the next level of
# indentation.
- <test>
# these are tests carried out at a table level so not column level
# tests (tests at this level often have a required entry for a
# column(s) to use
- ... # declare additional tests
tags: [<string>]
# tags accumulate hierarchically so this table should inherit the tags
# from the source
freshness:
warn_after:
count: <positive_integer>
period: minute | hour | day
error_after:
count: <positive_integer>
period: minute | hour | day
filter: <where-condition>
quoting:
database: true | false
schema: true | false
identifier: true | false
external: {<dictionary>}
columns:
# we can get even more detailed to the column level
- name: view_id
# required if you add a column entry it will need a name property
# as a minimum requirement.
description: >
Unique identifier for each view in the table.
# here we might use doc blocks (which I discussed in another blog
# on documentation) to centralize descriptions
meta: {<dictionary>}
quote: true | false
tests:
- unique
- not_null # fairly standard checks for a primary key
- ... # declare additional tests
tags: [<string>]
- name: ... # declare properties of additional columns
- name: ... # declare properties of additional source tables
- name: ... # declare properties of additional sources, in this instance as we are having a source.yml file for each system I would not specify another source in this .yml to avoid cluttering it.
Why use dbt sources?
Using dbt sources has many benefits, as mentioned above the central reference to a source means that updating a source can be done in one place and any reference to that source will be updated, perhaps the system remains the same but the `ga4_views` identifier needs to be updated to `views_ga4` due to an ingestion team change - imagine having to update that across countless procedures (some of which the business might not be fully aware exist), compared with updating a `.yml` file and the dependencies on the `.yml` all automatically updating. In a situation of a source system change, central staging logic could be pointed at the new source, any logic required to transform the new system data into what was in place before can be made whilst leaving the downstream code logic in place.
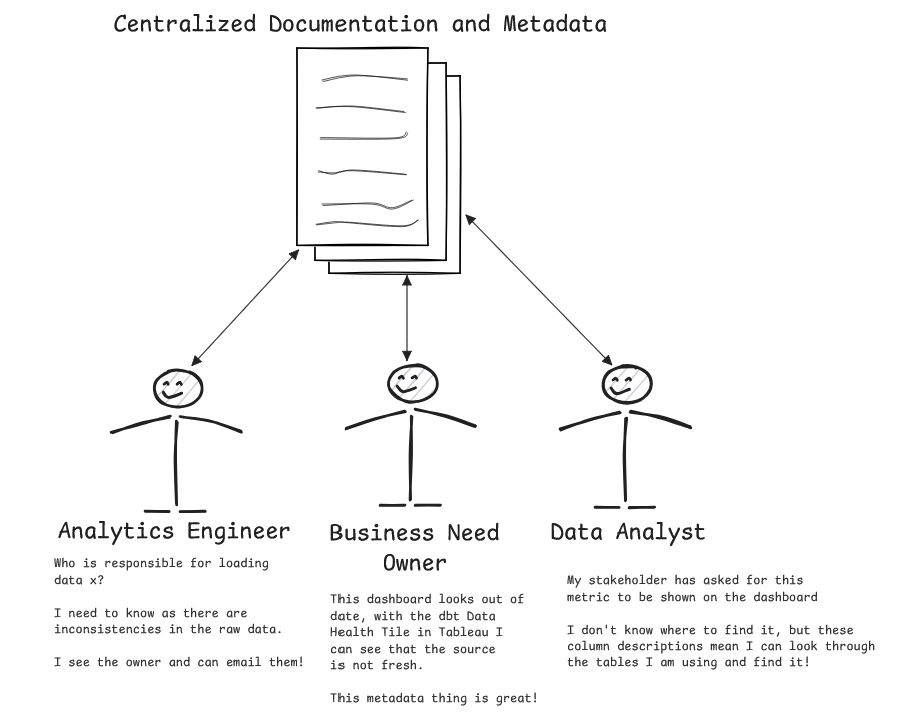
Clear centralized metadata like a contact for issues with a system or source table can avoid a situation where information is scattered throughout the business and facilitate faster incident resolution. Adding something like a sunset date for a system makes it clear across the business of upcoming risks in terms of source data supply. This central source of documentation and metadata can be incredibly powerful when so readily available.
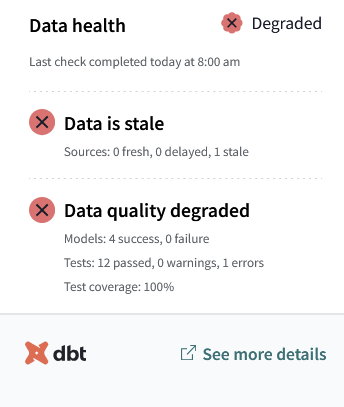
Using dbt sources also opens up the capacity to leverage source specific configurations. In particular source freshness is a feature that can be leveraged when using dbt sources. Not only will warnings (or errors) be raised when running a dbt jobs with stale data, but you can also use a feature like a dbt Data Health Tile on a Tableau Dashboard to communicate to end users when analytics products are returning outdated data.
Concluding Remarks
We have covered a lot of ground in this blog. The annotated .yml file is fairly exhaustive. The more metadata you put in, the more you can get out of it. I would recommend using it as a reference for all the things you can do and how you could go about it - build out the basics of the file first with the source and table options. Generally, source level specifications can clutter the file unless that information will be consistent across all tables like a default loaded_at timestamp. The same applies with information at the column level. You can also make these files less cluttered by leveraging doc blocks to abstract markdown strings into a separate file and refer to them across multiple places. Read more about that here.