


First day of training with the Data School! 🙌 Here is a snippet of what we learned about modern data architecture.
Data architecture is the design, deployment, and management of data assets and resources within an organization. It includes principles, processes and tools for data handling and storage, as well as data usage and governance.
Modern data architecture is a significant upgrade from traditional data architecture. It provides scalability, speed, accessibility and integration. This enables organisations to unlock the value of their data and extract insights that can inform decisions or drive growth.

A modern data architecture must be able to accommodate changes in data volume, variety, and velocity, as well as support real-time analytics and decision-making. To do this, it must be able to ingest data from a variety of sources (different file types, databases, APIs), prepare it for analysis, store it in a trusted data repository, and provide the necessary tools for analytics.
Data architecture tools enable organizations to design, deploy and manage their data assets and resources. These tools are designed to provide a comprehensive view of an organization’s data, as well as enable data ingestion, storage, and analytics. Some of the most common data architecture tools include ETL (extract, transform, load) tools, data warehouses, analytics tools, data integration tools, and data governance tools. These tools help to extract, transform, and load data from multiple sources, store, and combine data in a trusted data repository, and provide the necessary tools for analytics and decision-making. Additionally, data architecture tools can also provide capabilities for data security, privacy, and compliance, as well as enable agile data management processes.
Data comes in many forms. For example, a bank can have data on user transactions and personal information, spending patterns, product information, fraud data stored in different formats and probably scattered across multiple locations.
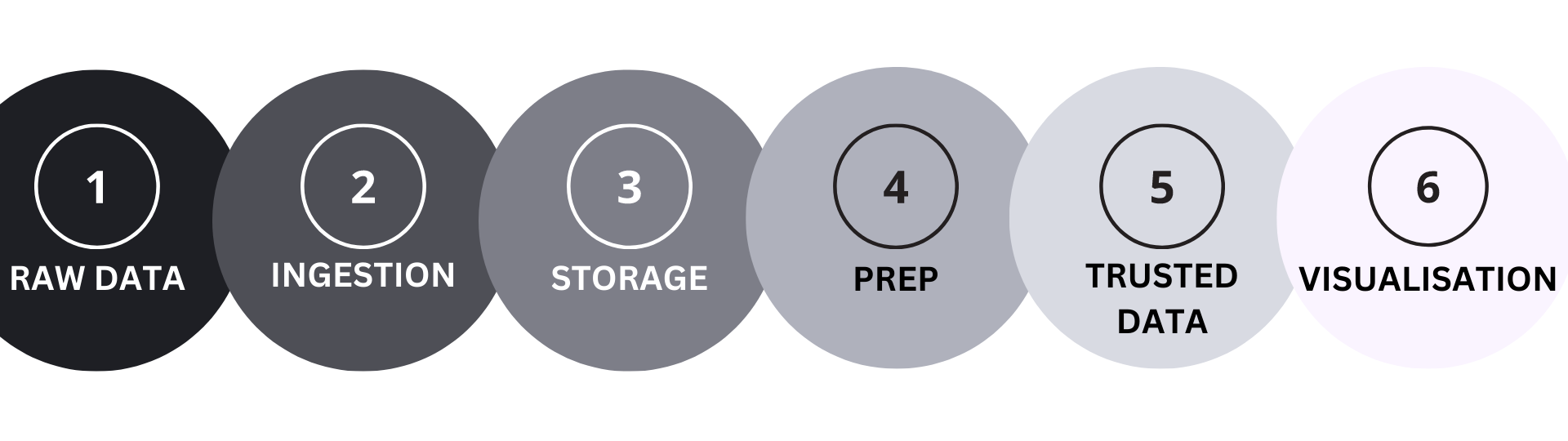
Data ingestion is the process of acquiring data from various sources. Apache NiFi, Talend, and StreamSets are examples of data ingestion tools that can be used to extract, transform, and load data into a centralized repository. Data storage is the next step where large amounts of data are stored for analysis. Data Warehouses such as Amazon Redshift and Snowflake serve as centralized repositories for storing structured data. NoSQL databases such as MongoDB and Cassandra are used to store unstructured data (data lakes). Data preparation involves cleaning, transforming, and organizing the data so it is ready for analysis. Alteryx and Trifacta are popular data preparation tools that provide a user-friendly interface for data wrangling and analysis. Data analysis is the final step where informations is analyzed to extract insights and make informed decisions. Business Intelligence tools such as Tableau, Looker or Cognos can used to perform advanced analytics on the data. Data visualization tools like Tableau are used to present the data in an easily understandable manner through interactive dashboards, charts or infographics.