


This blog will detail the various steps our data travels through in this example data pipeline and will additionally highlight which steps can be automated using Kestra to simplify and automate our data pipeline from start to finish.
From source to destination, the data in this example will travel through 6 different steps or processes but luckily you will only need to automate 3 steps for the data pipeline to fully execute on it's own.
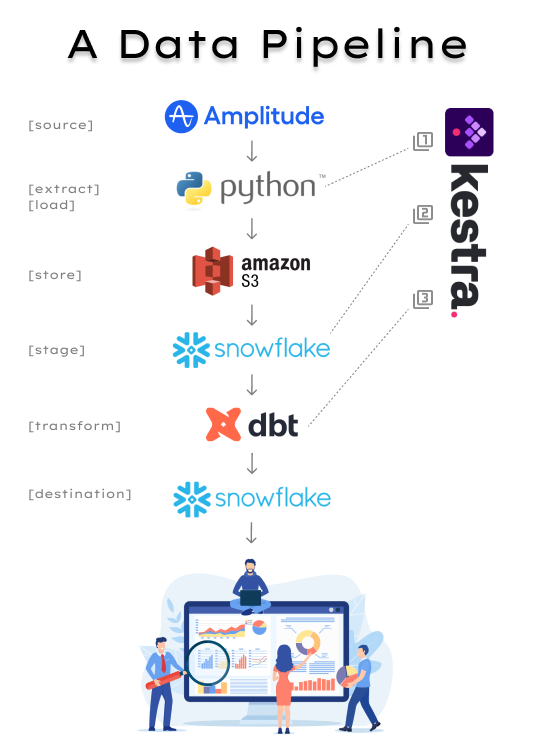
Source
Your source can be anywhere you want to get data from. In this example, we will be using Amplitude as our source and will be using the Amplitude API to get at web events data. You'll likely need API access keys/credentials and possibly additional parameters to get at this data.
Extract & Load
Your tool for extracting this source data can be a product or a script. In this example, we will use a Python script to access the Amplitude API data and upload it to an s3 bucket. An alternative would be to use a product like Airbyte to set up a connection from one product (ie. Amplitude) to another product (ie. S3 or Azure blog storage) for storage.


Orchestration Task 1: Execute Python Script
Store
Your storage layer will be the location where all your raw data (structured and unstructured) lives. Although you do not necessarily need to use a storage layer in order to get your data into a data warehouse, it's recommended for scalability, durability and cost-effectiveness. In this example, we are storing a bunch of JSON files in s3 because it's cheap storage and it also allows us to not be dependent on the warehouse we are using. Snowflake costs could get out of hand if all storage was happening in Snowflake, but in s3 it's cheap and it allows for more flexibility should there be a need to use a different data warehouse.

Stage
Staging your data is considered best practice and will also depend on the data warehouse you're using. In this example, we will use Snowflake where you can either create an internal stage (ie. files stored within Snowflake) or an external stage (ie. files stored outside of Snowflake).
First, create a storage integration which allows users to avoid supplying credentials when creating stages or loading data. Identity and Access Management (IAM) credentials can be found within the AWS interface and can be at the bucket, or policy/role level. Ideally, this is already configured by your IT admin and you won't need to set up a storage integration, you'll only need to reference it in your stage.
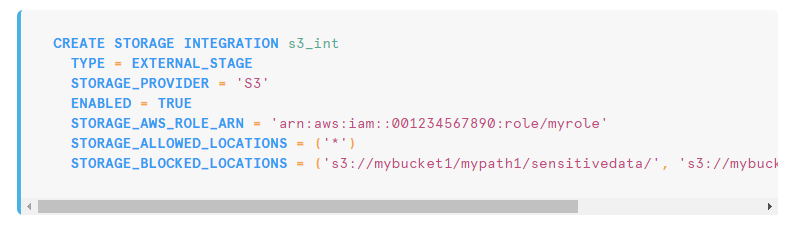
Second, create a stage which acts as the bridge between Snowflake and your storage layer. If you had data living in multiple storage locations (ie. s3, Azure, GCP) then you'd create a stage for each external location. Also note the file_format is defined at the stage level so you may need to consider creating different stages for different file formats.

Third, create a table by using INFER_SCHEMA() on a sample file from your stage that defines the table schema as a template for the rest of the data (with the same format) to be loaded. This table now has a schema/structure but does not have any data in it yet.

Lastly, create a stored procedure that copies files from our external stage and loads them into a table. In this example, we will use a stored procedure for copying data from our stage into our table since we will need to reference the stored procedure in our orchestration task list (Kestra). Otherwise, you can use a "copy into" statement on it's own.

Orchestration Task 2: Run Stored Procedure
Transform
So far, our data has traveled from the Amplitude API into our staging layer in Snowflake. This data is still in its raw unstructured JSON format. In our last step before our data is in a production-ready state (ie living as structured data in a snowflake table), we need to transform our data using a transformation tool such as dbt (Data Build Tool).
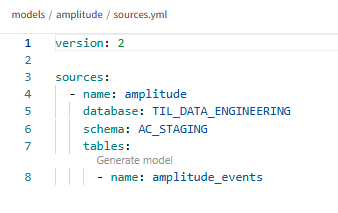
In this dbt example, we will configure our sources.yml to reference the database, schema and table that we just created in Snowflake called amplitude_events:
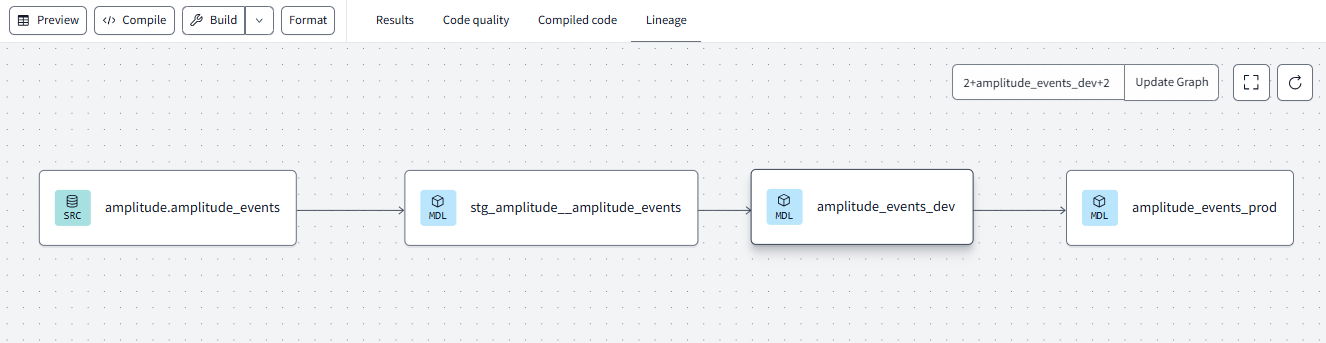
Then, we will create a staging model, intermediary model and a production model. In this example, the staging model will be a simple select statement defining which columns to bring in. To keep it simple, we will only bring in the columns with JSON data that need to be transformed (we can call this the bronze layer).

The intermediary model will be the model where we reference the staging model and use the LATERAL FLATTEN() function on the JSON column to parse out the unstructured JSON data into a more structured format. Also within this intermediary model (this can be broken out into separate models/.sql files if you want) we will perform a PIVOT on the flattened data so that each key is it's own column name (silver layer).

The production model (gold layer) will be the final transformation step before the final >>dbt build. In this example, the production model is simply renaming the column names to be clear and easy to read.
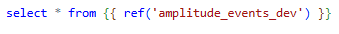
Lastly, you'll need to configure a Job in dbt to automatically run the >>dbt build command to execute your transformation steps. Once the job is configured and runs as expected, you'll need the Job ID for the final orchestration task.
Orchestration Task 3: Trigger dbt Job
Destination
Once your transformation step is complete (in this example, once your dbt job has run successfully), you will now have your production-ready data in clean tables available for querying in Snowflake.
Kestra Orchestration:
From the previous outline of steps, there are 3 that need to be translated into tasks in Kestra that will run in order and on a schedule:
- Execute Python Script - io.kestra.plugin.scripts.python.Commands
- Run Snowflake Stored Procedure - io.kestra.plugin.jdbc.snowflake.Queries
- Run dbt Job - io.kestra.plugin.dbt.cloud.TriggerRun
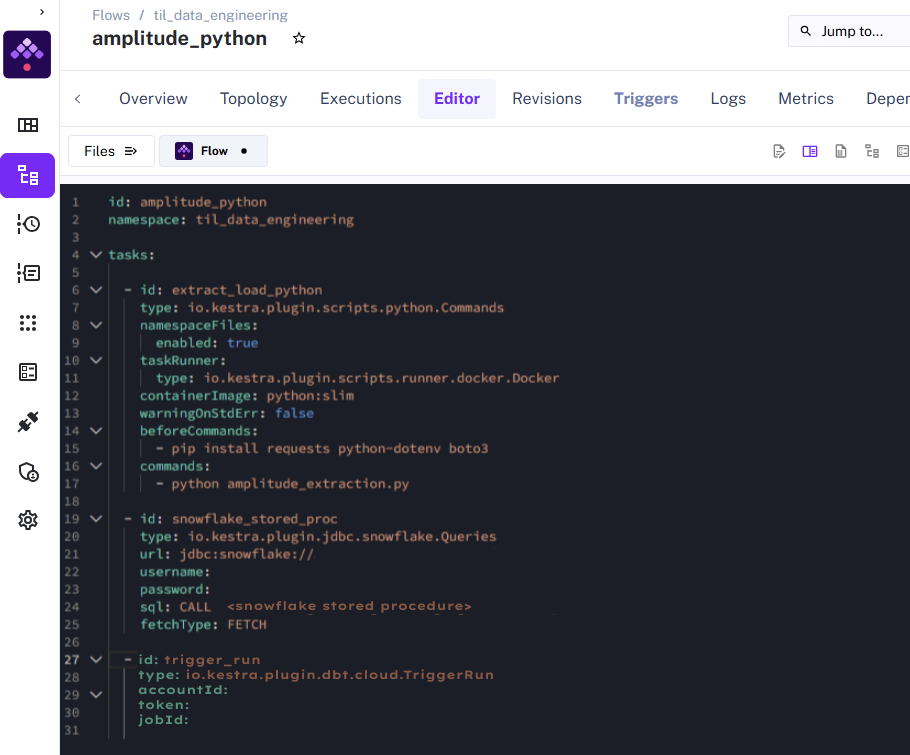
Once configured, execute your Kestra flow and see how long each task takes to run and if there are any errors at any point:

Once complete, this orchestration can be scheduled to run at whatever increment of time and it will result in Amplitude data being extracted, stored, staged, loaded and transformed as outlined in this blog!
If you've made it this far.. congrats! That was a lot.
There are a lot of moving parts but at the end of the day, you really just need to know WHAT things need to be done in your data pipeline and it helps to know WHICH tools can do each of those things. Check out this link for the thousands of tools and categorizations: https://mad.firstmark.com/