


Introduction
Web scraping is an extremely powerful method for obtaining data that is hosted on the web. In its simplest form, web scraping involves accessing the HTML code (the foundational programming language on which websites are built) of a given website, and parsing that code to extract some data. Tools like Alteryx and R can be used to perform these actions quite easily, by telling them which URL to read the HTML code from, and reformatting the code to output the data of interest.
A common problem that one may encounter when scraping in this way, is when the data of interest is not contained in the HTML code, but is instead published to the website using JavaScript. JavaScript is a higher-level programming language that allows websites to have increased interactivity. In these cases, when you view the HTML code of a website, the data that is published using JavaScript is nowhere to be seen. Take for example a search results page of this property agent website. Let’s say we want to scrape the price information from each house listing on the page.

Have a look through the HTML code from this page and see if you can spot that house price, or any house prices at all for that matter (I’ve removed any instance of the company’s name to preserve anonymity). In fact, none of the information that we can see in the screenshot above appears in the HTML code. A quick and dirty way to determine if JavaScript is involved in generating this content is to disable JS in your web browser, and reload the page (e.g. in Chrome: Settings > Advanced > Content Settings > JavaScript > Disable). When I disable JavaScript for the site in my example, none of my target content appears, so I’m going to assume that JavaScript is at work here.
I’m going to demonstrate a solution that I’ve adapted from a great blog post by Brooke Watson, which uses freeware called PhantomJS to allow us access the code that is pushed by JavaScript. This can be used in R, as Brooke has shown in her post, but since we’re using Alteryx at The Data School, I thought I’d show how it can be utilised in Alteryx.
1. Download PhantomJS
The first step is to download PhantomJS for your OS of choice and stick it somewhere easily accessible – I put it in my Documents folder. The executable file for the software is found in the \bin folder. I’d recommend changing the name of the parent folder to ‘phantomjs’, just so it will be easier to recall the file path later on.
2. Write an input file for PhantomJs
If you open the PhantomJS executable file in the \bin folder, you’ll notice that it looks something like the Command prompt terminal in Windows, or the Mac terminal. So, PhantomJS needs code as an input, to tell it what URL to download the source code from. The code (as adapted from Brooke’s post) is as follows:
var url = 'https://www.xx.co.uk/xx'; var page = new WebPage(); var fs = require('fs'); page.open(url, function (status) { just_wait(); }); function just_wait() { setTimeout(function() { fs.write('website_phantom.html', page.content, 'w'); phantom.exit(); }, 2500); }
Copy this code into a text file, and save it under the name ‘scrape.js’ in the \phantomjs\bin\ folder, where your executable PhantomJS file is.
When read into PhantomJS, the scrape.js file will do the following:
- Get the HTML of the URL you provide it with (in this case ‘https://www.xx.co.uk/xx’)
- Write the HTML and JavaScript code to a file named ‘website_phantom.html’, which will appear in the \phantomjs\bin folder
3. Use Alteryx to update the URL and call PhantomJS
Ideally, we want to have an Alteryx workflow that can dynamically update the website we want to scrape, according to a list of URLs that we feed into Alteryx. For this example, I’ve used a Text Input tool and created a field called ‘website’ with one value that contains the URL of the site that I want to scrape.
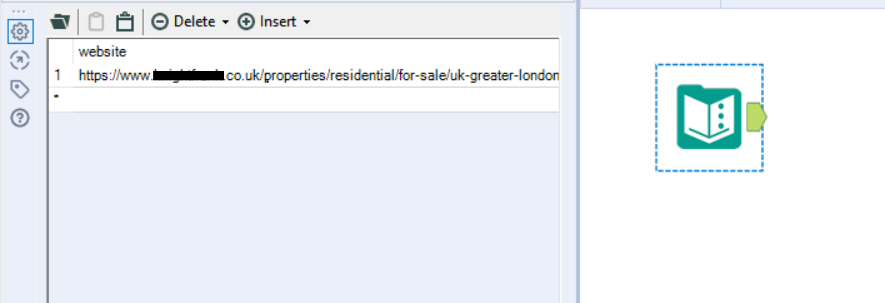
Using another input tool, we can load the scrape.js file we created earlier. Read it in as a .csv file, set the delimiter to ‘\n’ (new line), and deselect the ‘First Row Contains Field Names’ option.

You can see that the first row of our scrape.js file contains a dummy URL that we want to replace with the URL contained in our text input tool. Next we want to do some processing in order to replace the first line of the scrape.js file with our URL from the text input file. There are a number of ways you could approach this, but here’s what I did:
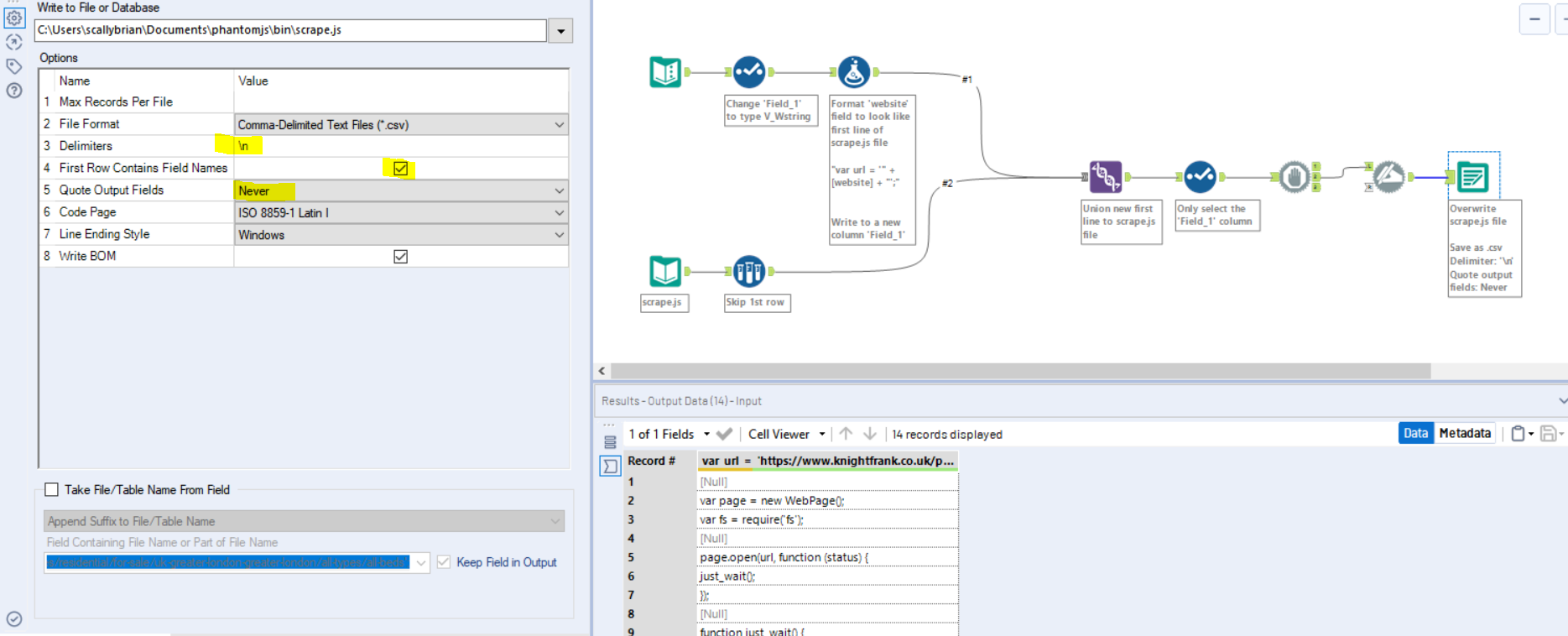
A couple of things to note in the workflow:
- Make sure the field type of the input URL is V_Wstring, so the string length is flexible
- Make sure the Union tool is concatenating the files in the correct order.
- Alteryx might throw up an error when overwriting the scrape.js file. Putting a ‘Block Until Done’ tool before the output, as I have done in this example, should prevent that from happening.
- Since we don’t want to write the field name into the scrape.js file, use the Dynamic Rename tool to ‘Take Field Names from First Row of Data’.
Now our scrape.js file contains our target URL and is ready to be loaded into PhantomJS.
4. Tell PhantomJS to run the scrape.js file
The last step is to run PhantomJS with the scrape.js file as an input. Luckily for us, we can do this easily from inside Alteryx. Alteryx does have a Run Command tool, which on the surface looks like the perfect tool for the job. The only problem is that it doesn’t allow the command arguments to be specified from an incoming tool connection, and so they have to be typed in manually, which I’d like to avoid if we want to keep this process as flexible as possible.
Instead, I’m going to use the R Tool, which is included in the Predictive Tools package that you can add on to Alteryx. Stick the R tool at the end of the workflow after another ‘Block Until Done’ tool, since we want it to run only after the scrape.js file has been updated:

Into the R Tool, paste the following code:
setwd("C:/Users/scallybrian/Documents/phantomjs/bin") js_path = "scrape.js" phantompath = "phantomjs.exe" command = paste(phantompath, js_path, sep = " ") system(command)
A quick run-through what this code does:
- Sets the working directory (setwd) to the location of the PhantomJS executable
- Puts together (paste) the command necessary for running the scrape.js file with PhantomJS.exe
- Uses R’s system() function to run that command, as if it were running it via the cmd terminal
That’s essentially it! PhantomJS will now read the target URL and write the underlying HTML/JavaScript code to a file named ‘website_phantom.html’ in the \phantomjs\bin\ folder.

You can then build your Alteryx workflow to read and parse the HTML file to extract your data of interest.
Hope you find this technique as useful as I did!