


Another day another gander around foundational dbt functionality... today I was checking out sources, tests, and documentation. Read on for a synopsis of all three! If you would like to have a go yourself the free course can be found here: https://learn.getdbt.com/learn/course/dbt-fundamentals/documentation-30min/documentation-basics?page=8
Sources
In my last blog I wrote a little about different models and how they sit relative to each other. Int (intermediate models) are found 'downstream' from Stg (staging models), this is because the Int models are built from the Stg models and the latter needs to be constructed first. What sits upstream from the Stg models?
This 'can' simply be a reference to an explicit table name utilising SQL selection: database.schema.table_name. However, hardcoded table names require the developer to update every reference manually if the raw table changes. Enter dbt Sources: these allow you to define the database/schema/table name of your raw data within dbt, and then reference this source downstream, not the raw data. Now if the raw data location changes, you need only update the source definition!
Tests
Tests are vital to ensure that our code is doing exactly what we expect it to. dbt allows us to write these tests as SQL SELECT statements, that we then run against our models. Tests are split into two main categories:
1) Generic Tests: these are written in the yml file of your schema. They validate common data quality rules like uniqueness, or accepted values:
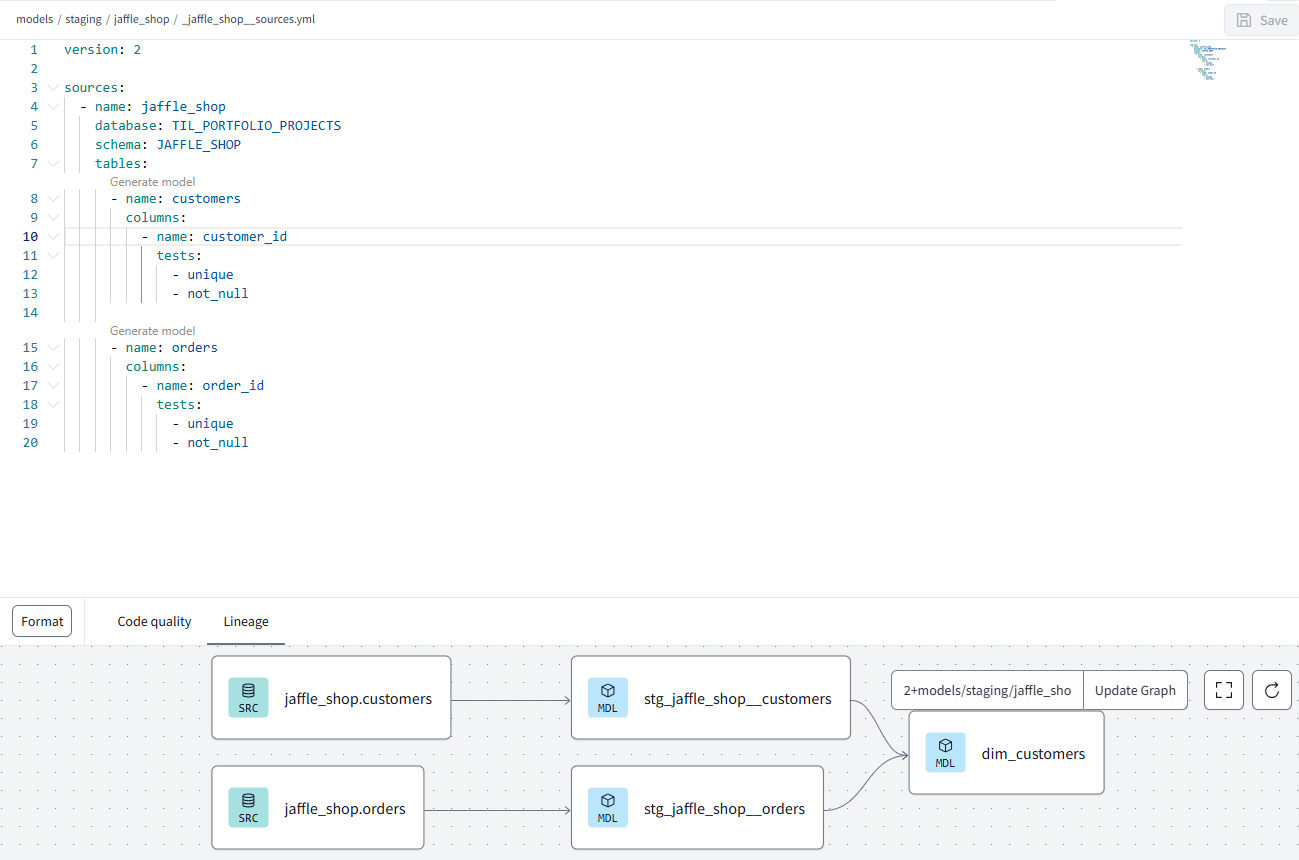
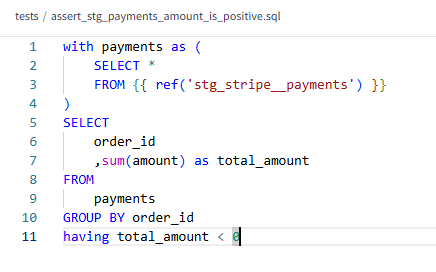
2) Singular Tests: these are written in the tests directory of your project, and return records that fail test conditions. Singular tests are handy for specialised data quality checks that cannot be generalised/reused across models:
Documentation
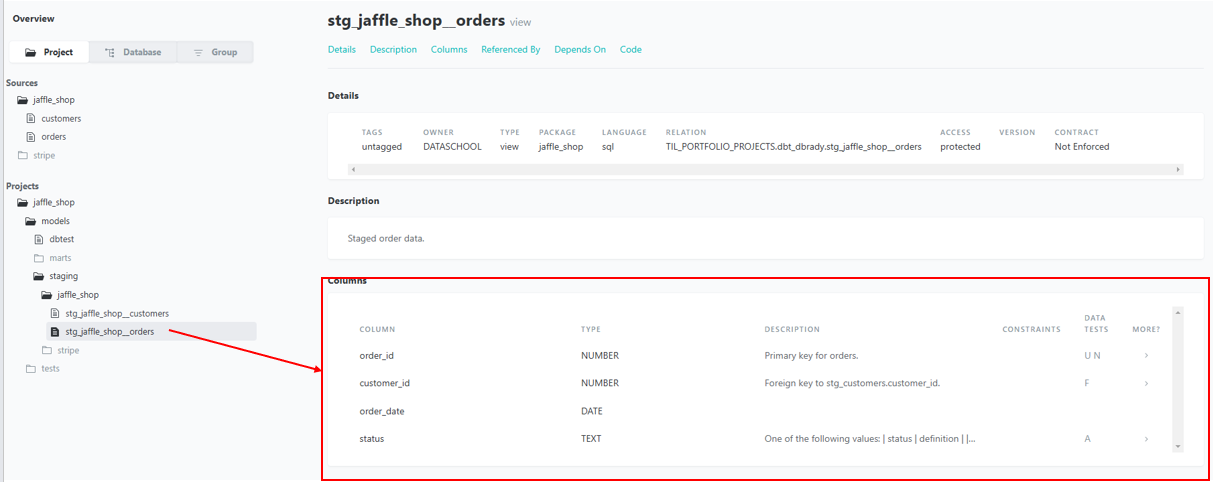
Although essential for a team's success, solid documentation is often given lower priority than the data it describes. dbt aims to make it as easy as possible for documentation to keep up with development by embedding it within your yml files - the same place you write your generic tests. Take a look at the following:
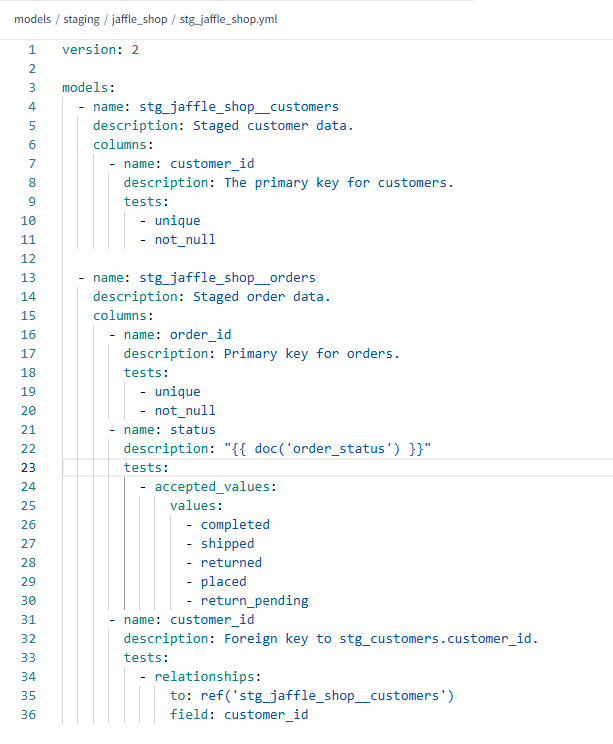
You simply add a description after any field you fancy describing! (Which really ought to be all...). The one curve ball here is located in the description of the status field, which, for readability, is referencing a seperate documentation file.
Once happy with your documentation use the command dbt docs generate and navigate to this button at the top of the page:
then navigate to your table of interest and witness all of your glorious documentation, embedded within your dbt:
It is becoming clear to me that the true power of dbt lies in its modular approach, which makes workflows easy to understand, maintain, and scale. It is an invaluable tool for complex projects, especially when working with a large number of tables, intricate transformations, and within a team where work overlaps.