


This week marks my first foray into the wonderful world of dbt. In this blog I'll give a brief background on the tool, before walking you through my initial experience!
So... what is it?
dbt (data build tool) is a powerful solution that enables data analysts to take on data engineering tasks, allowing them to transform data within the warehouse using simple SQL SELECT statements. This makes it easier to address transformation needs directly with code.
Traditionally, data teams consist of analysts and engineers. Engineers are responsible for building infrastructure and managing the ETL (Extract, Transform, Load) process, using programming skills in SQL, Python, Java, and other languages. Analysts, meanwhile, work closely with business stakeholders to uncover actionable insights and inform decision-making. This separation of roles can lead to inefficiencies, with analysts waiting for engineers to implement or update ETL pipelines. This is where dbt proves invaluable: allowing analysts to write modular, reusable SQL scripts to transform raw data directly in the data warehouse.
By eliminating the need for complex ETL pipelines managed by engineers, dbt enables an ELT (Extract, Load, Transform) approach. Data is first loaded into the warehouse in its raw form and then transformed within the warehouse itself. The results are streamlined workflows, reduced turnaround time for insights, and less reliance on specialised engineering skills.
My Initial Look:
For my first look at this new tool, I have been checking out this fundamentals course: https://learn.getdbt.com/courses/dbt-fundamentals. Here I began learning about some key concepts in dbt: Models, Stages, and Dependencies.
Models: these are the building blocks of dbt projects. They are SQL files, defining the transformations to occur within the data warehouse, the output of which is a table or a view in the warehouse.
Stages: these are models, but defining them as stages create a necessary separation between types of transformations, ensuring logical dependencies between models (staging models must run before the latter models that depend on their output).
My First Transformations:
Having connected my dbt to Snowflake, I was able to use SQL statements in dbt to directly manipulate and transform the data in Snowflake. The data in question was related to 'Jaffle Shop', a fictional store with a customers table and an orders table.
Firstly I constructed my 'Stages'. For all intents and purposes in this exercise, these act as a CTE, but with the benefits of being reusable (rather than limited to a single query, dbt stages can be reused across multiple models), easily documented (as they are defined as models they can be documented as necessarily, vital for large projects), and they enable clear dependencies between transformations. If you build a model out of stages, the stages will be built first.
Here is my first stage model:
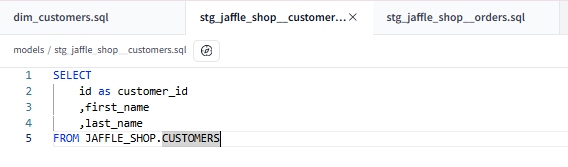
a simple select statement, choosing just three fields and renaming one of them for clarity.
And here is my second:
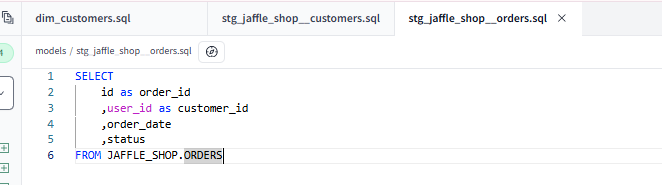
doing much the same!
Having saved these stages (recognised by the 'stg_' prefix on the sql file names) I could reference these in my main query:
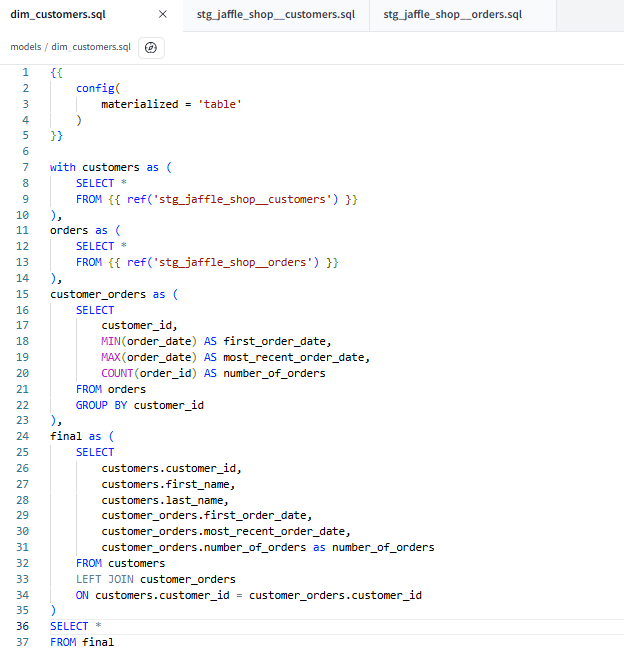
This will allow me to generate a new table, that I can use to analyse earliest, latest, and the total count of customer orders! With the dbt run command I can build the table in the Snowflake warehouse:
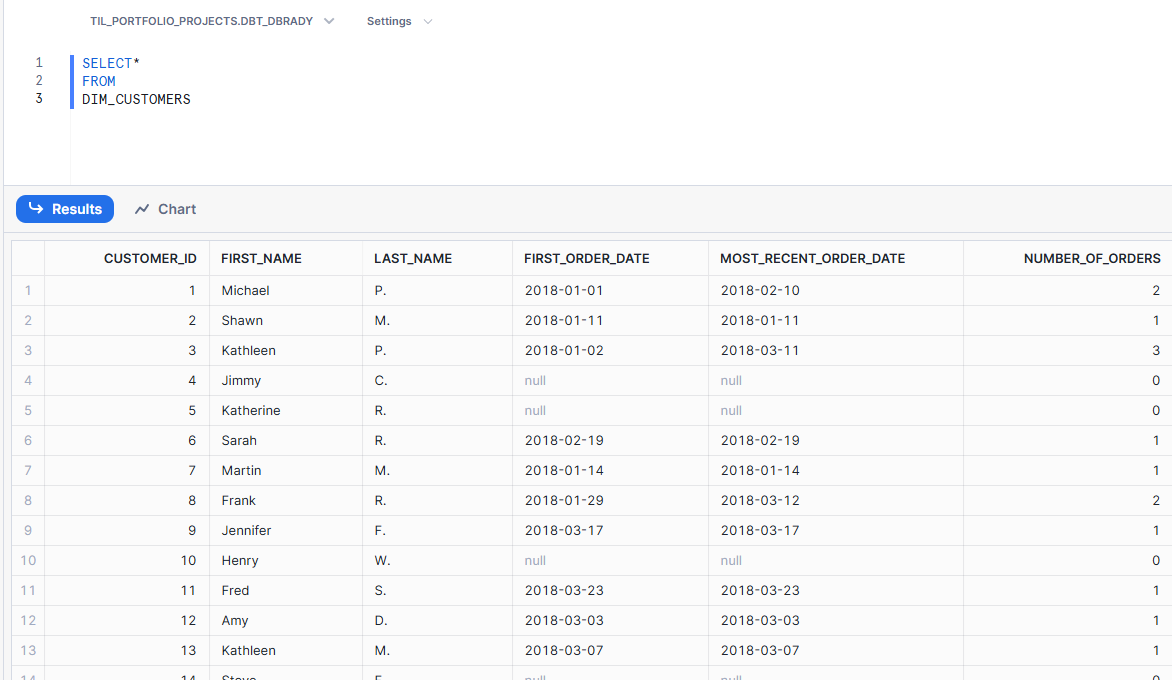
Which I can now access with my BI tool of choice for some juicy analysis!
Needless to say, this was just day one, and I have much more to learn about the true power of dbt. For the experiment above, there was little value added by the tool; indeed, there was no real reason not to just create the table directly in Snowflake. However, from what I understand, dbt’s real potential becomes clear in larger projects, where documentation and version control are crucial. In such environments, dbt offers structure, scalability, and collaboration features that can make it an indispensable tool for managing complex pipelines.