


If you have text containing HTML tags, for example as a result of improperly cleaned web scraping, you can remove them manually by editing out each tag. However, this can be automated using a simple regular expression in Alteryx.
An example of raw text with tags is given below.<p>This is some <strong>sample text</strong> containing <a href="https://example.com">HTML tags</a>. The <em>goal</em> here is to remove these tags using regular expressions. Inline <span style="font-weight: bold;">styling</span> can be found, and it's important to clean up the text for better readability.</p>
In Alteryx, we can input this as a single cell using the Text Input tool.
In our flow, we can add the RegEx tool (found under the Parse heading) to the output of our Text Input. The regular expression we want to use is: <.*?>
This identifies substrings beginning and ending with angle brackets, which mark an HTML tag. We don't care what's inside the brackets, so we use the wildcard operator (.) followed by an asterisk to allow as many or as few characters as needed. Finally, the question mark makes the operation non-greedy, meaning it will only look for as few characters as are needed.
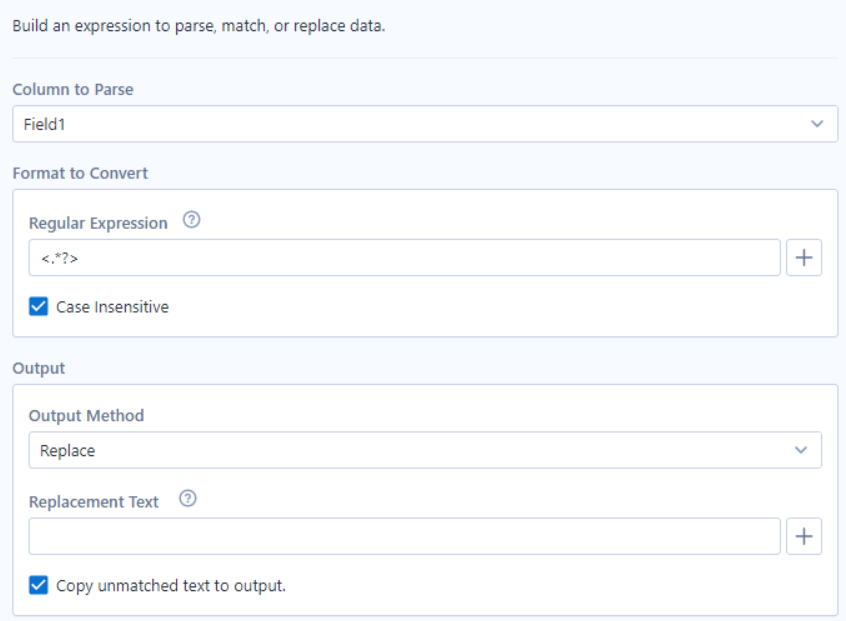
Alteryx lacks a "remove" output method, so instead we use the Replace method, and leave the replacement text blank. We can then run the flow, and receive the output below.
This is some sample text containing HTML tags. The goal here is to remove these tags using regular expressions. Inline styling can be found, and it's important to clean up the text for better readability.