Data architecture is a term used to cover both the policies, rules, standards, and models that govern data collection and how data is stored, managed, processed and used within an organization. It sets the blueprint for data and the way it flows through data storage systems. The design of a data architecture should be driven by business requirements, which data architects and data engineers use to define the respective data model and underlying data structures, which support it. These designs typically facilitate a business need. As new data sources emerge through emerging technologies, a good data architecture ensures that data is manageable and useful, supporting data lifecycle management. A few key data architecture principles have been developed for today’s data-driven marketplace:
Consider data a shared resource - Eliminating regional, business unit, and department data silos to ensure organization stakeholders can access the data they need to drive insights and receive a full view of the business.
Ensure security control access - Data platforms such as Snowflake allow governance and access controls at the raw data level, eliminating ad-hoc security further down the line. With today's demand for widely available real-time data, highly secure self-service access is increasingly necessary.
Reduce or eliminate data movement and replication - Any time data is moved or copied, precious time and resources are consumed and data fidelity (the accuracy with which data quantifies and embodies the characteristics of the source) is potentially compromised. Modern data platforms require MPP (massively parallel processing) to support multi-workload, multi-structure environments. They also need to support high user concurrency across disparate units and/or geographies. The only way to achieve this is through a cloud data platform that can leverage economies of scale to meet fluctuating business workload requirements.
Data architecture touches upon many roles in an organization. At the top of the pyramid is the data architect, who maps the entire data ecosystem against business requirements and is ultimately responsible for the execution of defined data architecture principles. Further downstream, in the day-to-day data workflow, sits the data engineer, who is responsible for data pipeline and ingestion management, as well as data quality control. At the consumption end of the data lifecycle sits both data analysts, who manage data feeds and build reports for data stakeholders in the business, and the data scientist, who mines data to drive business insights.
Types of Data Management Systems
A data architecture demonstrates a high-level perspective of how different data management systems work together. These are inclusive of a number of different data storage repositories, such as data lakes, data warehouses, data marts, and databases.
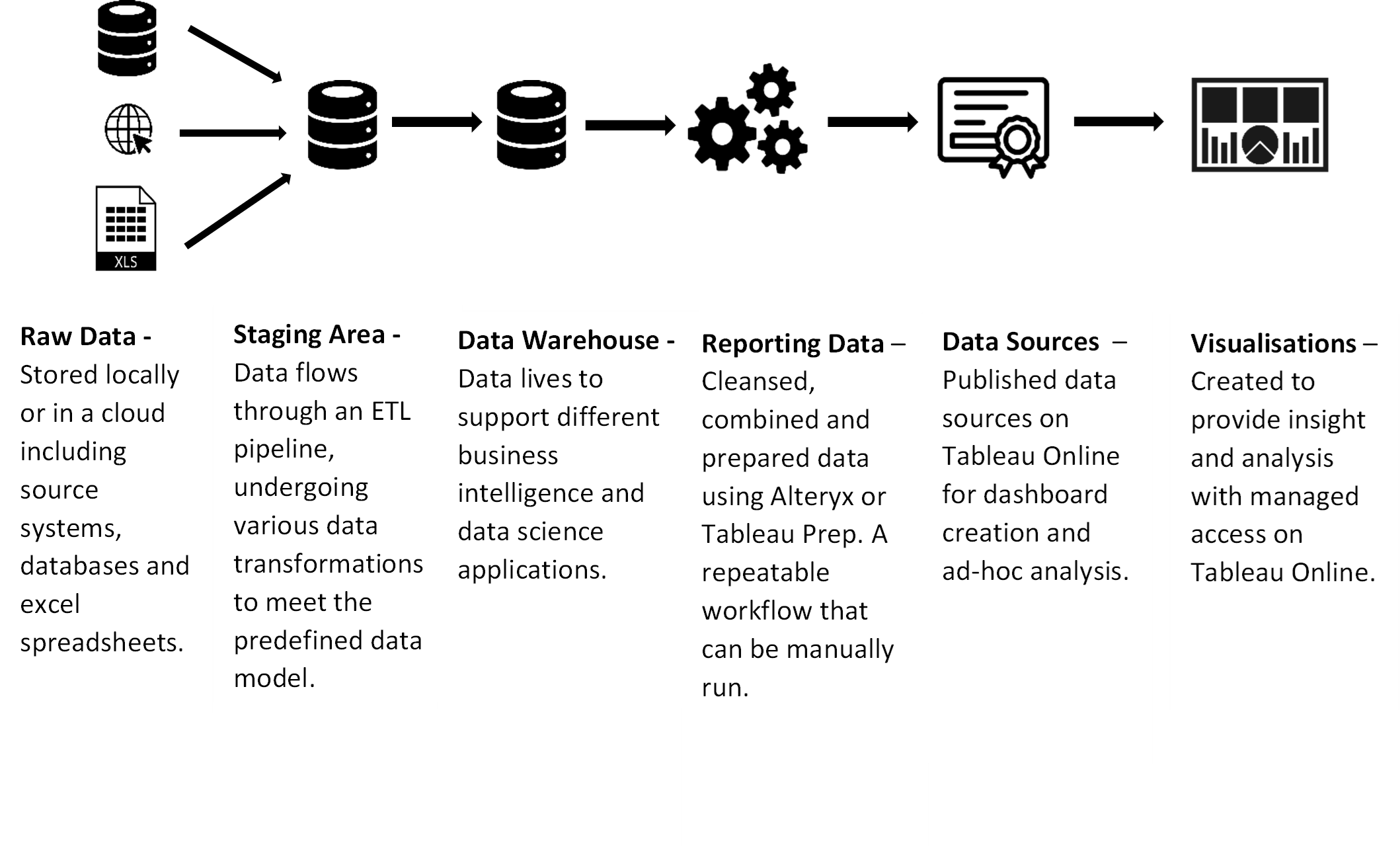
Data warehouses - Aggregates data from different relational data sources across an enterprise into a single, central, consistent repository. The data flows through an extract, transform and load (ETL) pipeline, undergoing various data transformations to meet the predefined data model (data staging). Once it loads into the data warehouse, the data lives to support different business intelligence and data science applications.
Data marts - A focused version of a data warehouse that contains a smaller subset of data important to and needed by a single team or a select group of users within an organization. Since they contain a smaller subset of data, data marts enable a department or business line to discover more-focused insights more quickly than possible when working with broader data warehouses. The more limited scope of data marts makes them easier and faster to implement than centralised data warehouses.
Data Lakes - While data warehouses store processed data, a data lake houses raw data as well. A data lake can store both structured and unstructured data, which makes it unique from other data repositories. This flexibility in storage requirements is particularly useful for allowing access to data for data discovery exercises and machine learning projects. While data lakes are slower than data warehouses, they are also cheaper as there is little to no data preparation before ingestion. Today, they continue to evolve as part of data migration efforts to the cloud. Data lakes support a wide range of use cases because the business goals for the data do not need to be defined at the time of data collection. Machine learning applications benefit from the ability to store structured and unstructured data in the same place, which is not possible using a relational database system. When the application has been developed, and the useful data has been identified, the data can be exported into a data warehouse for operational use, and automation can be used to make the application scale. Data lakes can also be used for data backup and recovery, due to their ability to scale at a low cost. For the same reasons, data lakes are good for storing “just in case” data, for which business needs have not yet been defined. Storing the data now means it will be available later as new initiatives emerge.
Benefits of Data Architectures
Well-constructed data architecture can offer businesses a number of key benefits, including:
Reducing redundancy- There may be overlapping data fields across different sources, resulting in the risk of inconsistency, data inaccuracies, and missed opportunities for data integration. A good data architecture can standardise how data is stored, and potentially reduce duplication, enabling better quality analyses.
Improving data quality– Poorly managed data lakes often lack in appropriate data quality and data governance practices to provide insightful learning. Data architectures can help enforce data governance and data security standards, enabling the proper oversight of the data pipeline to operate as intended. By improving data quality and governance, data architectures can ensure that data is stored in a way that makes it useful now and in the future.
Enabling integration- Today’s data architectures should aim to facilitate data integration across domains so that different geographies and business functions have access to each other’s data. That leads to a better and more consistent understanding of standard metrics. It also enables a more holistic view of customers, products, and geographies, to better inform decision-making.
Data lifecycle management- A modern data architecture can address how data is managed over time. Data typically becomes less useful as it ages and is accessed less frequently. Over time, data can be migrated to cheaper, slower storage types so it remains available for reports and audits, but without the expense of high-performance storage.
Data Architecture Example 1

Data Architecture Example 2