For SQL users venturing into dbt, writing models often feels intuitive. However, other aspects—like mastering dbt's Jinja macros and using the dbt Command Line Interface (CLI) effectively—can present a steeper learning curve. This guide aims to introduce dbt’s CLI, explaining its role in managing data projects, providing setup tips, and offering principles to maximize its impact.
What is the CLI? Where Can I Find It?
A Command Line Interface (CLI) is a text-based interface allowing users to communicate with software via commands rather than a graphical user interface. For example, using ls in a terminal lists all files and folders in the current directory—just as navigating through a file explorer does visually, but through text commands.
With dbt Core, the CLI is crucial during setup. Many users will have already encountered it when installing Python, adding dbt packages, or creating virtual environments. The dbt CLI configuration begins with installing dbt Core and relevant database connectors, followed by initializing a dbt project with dbt init. For dbt Core users, this means all configurations and project management occur through a preferred terminal on their local machine.
In dbt Cloud, there is a Cloud Console where commands can be entered along with some interface buttons that allow for the running of particular commands without typing them. dbt Cloud users can still set up a CLI for local development, running commands in a local terminal that sync with dbt Cloud.
Installing the Power User for dbt Core and dbt Cloud Extension can enhance productivity. This extension offers additional functionality, like viewing data lineage and previewing data.
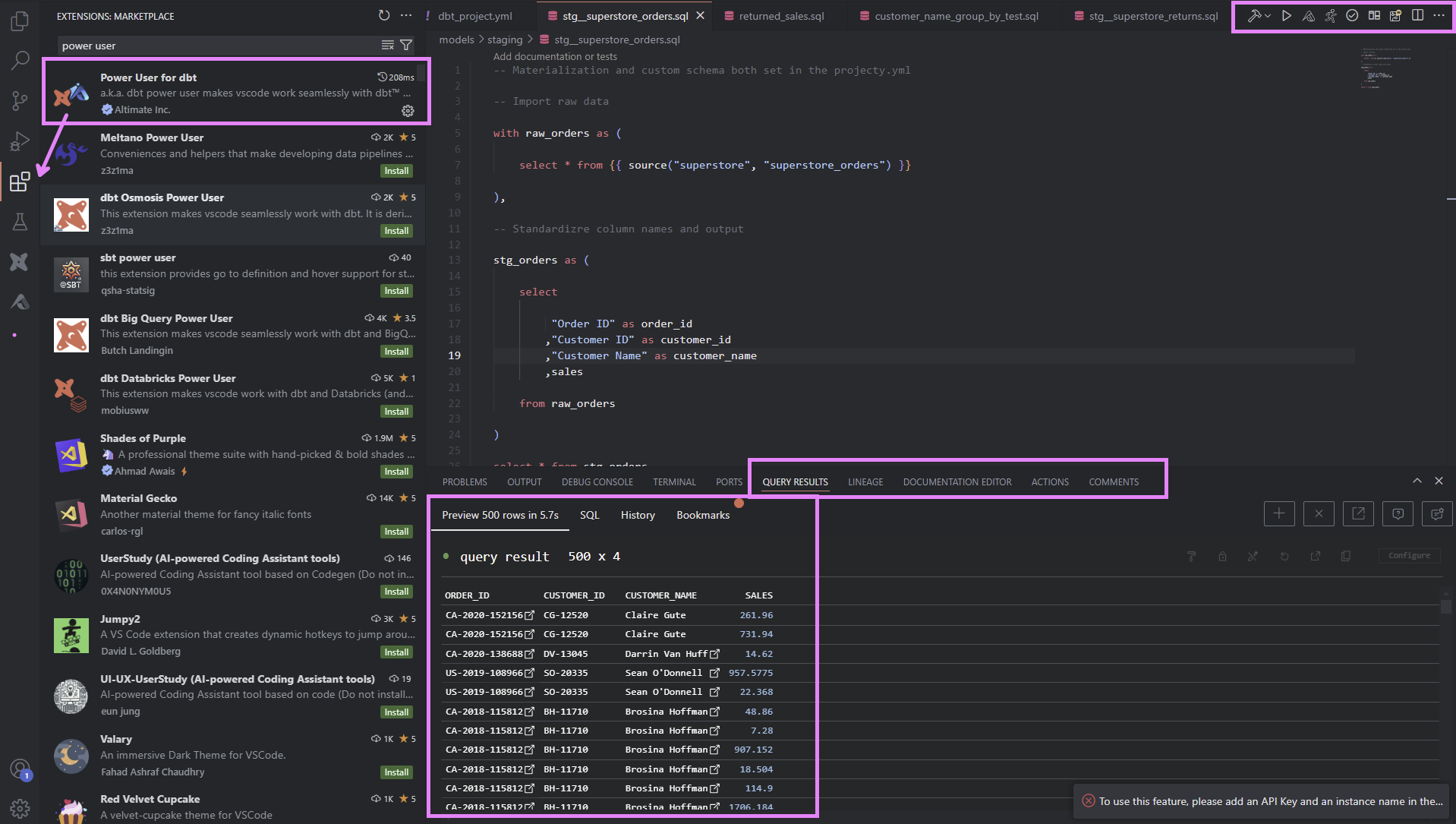
The CLI commands, whether executed from dbt Cloud Console or a local terminal, are typically used to run, build, and test models during development and to configure jobs for production environments. Below, I explore techniques for optimizing CLI usage to keep warehouse resources manageable.
Using the CLI to Reduce Warehouse Load
Commands like dbt run or dbt build are commonly used to run all models in a project, ensuring consistency across the entire dataset. This approach guarantees that no model is left unbuilt, and all data is up-to-date. Additionally, by executing a single command, developers reduce the risk of inadvertently building models multiple times, which could otherwise result in data inconsistencies.
However, running the entire project is resource-intensive. For complex, mature dbt deployments, with large Directed Acyclic Graphs (DAGs) that maintain many critical business-layer tables, this can drive up data warehouse costs unnecessarily. Instead, developers can optimize commands to selectively target specific models or portions of a project, reducing load while preserving essential data processes.
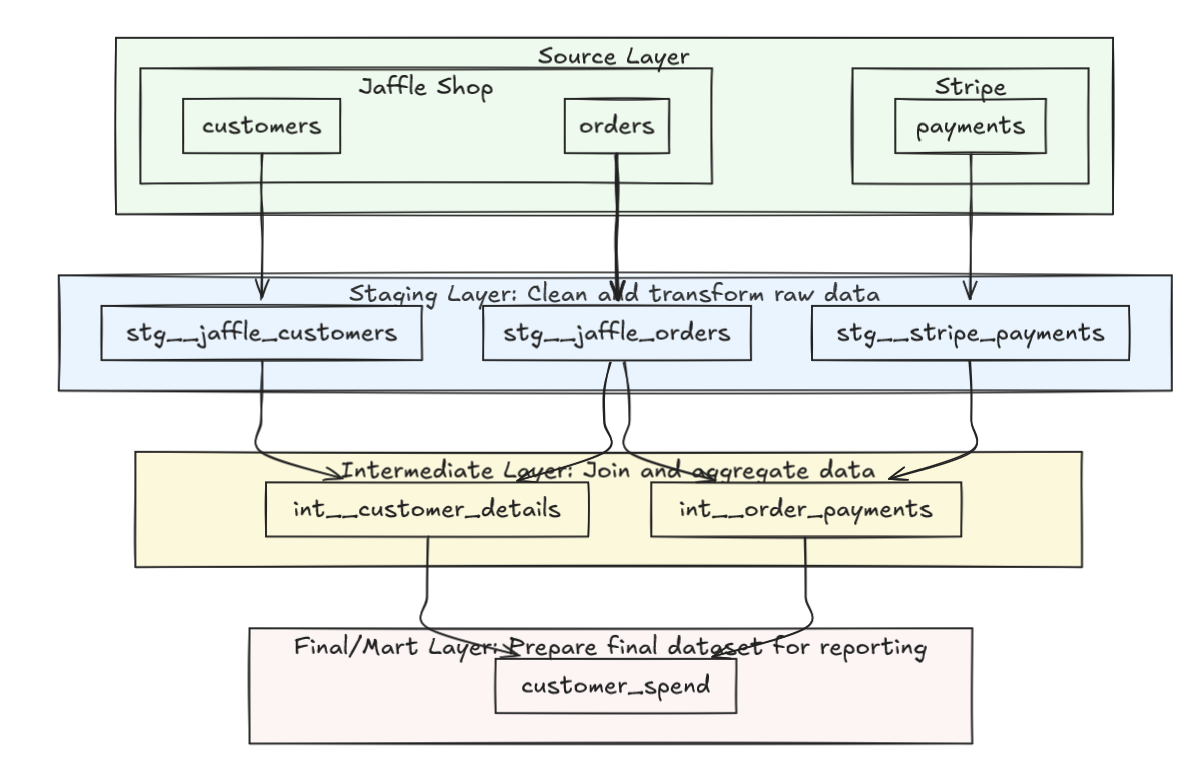
Advanced CLI Techniques for Targeted Model Runs
To optimize dbt commands, I recommend using selectors, upstream/downstream quantifiers, and tags to run only the required portions of a project. Here’s a look at these strategies in action.
Using Selectors and Quantifiers
For instance, instead of running every model in the project with dbt run, I can use + to specify dependencies. This allows running only a segment of the project that either feeds into or is dependent on a specific model, reducing unnecessary resource use.
- Downstream: If I want to build only a specific model and its dependents, I can use
dbt run --select model_name+. This runs the model and all downstream models that are dependent on it. - Upstream:
dbt run --select +model_nameruns the selected model along with all models upstream that it is dependent on. - Quantifying: If we want even greater control and simply want to run a particular model and any models that are direct children of it, I would write
dbt run --select model_name+1
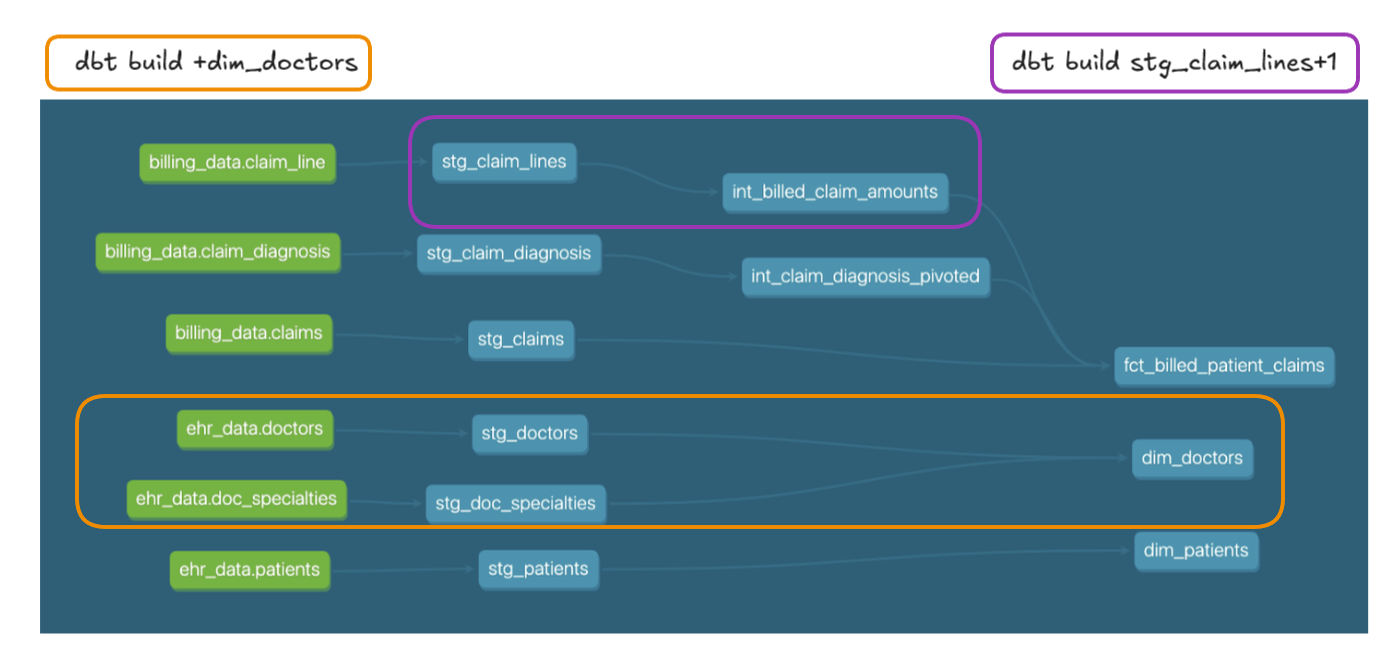
| Operator | Meaning Definition |
|---|---|
| model+ | The model selected and all models downstream of it |
| +model | The model selected and all models upstream of it |
| n-plus |
The model selected and models 'n' nodes upstream/downstream of it. E.g., 1+model would be the model selected and its direct upstream parent;
model+3 would include the model and its descendants three connections on—i.e., children, grandchildren, and great-grandchildren
|
| @ | The model selected, all its descendants, and all the ancestors of its descendants |
Set Operators to Consolidate Commands
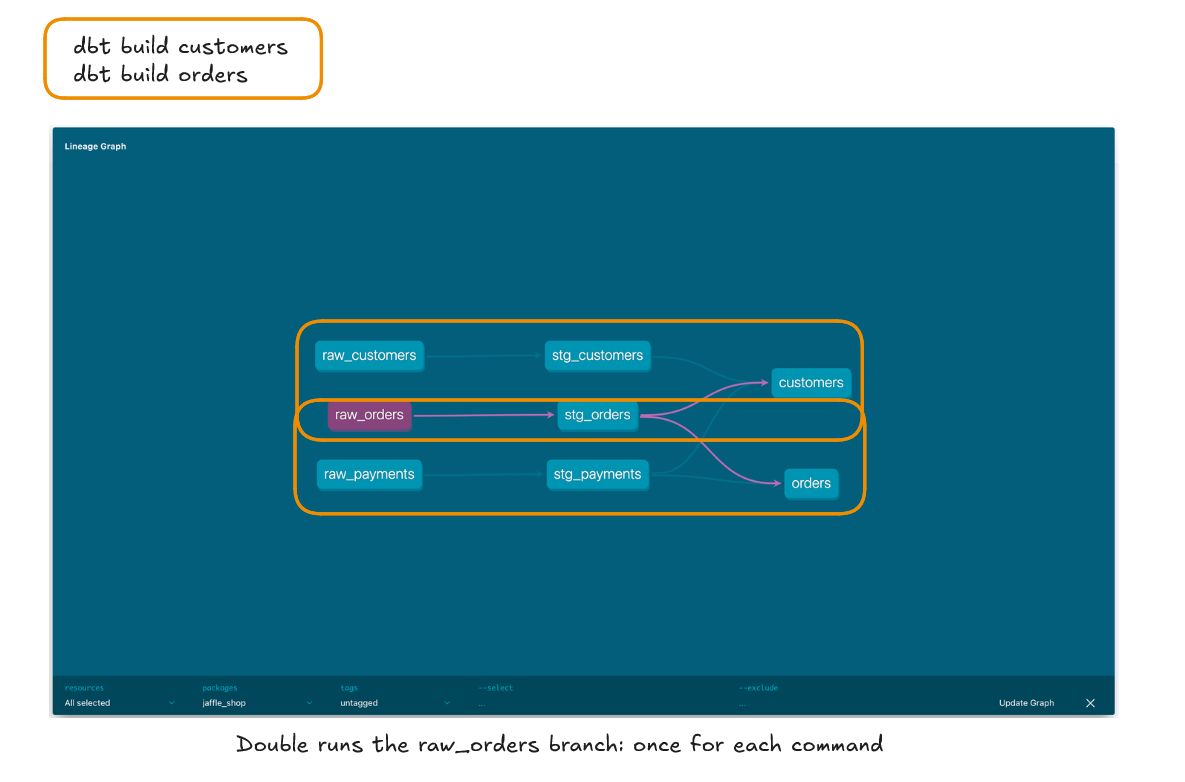
Another useful CLI strategy is combining multiple commands into a single, efficient one, avoiding double-running models. This is particularly valuable in production jobs, where multiple dbt build or dbt run commands can inadvertently run the same model more than once if not carefully reviewed. By consolidating commands with set operators, I can streamline jobs, avoid redundancy and minimize the chance of data mismatch that might occur from running the same table twice after fresh data is added.
For instance, using a Union Operator (space-delineated arguments following a select or exclude flag) allows any dbt resource (model, test, exposure, etc.) that meets at least one selection criteria to be included in a single run. This approach eliminates the risk of duplicate runs.
dbt build --select +model_a +model_b uses a union operator and says to run all models upstream of both model_a and model_b if any model is needed for both it is consolidated by the union operator and only run once.
In comparison, running a job with the following commands is to be avoided:
dbt build --select +model_a
dbt build --select +model_bThis is because these two commands will operate in sequence and therefore model_c which is required for both will be rebuilt twice. If there is new data streamed into source between the two commands and processed then model_b's data will not reconcile with model_a which was run on outdated data.
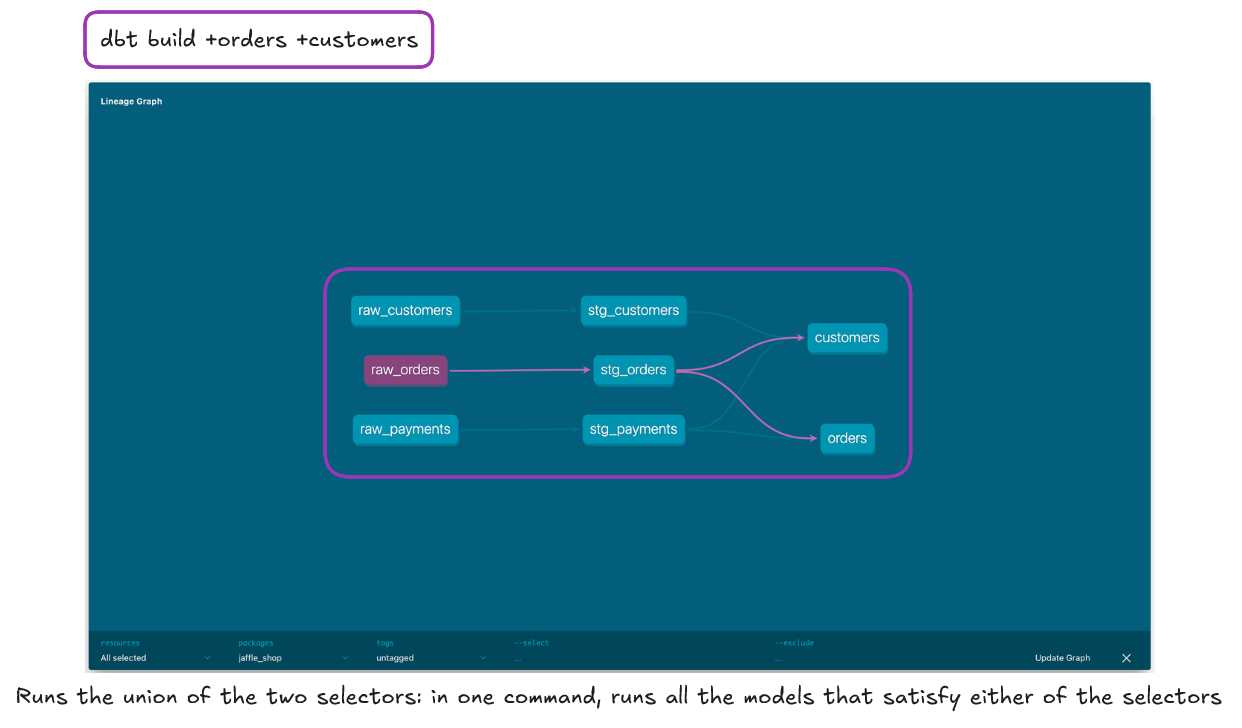
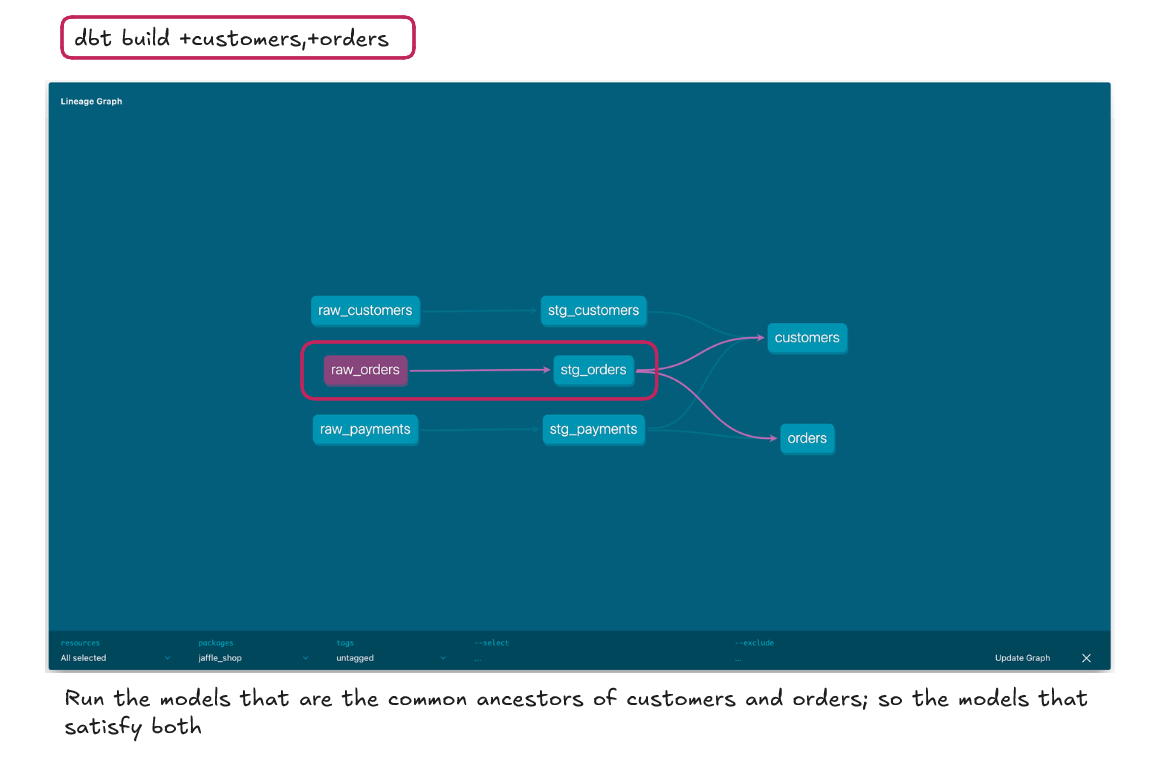
Other useful operators to be aware of include the Intersect Operator (comma separated no space). This operator applies the command to dbt objects that satisfy all the individual conditions. So below we are asking dbt to run the customer model and those upstream of it along with the orders model and its upstream models. Neither the customers nor the orders model satisfy the other command so are not run whereas raw_orders and stg_orders do satisfy both commands and are therefore run.
State Selection: Target Only Modified Models
State selection is another effective way to reduce unnecessary workloads on the data warehouse. With state selectors, I can run only models that have changed since the last build by comparing the current project state with a saved artifact.
For example:
dbt run --select state:modified+ --defer --state path/to/prod/artifacts
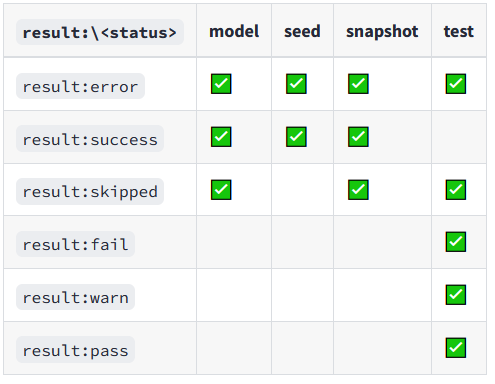
In this command, dbt will run only models that have changed. I can further refine this by specifying further states to include only models that have been modified and also error-ed in the previous run, allowing for precise debugging.
dbt run --select state:modified+ result:error+ --defer --state path/to/prod/artifactsIt is worth remembering that an error-ed state is distinct from a failed state. For example a dbt test can simply fail unless it is configured in .yml to have an error condition (although a failed test will still halt a workflow it would not be picked up with the error state selector).
Tag Selection for Structured Workflows
Tags in dbt help streamline complex commands by grouping related models, tests, or exposures. Applying tags can simplify workflows and allow for targeted builds without long, complex exclusion and intersection queries.
For example:
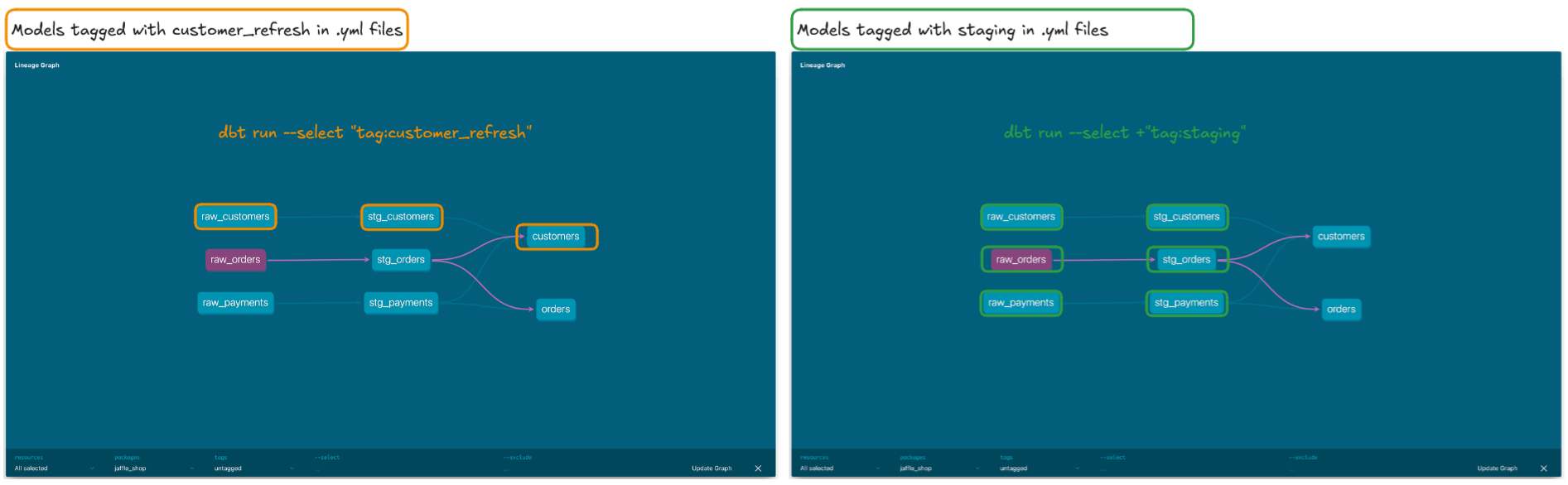
dbt run --select "tag:customer_refresh"
This command will run only the models tagged with customer_refresh, avoiding the need for detailed model-by-model selection. Tags are defined in .yml files and can be organized by directory or business function, which keeps projects manageable and helps maintain an organized, consistent approach.
Considering 'Fast Failure' in dbt CLI
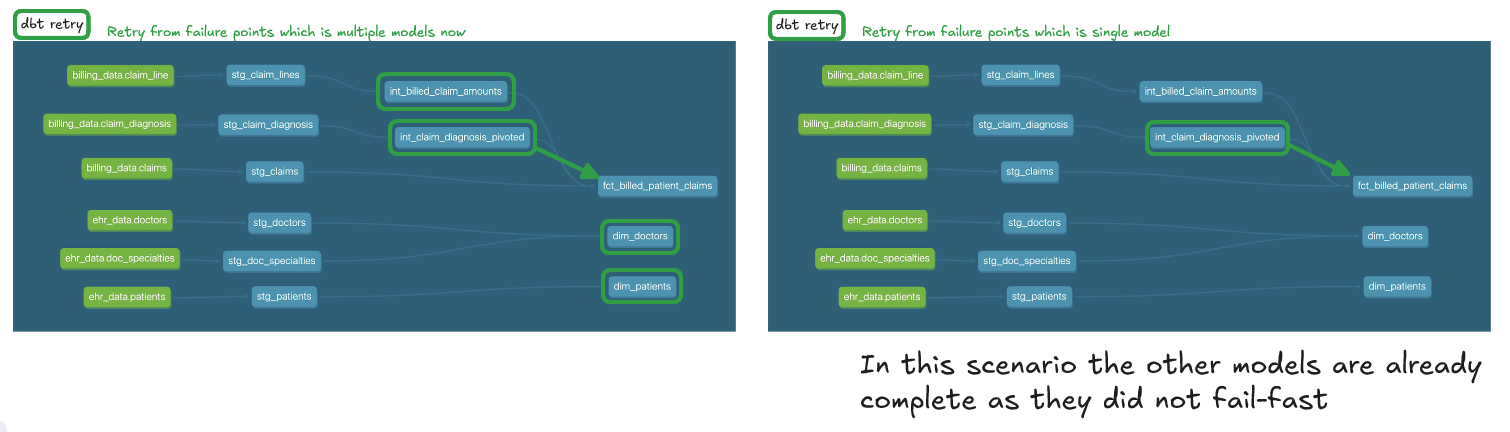
The concept of "fast failure" is a common strategy for identifying and addressing errors early in a process. In dbt, fast failure refers to the CLI’s --fail-fast (or -x) flag, which stops execution immediately if any model fails to build. This approach isolates errors and preventing further models being built across the project if there is an issue with one model, avoiding the creation of cascading issues.
For example, running dbt run --fail-fast will terminate the run at the first error encountered, suspending all remaining threads in progress. This is very useful for jobs where if one data test fails you no longer want to surface any data and therefore the compute used to run other threads to completion is wasteful and unecessary.
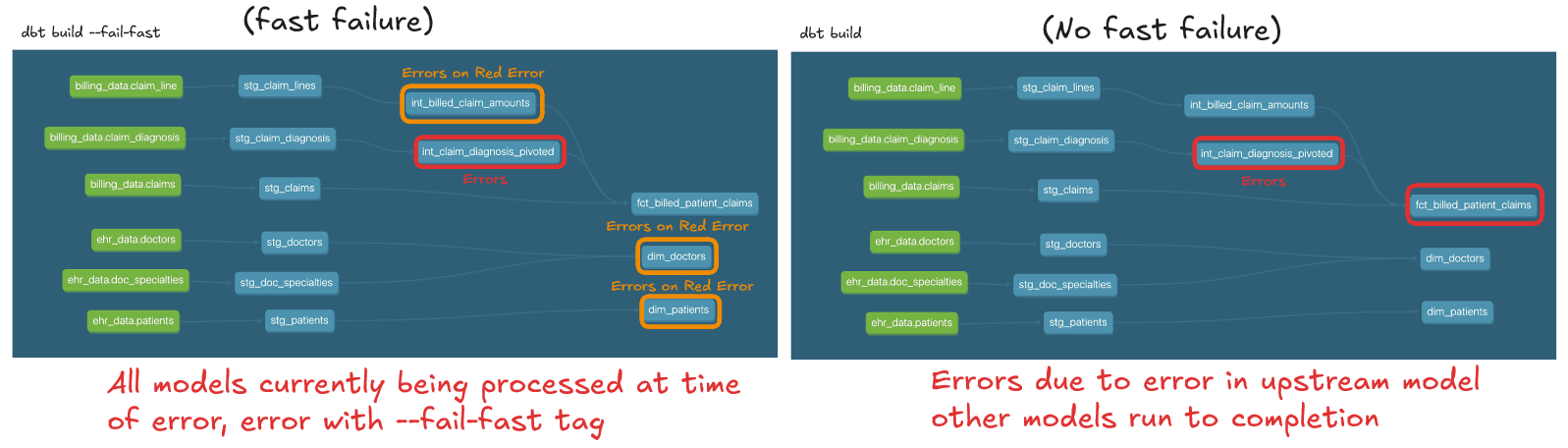
It is worth bearing in mind how a fast failure might impact subsequent dbt retry commands or stateful selection on model:error.